介绍
计算机视觉中的语义分割是一个正在快速发展的领域。
它涉及将图像划分为有意义的部分并将每个部分分类为预定义类之一的过程。本文将探讨语义分割在计算机视觉领域的重要性、技术、应用、挑战和未来前景。

语义分割的意义
语义分割在计算机视觉中起着至关重要的作用,它使机器能够在粒度级别上理解和解释图像的内容。
与识别和定位图像中对象的对象检测不同,语义分割通过在像素级别分割图像而走得更远。这种精度允许更详细、更全面地了解场景,这在自动驾驶、医学成像和环境监测等应用中至关重要。
技术和算法
语义分割技术的发展与深度学习的进步密切相关。卷积神经网络(CNN)一直是该领域的基石。全卷积网络 (FCN) 等早期方法表明,CNN 可以适用于像素级分类。
紧随其后的是更复杂的架构,如专为医学图像分割而设计的 U-Net,以及 DeepLab,它结合了卷积和完全连接的 CRF,以实现更精确的分割。
在各个领域的应用
语义分割已在众多领域得到应用。
- 在自动驾驶汽车中,它有助于理解道路场景,包括识别车道、行人和其他车辆。
- 在医疗保健领域,它有助于对医学扫描进行精确分析,从而实现更好的诊断和治疗计划。
- 在农业中,它可用于作物分析和监测。
- 在城市规划和环境监测中,语义分割有助于分析卫星和航空影像,以进行土地利用分类和变化检测。
挑战和局限性
尽管取得了进步,但语义分割仍面临一些挑战。
一个主要挑战是需要大型注释数据集来训练深度学习模型。在像素级别注释图像既费时又费力。另一个挑战是在真实场景中处理不同的照明条件、遮挡和不同的背景。此外,模型在不同领域的泛化依旧是一个重大障碍。
发展方向
语义分割的未来与人工智能和深度学习的持续发展息息相关。目前正在探索迁移学习和半监督学习方法,以解决数据稀缺问题。
语义分割与其他计算机视觉任务(如对象检测和深度估计)的集成也是一个活跃的研究领域。
此外,GPU 和 TPU 等硬件的进步正在实现更快、更高效的处理,为实时应用开辟了新的可能性。
代码
创建用于语义分割的完整 Python 代码涉及几个步骤:安装库、加载数据集、定义模型、训练和可视化结果。为了简单易用,我们将使用 TensorFlow 及其高级 Keras API,以及像 CIFAR10 这样的标准数据集。
步骤1:安装必要的库
首先,确保已安装 TensorFlow。您可以通过 pip 安装它:
pip install tensorflow
步骤 2:加载和准备数据集
CIFAR10 是一个包含 10 个类的 60,000 张 32x32 彩色图像的数据集。为了简单,我们将在接下来的实验使用这一数据集,尽管它不是用于语义分割的典型数据集。
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
# Load the dataset
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize pixel values
train_images, test_images = train_images / 255.0, test_images / 255.0
# Convert labels to one-hot encoded
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
步骤 3:定义语义分割模型
我们将为此任务定义一个简单的 CNN。在实际场景中,您将使用更复杂的架构,例如 U-Net 或 DeepLab。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, UpSampling2D, Flatten, Dense
def create_model():
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
UpSampling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax') # 10 classes in CIFAR10
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
model = create_model()
步骤 4:训练模型
根据CIFAR10数据训练模型。
历史 = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
第 5 步:可视化结果
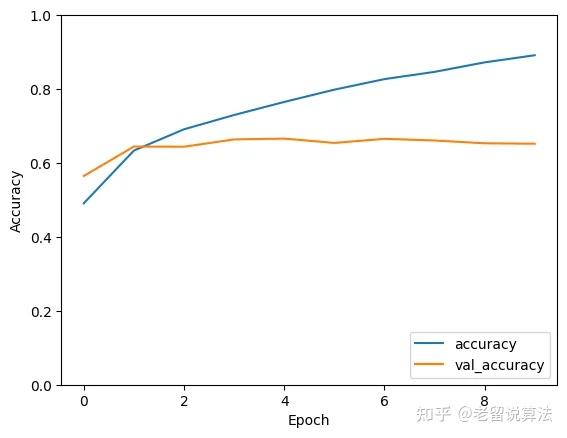
绘制训练历史记录。
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
Epoch 1/10
1563/1563 [==============================] - 226s 144ms/step - loss: 1.4284 - accuracy: 0.4909 - val_loss: 1.2385 - val_accuracy: 0.5648
Epoch 2/10
1563/1563 [==============================] - 159s 102ms/step - loss: 1.0429 - accuracy: 0.6336 - val_loss: 1.0144 - val_accuracy: 0.6444
Epoch 3/10
1563/1563 [==============================] - 133s 85ms/step - loss: 0.8852 - accuracy: 0.6911 - val_loss: 1.0305 - val_accuracy: 0.6440
Epoch 4/10
1563/1563 [==============================] - 135s 86ms/step - loss: 0.7708 - accuracy: 0.7298 - val_loss: 1.0021 - val_accuracy: 0.6637
Epoch 5/10
1563/1563 [==============================] - 129s 83ms/step - loss: 0.6701 - accuracy: 0.7651 - val_loss: 1.0023 - val_accuracy: 0.6659
Epoch 6/10
1563/1563 [==============================] - 128s 82ms/step - loss: 0.5778 - accuracy: 0.7983 - val_loss: 1.1584 - val_accuracy: 0.6542
Epoch 7/10
1563/1563 [==============================] - 129s 83ms/step - loss: 0.4965 - accuracy: 0.8269 - val_loss: 1.1701 - val_accuracy: 0.6653
Epoch 8/10
1563/1563 [==============================] - 132s 85ms/step - loss: 0.4357 - accuracy: 0.8465 - val_loss: 1.2827 - val_accuracy: 0.6608
Epoch 9/10
1563/1563 [==============================] - 128s 82ms/step - loss: 0.3665 - accuracy: 0.8721 - val_loss: 1.3547 - val_accuracy: 0.6532
Epoch 10/10
1563/1563 [==============================] - 134s 86ms/step - loss: 0.3098 - accuracy: 0.8915 - val_loss: 1.5152 - val_accuracy: 0.6520
注意事项
- 此代码是一个基本演示,由于 CIFAR10 数据集的性质,它使用分类模型,而不是真正的语义分割模型。
- 在实际的语义分割任务中,图像中的每个像素都被分类,通常需要更复杂的模型和数据集专门注释用于分割(如PASCAL VOC或MS COCO)。
- 对于真正的语义分割任务,请考虑使用 U-Net、FCN 或 DeepLab 等架构,以及图像中每个像素都具有相应类标签的数据集。
- 提供的代码是出于教育目的而简化的,可能需要针对实际和更复杂的实际应用进行调整。
结论
语义分割是计算机视觉的关键组成部分,可对图像进行详细且上下文丰富的分析。
它在各行各业中的应用证明了它的多功能性和潜力。
尽管面临挑战,但正在进行的研究和技术进步有望克服这些障碍,使语义分割成为计算机视觉技术库中更强大的工具。
随着该领域的不断发展,它无疑将解锁新的能力和应用,进一步弥合人类和机器视觉之间的差距。
参考文章:
https://medium.com/ai-in-plain-english/exploring-the-fundamentals-and-applications-of-semantic-segmentation-in-computer-vision-a72d3dc93d6c |



