如果是刚刚开始学习复现一些算法,当然从基础的方向和算法开始吧,因为这些算法都是实现更复杂网络的“砖”,这些“砖”包括CNN,Word Embeeding、LSTM、Seq2Seq+Attention、Language Model。从去年开始大火的Transformer、BERT中我们又看到了self-Attention,ResNet,Position enocding等更多细微的组件。所以建议从最简单的深度学习任务一步一步来。
- 此项目复现了斯坦福cs224n中经典算法应用框架Pytorch:
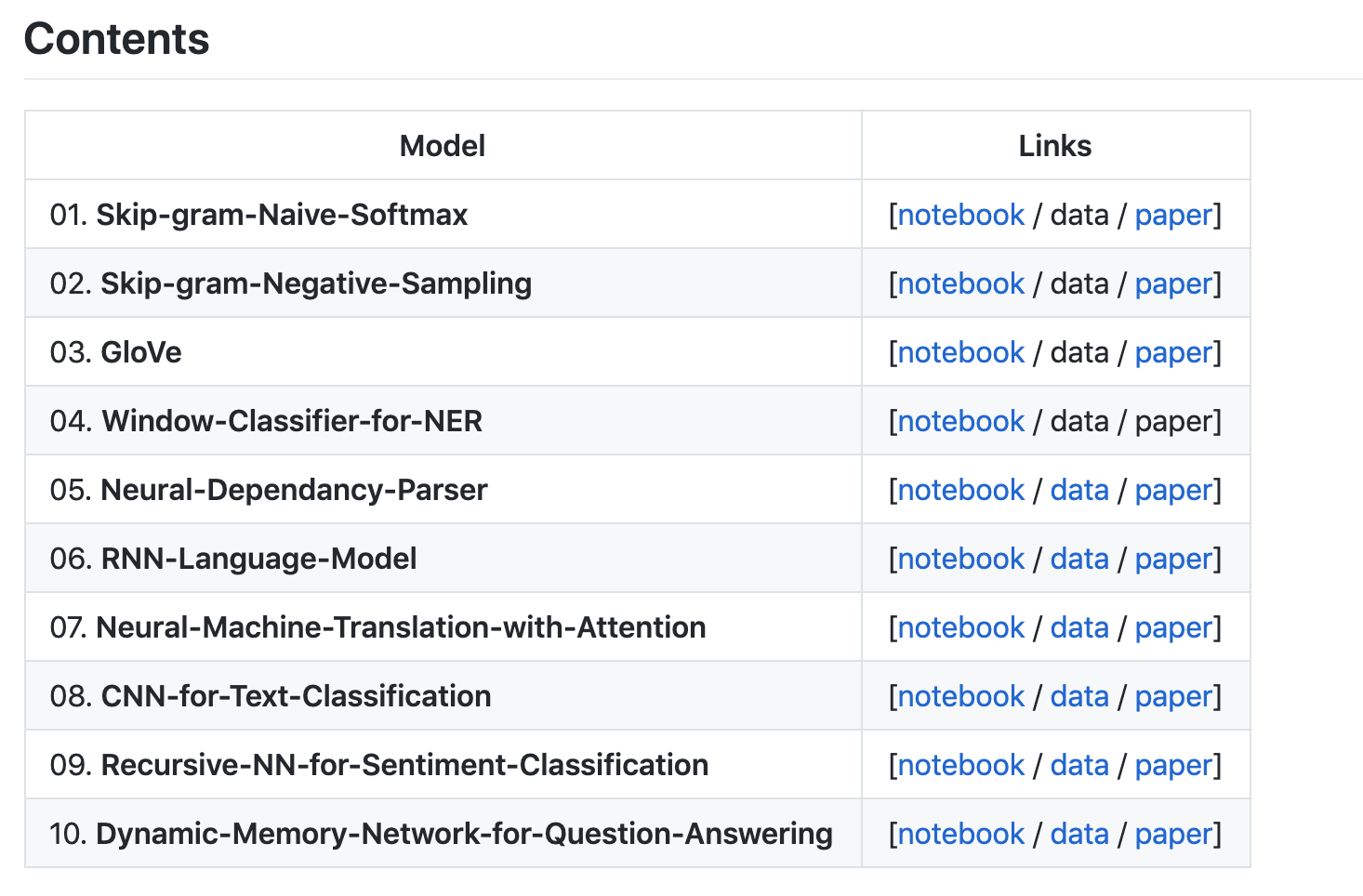
DSKSD/DeepNLP-models-Pytorch
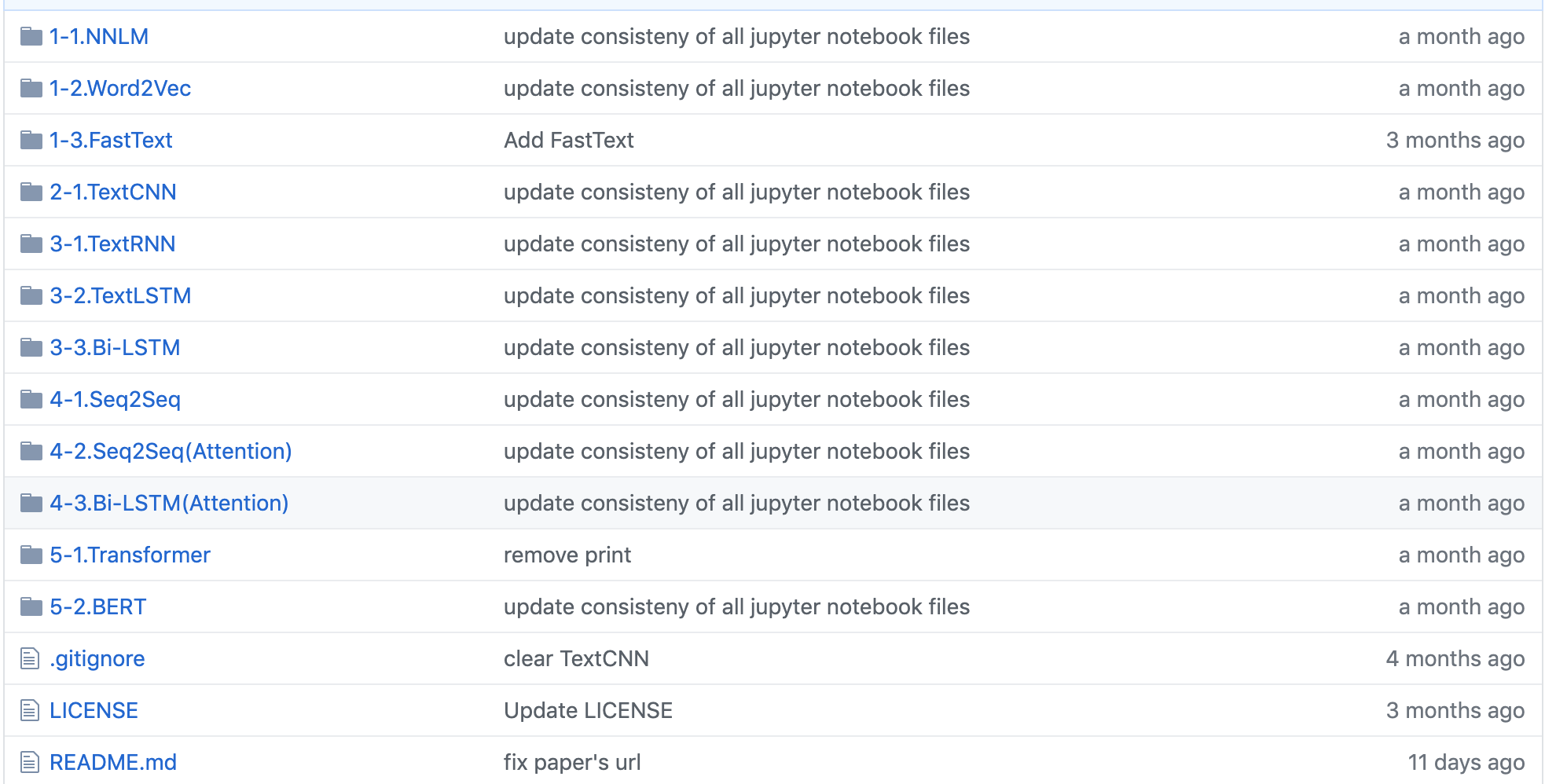
2.NLP_tutorial应用框架pytorch和tensorflow:
https://github.com/graykode/nlp-tutorial
PS:最近一直反思自己以前的学习方法,得出的结论是:书上、论文上看到的算法都不叫做学到,用代码实现了的才叫你真正的学会了。加油! |





