虽然数据库的目的都是为了解决数据的存储,操作问题。
但不同的数据库有不同的侧重点,根据不同的侧重点数据库有很多分类方式。
最常见的一种分类方式是物理存储方式
如果是存储在内存中,称为内存数据库,存储在硬盘则称为数据库,还有些数据组织为组织的文件格式(xml/json等)称为文档型数据库。
第二种分类方式是按查询接口分类
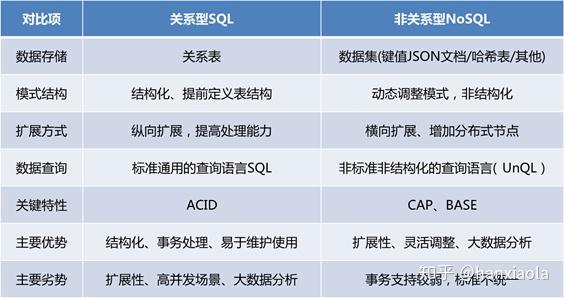
早期数据库各家对查询接口实现不统一,为了方便用户国际标准组织对标准化查询接口进行了规范化,标准化查询语言(SQL)是这规范的产物,SQL把数据库操作分为数据操作语言(DML),数据定义语言(DDL),数据控制语言(DCL)等几个部分,对每一部分进行了详细的规范和定义。
随着时间的变化分别有对应的多种版本实现包括SQL-92版,SQL-99,SQL-2003/2008/2011/2016等。
SQL标准化虽然很方便数据操作但也产生了一些问题,最典型的问题就是SQL语言是基于关系理论的查询接口,不支持非关系的底层结构,另外还有SQL的复杂性,相当多的用户使用的查询是很有限的一些操作,由于实现标准SQL的语言的存储结构限制和复杂性使得一些数据库放弃了对标准SQL的支持,转而使用更简单的操作接口这一部分数据便称为NOSQL数据库,NOSQL基本上使用简单的命令式交互接口,较之于SQL一般解析和操作更快,但同时也失去了复杂操作的能力。
第三种是按存储结构模型分类
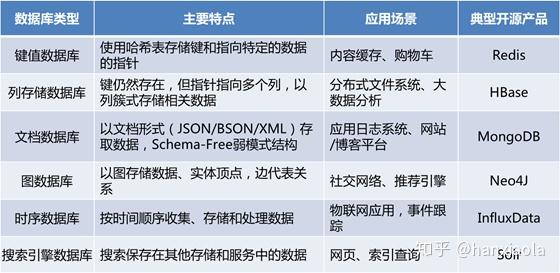
最常用的是关系型数据库,kv数据库(实质是一种松散结构化模型), 图数据库。
关系型数据库使用关系模型将数据表达为数学上的关系(组织上称为表),SQL的操作是关系操作。
通过关系理论来保证数据的完备性和约束性。数据之间的关系组织对于数据一致性和约束有着非常良好的实现。
但对于从事数据开发的业务人员来说这种结构还是比较严格和复杂的,比如对于常用的树型结构组织在以表为单位的关系数据库定义相当不直观。
因此有些数据库便以便于业务为重心实现基础数据结构采用一种更为松散的数据存储结构,这便是常见的kv数据库实现,相较于关系型数据库基于key用了快事检索,value中直接存储常用的数据结构,可以很方便的和编程语言的数据结构对应,对于开发来说是方便的;但同时也由于没有理论的保证数据的一致性维护和复杂操作变得麻烦。
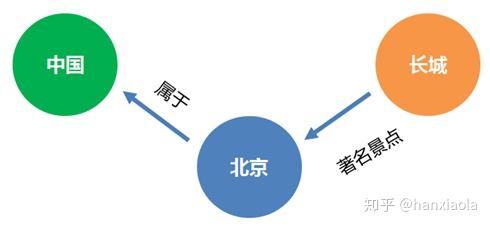
Kv数据库把数据松散化的存储方式仍然无法直接构建一些复杂的结构关系,比如一些图结构,而从结构上来说图结构是有能力实现一切的基础数据结构,因此为了底层存储结构的统一便产生了图数据库。
图数据库采用单一的图结构作为一切结构的基础上层只要提供图操作接口,便可以使图数据库有统一的访问能力。
相比之下,关系数据库更严格,kv数据库更松散,图数据库更统一。
也还有一些其它的模型,比如平面模型,半结构化模型,面向对象模型,网状模型这些多是上面几种模型的简化或结合的产物。
按是否商用可以分为免费和商用两种,一般免费的成本低,商用的服务有保障。
按是否开源可以分为开源和闭源两种,目前一般商用数据不开源,或社区版本开源,商业版高级功能不开源。
按网络化能力分为文件数据库,网络数据库和分布式/集群数据库。
一般文件型数据不提供网络访问能力,多用于独立系统或嵌入式设备开发。
网络数据库可以网络访问,多用于中小企业数据平台使用。
分布式或集群数据可以多台联合访问数据分布式存储,一般多用于大规模数据服务解决方案。
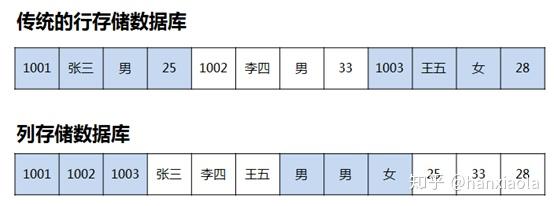
如果以表/关系为模型根据数据的行列存储不同可分为行式存储数据库和列式存储数据库。
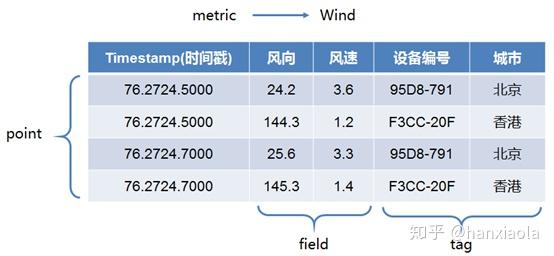
如果数据库提供了上层业务分析功能还可以分为时序数据库,AI数据库等等。 |