什么是NLP
NLP定义
自然语言处理(英语:Natural Language Processing,缩写作 NLP)是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。
by 「维基百科」
维基百科也没有给出很详细的定义,只说了是分支学科,而在我浅薄的理解中,NLP,就是让机器理解自然语言(也就是人类的文化载体——文字),然后让机器处理,运用人类语言。
根据维基百科的简介,NLP的起源和机器翻译有着密切关系。但是由于机器翻译一直很难有很大的突破,所以NLP也一直没有很好的起色,直到上世纪六七十年代,出现了聊天机器人。而这一切都是根据规则写的,技术含量呢,没有那么高,对语言的理解也没那么透彻(不过某宇告诉我,工业界百分之八十的NLP都是用的规则,我持怀疑态度)。直到九十年代,出现了机器学习,NLP也就蜕变了。有了像引入HMM(隐马尔科夫模型)的词性标注这样的统计模型。再后来,深度学习出现了,也就有了现在的Deep NLP的概念,多了语言模型、语法分析等等新的模型。
现在NLP应用广泛,例如搜索引擎逐渐成为人们获取信息的重要工具,涌现出以百度、谷歌等为代表的搜索引擎巨头;机器翻译也从实验室走入寻常百姓家,谷歌、百度等公司都提供了基于海量网络数据的机器翻译和辅助翻译工具;基于自然语言处理的中文(输入法如搜狗、微软、谷歌等输入法)成为计算机用户的必备工具;带有语音识别的计算机和手机也正大行其道,协助用户更有效地工作学习。
2.
NLP中的表示方法
既然要让机器理解自然语言,首先我们需要转化成机器能看懂的东西——数字矩阵。目前,NLP中的表示方法一共有两大类,独热表示和分布式表示。
2.1
- 独热表示 -
独热表示就是我们常见的One-hot Representation,也是我接触的第一种表示方法,不只是NLP中会用到One-hot,在其他机器学习领域也会用到。这种方法简单来说就是生成一个类别数长度的向量,这个向量中除了一个维度是1以外,其他维度都为0,而这个维度就代表这个类别,在NLP中,也就代表一个字或者词。
举例说明
句子:我是帅哥。
我:[1,0,0,0]
是:[0,1,0,0]
帅哥:[0,0,1,0]
。:[0,0,0,1]
这种编码的好处是:简单明了。应用词袋模型(BOW)+ TF-IDF技术,再加上LR算法,效果也能看得过去。
缺点也是很明显:
1、随着类别数增多(字词的增多),容易造成维数灾难;
2、词与词之间没有明显的联系,存在语义鸿沟。
正是由于这些原因,1986年Hinton提出了分布式表示(Distributional Representation)。
2.2
- 分布式表示 -
到目前为止,基于分布假说的词表示方法,根据建模的不同,主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。说是三种方法,宏观角度来说,其实做的操作都是一样的:
1. 选择一种方式描述上下文;
2. 选择一种模型刻画某个词与其上下文之间的关系
基于矩阵的分布表示
这种方法其实我平常使用的也不多,但是这是根据分布式表达产生的第一种表达方式,它的核心思想紧贴分布式表达:构建“词—上下文”的共现矩阵,每行对应一个词,每列表示一种不同的上下文,矩阵中的每个元素对应相关词和上下文的共现次数。
“词—上下文”的形式一共有三种:1. “词—文档”的形式;2. “词—词”的形式;3. “词—n元组”的形式。
目前斯坦福大学公布了一种基于“词—词”的方法 —— GloVe。我们就以这个模型谈谈基于矩阵的分布表示。
- 模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息。
- 输入:语料库
- 输出:词向量
- 方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
构建共现矩阵
矩阵中的每一个元素 Xij 代表单词 i 和上下文单词 j 在特定大小的上下文窗口(context window)内共同出现的次数。
举例说明
I love you and I also love her
这句话一共5个单词,分别是I,love,you,and,also,her。
如果我们采用一个窗口宽度为5(左右长度都为2)的统计窗口,那么就有以下窗口内容:
窗口标号中心词窗口内容
0 I I love you
1 love I love you and
2 you I love you and I
3 and love you and I also
4 I you and I also love
5 also and I also love her
6 love I also love her
7 her also love her
窗口0、1长度小于5是因为中心词左侧内容少于2个,同理窗口6、7长度也小于5。
以窗口4为例构建共现矩阵:
中心词是I,语境词是you,and,also,love,所以:
XI,you += 1
XI,and += 1
XI,also += 1
XI,love += 1
仿照这种方法,遍历所有窗口,即可得到共现矩阵X。
训练词向量

根据损失函数,训练模型,其中vi,vj 是单词 i 和单词 j 的词向量,bi,bj是两个标量(作者定义的偏差项),f(x)是权重函数,N是词汇表的大小(共现矩阵维度为N∗N)。
具体权重函数应该是怎么样的呢?
首先应该是非减的,其次当词频过高时,权重不应过分增大,作者通过实验确定权重函数为:

emmmmmmm,这样看起来GloVe模型像是个无监督学习,因为并不需要人工打标。其实呢,非也非也,它是有label的,它的label就是log(Xi,j),而vi,vj 就是要不断更新/学习的参数,所以本质上它的训练方式跟监督学习的训练方法没什么不一样,都是基于梯度下降的。
以上就是GloVe模型,介绍得很糙,需要具体实现这里看:https://github.com/stanfordnlp/GloVe
基于聚类的分布表示
该方法以根据两个词的公共类别判断这两个词的语义相似度。最经典的方法是布朗聚类(Brown clustering)。
布朗聚类是一种基于二元文法模型(bigram)的层次聚类方法,目的在于最大化二元文法模型的互信息。它是一种硬聚类,每个词都在且仅在唯一一个类中。
输入:语料库中的词序列,输出:二叉树,二叉树的叶子结点是一个个词,中间节点即为我们想要的类。
缺点:只基于二元文法统计。
基于神经网络的分布表示
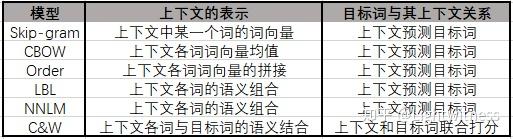
神经网络的模型有很多,我也只是略知一二,所以我只说说里面我知道的Skip-gram和CBOW模型。
这两个模型在NLP届可谓是大名鼎鼎,而word2vec是实现这两个模型的工具。(其实刚开始接触词向量时,我搞不清楚这三者之间的关系,所以我希望我能把它说清楚)
Skip-gram和CBOW两个模型,在我看来,是比较相似的。CBOW通过上下文预测中心词概率,而Skip-gram模型则通过中心词预测上下文的概率。举个例子,CBOW就是“OOXOO”,用“O”猜“X”;而Skip-gram恰恰相反,是用“X”猜“O”。
这里我引用一个从网上找来的例子:
以“我爱北京天安门”这句话为例。假设我们现在关注的词是“爱”,C=2时它的上下文分别是“我”,“北京天安门”。CBOW模型就是把“我” “北京天安门” 的one hot表示方式作为输入,也就是C个1xV的向量,分别跟同一个VxN的大小的系数矩阵W1相乘得到C个1xN的隐藏层hidden layer,然后C个取平均所以只算一个隐藏层。这个过程也被称为线性激活函数(这也算激活函数?分明就是没有激活函数了)。然后再跟另一个NxV大小的系数矩阵W2相乘得到1xV的输出层,这个输出层每个元素代表的就是词库里每个词的事后概率。输出层需要跟ground truth也就是“爱”的one hot形式做比较计算loss。这里需要注意的就是V通常是一个很大的数比如几百万,计算起来相当费时间,除了“爱”那个位置的元素肯定要算在loss里面,word2vec就用基于huffman编码的Hierarchical softmax筛选掉了一部分不可能的词,然后又用nagetive samping再去掉了一些负样本的词所以时间复杂度就从O(V)变成了O(logV)。Skip gram训练过程类似,只不过输入输出刚好相反。
3.
总结
这篇写得太长了,并且拖得太久了,可能写了一个月,哈哈哈,唉,好久没写,太颓废,以后应该会经常写吧。最后呢,说说我对NLP的理解,我觉得自然语言处理和普通的数据挖掘问题差异在于自然语言的表达,普通的数据挖掘问题特征都是数字或者属性,但是NLP中这些东西都是自己来定的,并且你要让机器更好的理解这句话的意思,这也是一个难点。
(吐槽:微信公众号转知乎格式真是太难受了)
以上,就是NLP系列的第一篇了。撒花~~~~~ |



