今天谈谈AI的另一种实现方案:以数据为中心的AI(Data-Centric AI)不同于以模型为中心的AI(Model-Centric AI),对于优化AI的泛化能力采用的是数据集的优化,而不是模型的优化(如CNN、Transformer、Bert、GPT等)。在工业界显示,采用数据驱动来优化AI往往比模型更有效,提升更大。如下:
通过数据增强清洗等模型性能的提升,图片来自吴恩达公开课
Data-Centric AI
以数据为中心的AI就明显突出了数据的重要性而非模型,做数据也就成为了关键,通过各种方法系统性的删除一些噪音数据,修正一些错误标注数据,做数据集的扩充等等就尤为关键,而承担这一工作的角色称为Machine Learning Operators(MLOps),投票显示这一岗位更适合的人群为数据科学家或者领域专家。
算法工程师或者领域专家更适合作为MlOps
以下是Data-centric AI的key point
个人对AI的理解为:AI system = data(train、dev、test 70%)+ model(CNN、RNN、Bert、GPT 20%)+ trick(10% loss、warmup、optimizer、attack-training etc),数据决定了AI模型的上限,模型和trick只是去逼近这个上线,记住:garbage in, garbage out。
Data Clue
接下来给大家分享一个以Data-centric AI为指导思想的论文:
DataClue:A Benchmark Suite for Data-centric NLP
数据集构建
由于是以数据为中心,首先构造一个有挑战性的数据集就很重要了,作者徐亮以文本分类任务为依托,对数据进行一些特殊处理,使得train-dev的精度在70%左右,test集合保持为ground truth(95%+ acc)。
分类任务数据集
or CIC more than 1/3 and 1/5 of the data in the training set and validation set may have the problem of labeling errors. Meanwhile, the dataset is seriously unbalanced, making it more difficult to learn a good model.
通过random或者top5 select打乱label,构造训练集噪声
一些难以区分的badcase
做数据,基本也就是增删改操作了,通过这些操作不停的提高训练集的质与量。作者采用了所有的方式做数据,并进行了各种实验以及结果分析。
噪声标签删除
交叉验证训练多个模型,根据熵判断最有可能错误的。
删除熵最大的脏数据
数据标签修改
交叉验证训练多个模型,取模型预测结果一致且prob比threshold大的数据。(或者top2000)。多个模型可以采用不同的seed,不同的训练集测试机,或者不同的模型结果(bert与textcnn等)。
- human_resource check:
- 1、random_select (策略基本无效,验证了该任务的难度有效性)
- 2、selected by prob distribute (策略有一点效果)
数据增强(data-aug)
- 同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
- 随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
- 随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
- 随机删除(Random Deletion, RD):以 $p$ 的概率,随机的移除句中的每个单词;
- 值得一提的是,长句子相对于短句子,存在一个特性:长句比短句有更多的单词,因此长句在保持原有的类别标签的情况下,能吸收更多的噪声。
生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合;
使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词;
2. 为什么使用EDA而不使用语境增强、噪声、GAN和反向翻译?
由于需要一个深度学习模型,这些技术往往在其取得的效果面前,付出的实现代价更高。而EDA的目标在于,使用简单方便的技术就能取得相接近的结果。
3. EDA是否有可能会降低模型的性能?
确实有可能。原因在于,EDA有可能在增强的过程中,改变了句子的意思,但其仍保留原始的类别标签,从而产生了标签错误的句子。
对于同义词替换部分,模型认为的相似的词(embedding的向量接近)与人类社会认为的同义词可能不太一样。

我们通常认为的“反义词”,从客观上来看,它们都算是比较相似的词,比如“喜欢”和“讨厌”,它们的共性多了去了:都是动词,都是描述情感倾向,用法也差不多,所以我们怎么能说这两个词“毫不相似”甚至“相反”?我们说它是反义词,是指它在某一个极小的维度下是对立关系,要注意,只是某个维度,不是全部。 ——
定义增强(definition_aug)
定义增强是吸收了标签定义的信息增益
能做def_aug是因为标签即知识,对于那种给一个ID的标签不可行,比如情感识别的label只给出01,即label提供不了任何信息的时候该方法是很难适用的。
Input为训练集测试集,output为新的训练集测试集
结果分析
删除脏数据增益,先增后减(数据删除多了信息自然会丢失)
数据增强增益,同样增强太多会引入噪声
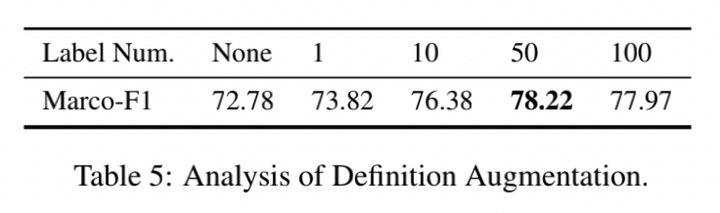
定义增强增益
需要控制EDA数量, signal-to-noise ratio信噪比别太小,triple比较合适
对于Def_aug,The use of augmentation here also has a similar phenomenon to the previous one, that is, too much data augmentation is meaningless. According to our experiment, a 50-fold augmentation is an optimal choice.
we find that the label augmentation and the data augmentation methods looks incompatible. This may due to the over-augmentation creates too much noise.

参考资料:
Paper:DataCLUE: A Benchmark Suite for Data-centric NLP https://arxiv.org/pdf/2111.08647.pdf
DataCLUE: 数据为中心的NLP基准与工具包
https://github.com/CLUEbenchmark/DataCLUE
吴恩达新课:从以模型为中心到以数据为中心的AI哔哩哔哩bilibili
CLUE中文语言理解基准测评
cleanlab:GitHub - cleanlab/cleanlab: The standard data-centric AI package for data quality and machine learning with messy, real-world data and labels
eda_nlp: GitHub - jasonwei20/eda_nlp: Data augmentation for NLP, presented at EMNLP 2019
Synonyms: Chatopera/Synonyms
EDA_NLP_for_Chinese: GitHub - zhanlaoban/EDA_NLP_for_Chinese: An implement of the paper of EDA for Chinese corpus.中文语料的EDA数据增强工具。NLP数据增强。论文阅读笔记。 |



