前几天,笔者刷大模型相关资讯时,注意到了这么一张评测图:
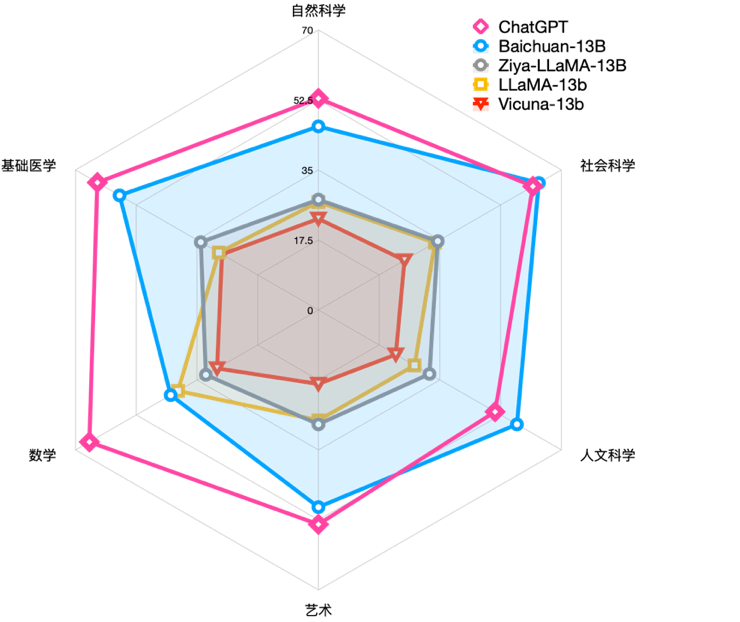
ChatGPT效果要远好于LLaMa等开源模型,这是个公认的事实。但笔者发现,不久前百川智能开源发布的Baichuan-13B模型竟然在中文大模型评测榜单C-EVAL中,性能一骑绝尘,在自然科学、医学、艺术、数学等领域大幅领先LLaMA-13B、Vicuna-13B等同尺寸的大语言模型,在社会科学、人文科学等领域甚至超越了ChatGPT。
这不禁勾起了笔者的好奇心,决定亲自部署评测一下,看下这个Baichuan-13B模型是不是真的有吹得这么牛!
Baichuan-13B项目Github链接:
https://github.com/baichuan-inc/Baichuan-13B
浅试一下,Baichuan-13B模型部署
首先,Baichuan-13B模型分Base版本和Chat版本,前者是预训练阶段完成后的原始模型,由于没有跟人类偏好对齐,虽然不能直接“对话”,但各项任务的精度是最佳状态,适合拿来作为“底座”二次开发;后者则是对齐了人类偏好,可以直接对话的版本,用部分任务的精度来换取了流畅的自由对话。
显然,后者是面向用户的版本,下面我们开始部署Baichuan-13B-Chat。
Hugging Face 开源地址:
预训练模型:
https://huggingface.co/baichuan-inc/Baichuan-13B-Base
对话模型:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
Baichuan-13B-Chat模型推理所需的模型权重、源码、配置已发布在 Hugging Face,因此配置好HuggingFace环境后,部署起来就会非常容易。硬件环境要求也很低,只需要一张24GB显存的3090显卡,就能部署起来这个百亿规模的大模型(INT4或INT8版本)。
完成环境准备后,我们便可以通过以下几行代码完成Baichuan-13B-Chat模型的本地部署和调用了- import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
- from transformers.generation.utils import GenerationConfig
- tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
- model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
- model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
- messages = []
- messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
- response = model.chat(tokenizer, messages)
- print(response)
- 乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上
Baichuan-13B-Chat评测
为了给大家直观的体现对比结果,笔者从13个维度出发设置题目,将Baichuan-13B-Chat与ChatGLM2-6B进行GSB评比,来全面考察模型的基础语言理解、复杂指令理解、基础文本生成、复杂内容生成、常识推理、数学推理、事实推理、中国文学知识、跨语言能力和代码能力等。
设置的题目包括: 1、古文/成语理解 2、文章写作 3、事实性问答 4、多语言能力 5、代码能力 6、创意能力 7、中文理解 8、生活常识 9、角色扮演 10、多轮对话+常识
Round1: 古文/成语理解
题目1
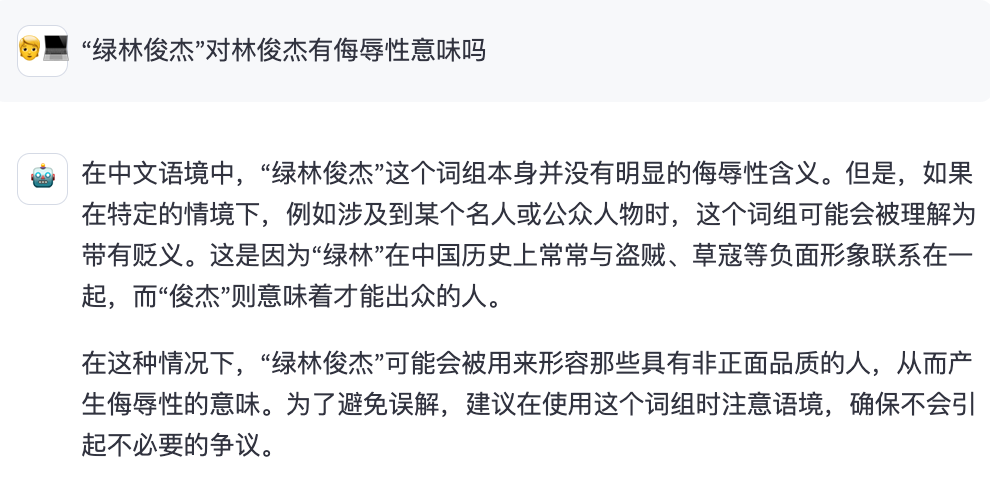
题目2
 Round2: 文章写作 Round2: 文章写作
题目1
写作方面太强了,能把这么多维度一个不落的写完整的大模型,亲测不多。
 题目3 题目3
 题目4 题目4
写专业论文也不在话下,可以说在写作方面,百川模型的实力完全不在ChatGPT之下。
题目一
题目二
题目二太难了,到目前还没有哪个大模型正确回答的。只要不是太难的事实性问答,百川的回答还是蛮精准的!
题目一
题目二
 强,本以为是个中英模型,没想到法语、西班牙语、日语这些小语种也精通了。。。
亲测写基础的代码无压力,但寻找隐晦的bug不太行,这块还得是GPT-4
不错不错,准备去注册了
Round7: 中文理解
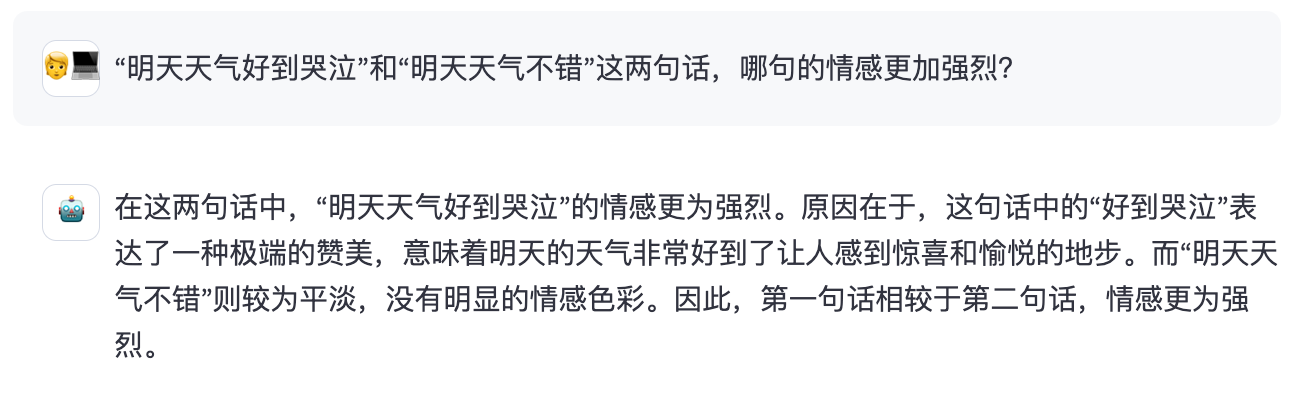 Round8: 生活常识 Round8: 生活常识
题目一:

题目二:

题目三:
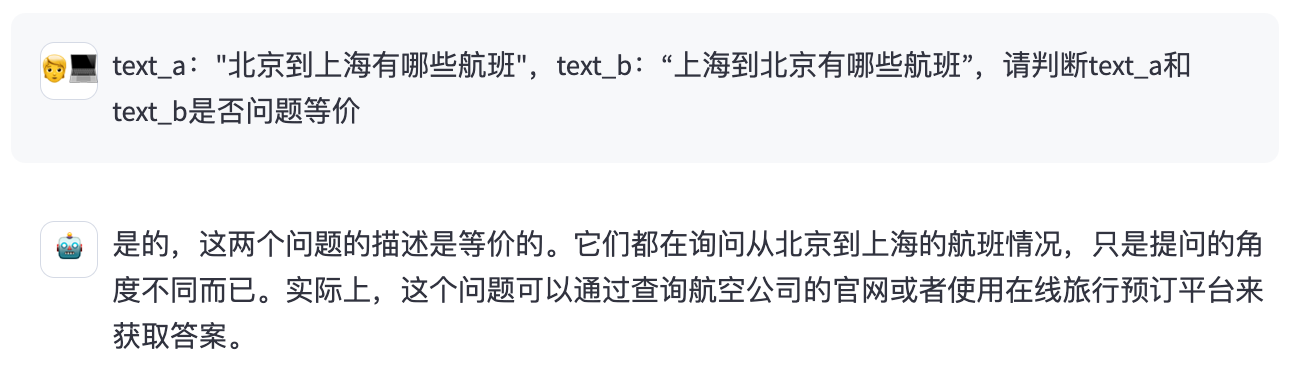 只要别像题目三那样难为它,百川在生活方面还是非常懂的!
这个问题,到目前为止只有GPT-4能应对,百川也没搞定,情有可原
题目一:
题目二:
 嘤嘤怪是完全拿捏了。。。但亲测别让他扮演费脑子的角色
整体上百川新开源的130亿大模型非常强,尤其是写作能力上,非常优秀。从笔者评测过的其他开源模型来说,baichuan-13B毫无疑问是当下开源大模型里面表现最优秀的,包括差不多同期开源的ChatGLM2-6B(虽然参数量不对等)。在中文任务上,Baichuan-13B不仅仅是榜单上的开源最强者,从实际体验上来说,它也确实做到了表现最强。
不过如果加上闭源的模型的话,笔者亲测Baichuan-13B跟GPT-4、Claude2、ChatGPT还是存在一定的差距,但在中文写作方面,Baichuan-13B要优于ChatGPT,跟GPT-4表现非常接近了。考虑到本身Baichuan-13B也只是个百亿模型,打不过ChatGPT这类千亿、万亿规模的模型,也是情理之中的。感知下来,Baichuan-13B的短板也有,主要体现在代码和数学计算方面。
另外,笔者不由得感叹一句,百川这次选的模型规模13B其实非常精妙,这个模型规模不大不小,在一张3090显卡上就能跑的动,不需要昂贵的显卡和多卡推理。效果层面,这个模型规模又足够大,能在很多产业级的任务上达到非常不错的私有化部署的效果。从成本和数据安全的角度来说,Baichuan-13B绝对是当下国内企业私有化部署的不二选择了。
总之,在OpenAI和谷歌都选择闭源保证自家大模型优势地位的情况下,百川能以最快的速度交出这样的一份答卷,并且还选择了开源自家大模型,这种精神是非常值得赞赏的。Baichuan-13B模型的开源,对AI开源社区乃至整个行业的推动作用都是巨大的。
笔者相信,以百川大模型为代表的开源力量,势必会逐渐追平甚至超越闭源模型,对大模型的格局产生有力的冲击力。 |



