看到一堆回答吹DeepMind实在有点崩不住,同为AI+材料计算的科研人员,分享一下我的看法,最后也会分享下领英圈内科研大佬们的看法.
先说结论:这篇文章大概是npj computational materials(计算材料领域顶刊)的水平,最多可以勉强够得上Nature Communications,没有什么创新点或者新的内容,唯一的亮点就是弄了个很大的材料数据集(但是这个亮点也充满槽点,等下再说)。能发Nature全靠的是Google DeepMind这块招牌。我稍后会解释为什么这种堆数据量和算力没什么意义。
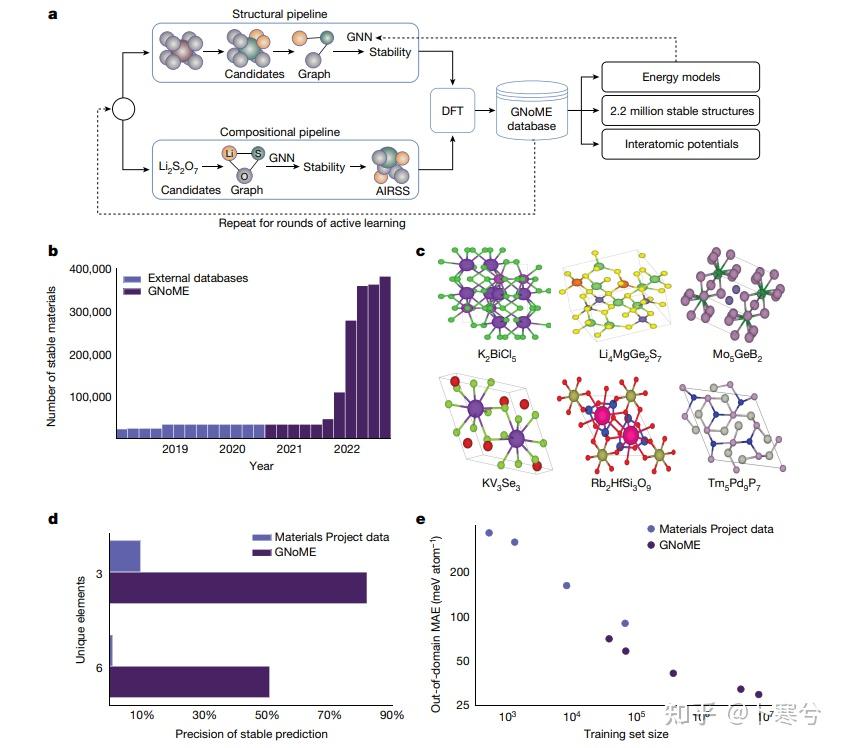
这篇文章大概是做了这么个事情:他们从Materials Project(一个常用的开放材料数据库)的69k数据集出发,结合图神经网络和主动学习,用第一性原理算了一堆新材料的能量(正文里没说数据集的大小,看补充材料应该是在10^8的量级)。结论就是说用了他们的大数据集模型的表现变得很好…
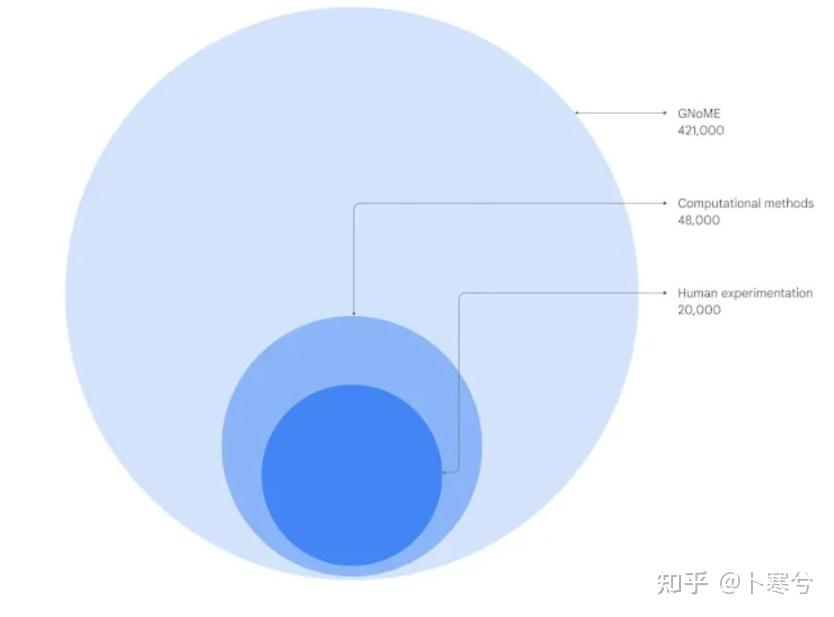
文章的一个卖点是声称发现了一堆新材料,这也是很多行外人容易被唬到的点,也是在很多报道(包括像经济雪人这种级别的杂志)里被曲解的点。首先所谓的新材料,不过是新的假想材料,这个你随便用一个材料结构生成软件想生成多少就生成多少。但是这种新结构不一定是理论上稳定,更不代表实验上能合成,而这篇文章关注的是理论上的稳定新材料。注意这里的稳定性不是材料的内禀性质,也就是说一个材料稳不稳定不是完全由它自身能量决定,而还取决于其他材料的能量。也就是说,当更多的材料被考虑进来的时候,更新后的结果会导致以前被认为是最稳定的结构其实就有可能不是能量最低最稳定的。原文里提到了220万和38万两个数字,前者可以理解成“如果我们以Materials Project数据库为基准,那新的数据库里有220万材料结构比基准数据库里的最稳定的材料还要稳定”(如果不好理解的话可以忽略这个数据);而38万这个数字,才是真正有意义的数据,表示的是最新的数据库里有38万种新的稳定材料。
另外值得一提的是,这篇文章考虑的理论上的稳定,还是非常简化情况下的理论情况,即在绝对零度下(-273摄氏度)的稳定性。实际上材料的稳定性是由自由能的决定,随着温度升高,构型熵振动熵等会对自由能有很大影响,这些温度效应在理论上是能够处理的,只不过是复杂了一点。如果做到这些,这篇文章至少还更有实际意义一些。
像这篇文章这样单纯堆DFT数据,说实话哪个有资源的计算组都能做,无非就是普通的高通量计算加点主动学习而已。最后的发现也毫无novelty可言。如果这篇文章堆完数据然后对数据集开放倒也多多少少对整个社区有点贡献,但关键是最后开放的数据集仅仅是稳定材料的那部分数据(占总数据不到1%)。这样基本上就不能复现文章里对机器学习模型泛化性能,以及不同模型之间的比较。Nature本身就对数据开放性有严格要求,结果这文章直接绕过了,编辑居然也放行。
与Google形成对比的是同行Meta的做法,他们的Open Catalyst Project从2020年一年一个新的催化材料数据集,量大又开放获取。另外Open Catalyst Project同样是堆大数据和大算力,但他们的文章也只是发在了ACS Catalysis上,这也是为什么我前面说这篇文章大概就是npj computational materials的水平。
另外再针对数据集的novelty说多一句:这篇文章堆出来的数据也不属于什么稀缺数据或者重要数据,而是很基本的体系能量数据,而没有任何一点其他的物性(比如band gap带隙, 弹性系数,吸附能等),而这些物性数据才是材料研发领域更缺乏和重要的数据,获取它们也需要更多的成本。早在2020年,Open Catalyst Project就已经有了同样量级的能量数据(而且全部开放获取),最近几年Meta已经在关注别的更重要的物性数据,而Google还在玩别人三年前玩剩的[摊手]。
其实针对这文章,包括我和一些做计算的同事都有类似的看法(即文章还不错,可以发业内顶刊,但是发Nature就离大谱了;另外文章也有些科学上的问题),但一般大家也不会公开指出,毕竟留一线日后好相处(所以我才上知乎吐槽而不是在领英发post)。
但圈内大佬就不太一样。下面是圈内领英里看到的一些评论:
Shyue Ping Ong,加利福尼亚大学圣迭戈分校教授,Materials Project及Pymatgen的主要发起人之一。他的post大概就是欲抑先扬,说了模型表现很好,但是通篇毫无创新,且数据不开放(违背了科学界的FAIR准则,即科学数据的可发现(Findable)可访问(Accessible)可互操作(Interoperable)可重用(Reusable)),最终导致科学结果不可复现(引用了最近的超导界的造假丑闻)。

另一个是Kamal Choudhary,美国国家标准与技术研究院staff scientist,npj computational materials副主编,JARVIS计划的发起人。他直接吐槽发nature不需要科学创新,只要像Google一样堆算力就可以,同样吐槽了不开放数据等同于科学造假。
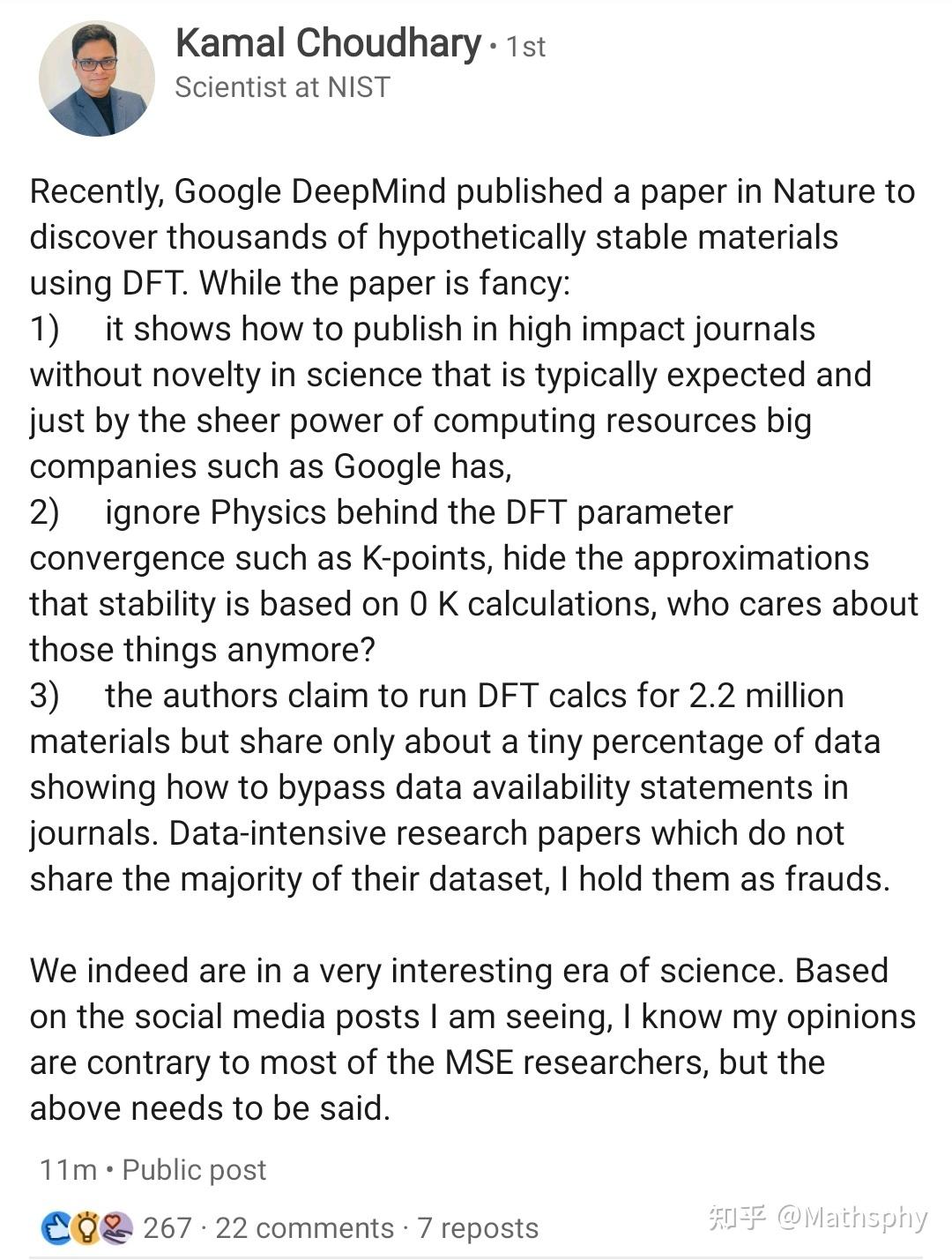
其他一些大佬们的评论。已经有人联系Nature编辑打算写评论文章了。
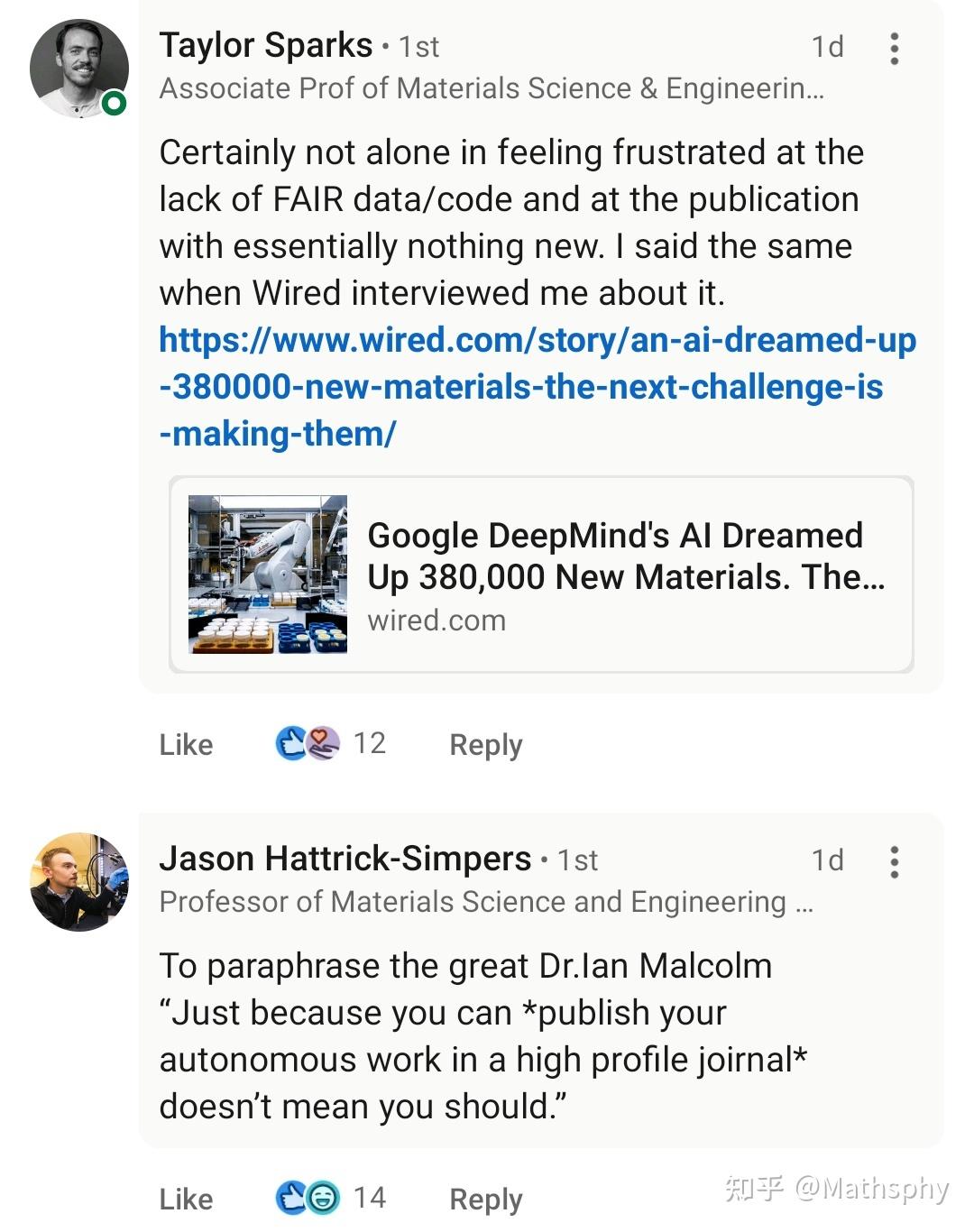
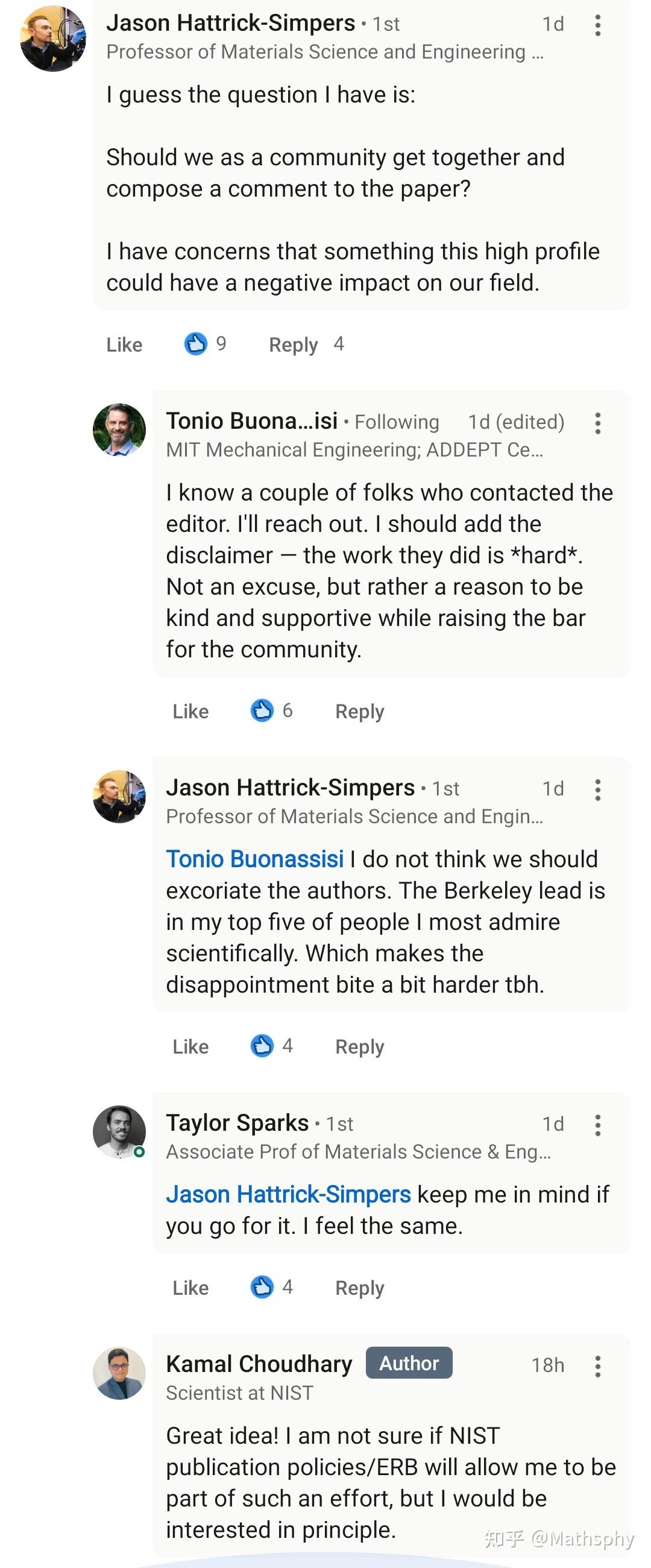
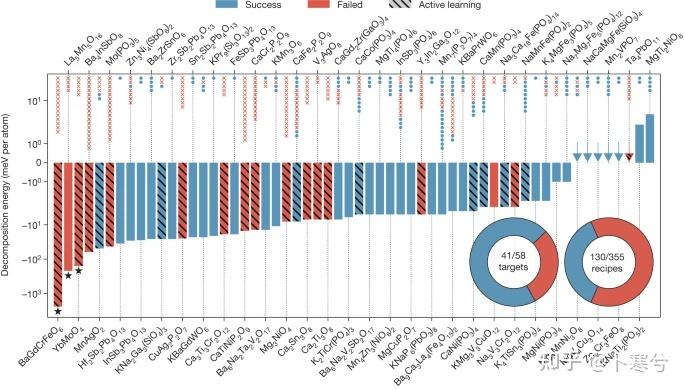
对了,同日上线还有另一篇相关的Nature文章,这篇大概是是基于Materials Project和Google DeepMind的数据,用自动化实验合成了几十个新材料。这篇也在twitter上被伦敦大学学院的Robert Palgrave教授质疑实验结果有严重问题,不适合发表。嗯我不太懂实验就不发表看法了…

 |