1 写 SQL (很多入职一两年的大数据工程师主要的工作就是写 SQL )
2 为集群搭大数据环境(一般公司招大数据工程师环境都已经搭好了,公司内部会有现成的大数据平台,但我这边会私下搞一套测试环境,毕竟公司内部的大数据系统权限限制很多,严重影响开发效率)
3 维护大数据平台(这个应该是每个大数据工程师都做过的工作,或多或少会承担“运维”的工作)
4 数据迁移(有部分公司需要把数据从传统的数据库 Oracle、MySQL 等数据迁移到大数据集群中,这个是比较繁琐的工作,吃力不讨好)
5 应用迁移(有部分公司需要把应用从传统的数据库 Oracle、MySQL 等数据库的存储过程程序或者SQL脚本迁移到大数据平台上,这个过程也是非常繁琐的工作,无聊,高度重复且麻烦,吃力不讨好)
6 数据采集(采集日志数据、文件数据、接口数据,这个涉及到各种格式的转换,一般用得比较多的是 Flume 和 Logstash)
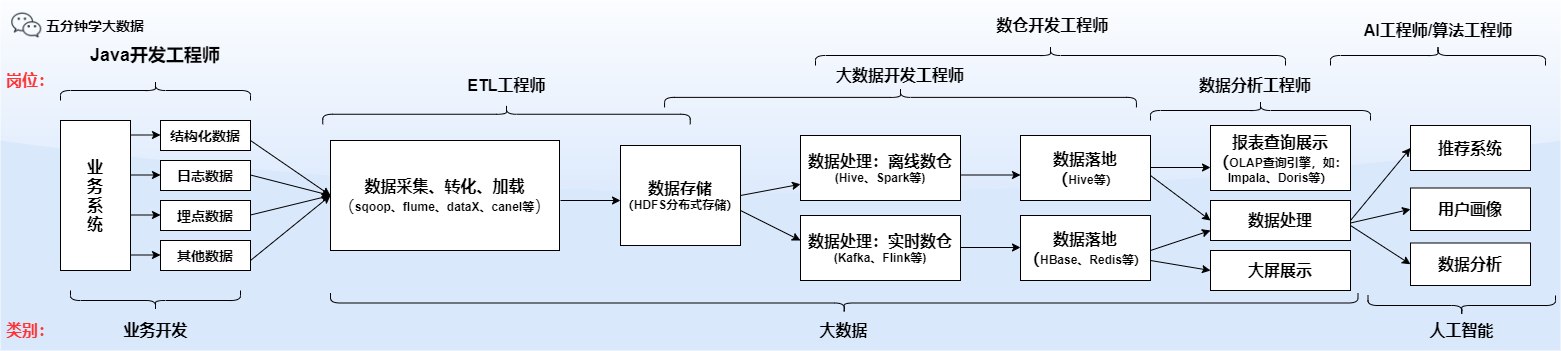
7 数据处理
7.1 离线数据处理(这个一般就是写写 SQL 然后扔到 Hive 中跑,其实和第一点有点重复了)
7.2 实时数据处理(这个涉及到消息队列,Kafka,Spark,Flink 这些,组件,一般就是 Flume 采集到数据发给 Kafka 然后 Spark 消费 Kafka 的数据进行处理)
8 数据可视化(这个我司是用 Spring Boot 连接后台数据与前端,前端用自己魔改的 echarts)
9 大数据平台开发(偏Java方向的,大概就是把开源的组件整合起来整成一个可用的大数据平台这样,常见的是各种难用的 PaaS 平台)
10 数据中台开发(中台需要支持接入各种数据源,把各种数据源清洗转换为可用的数据,然后再基于原始数据搭建起宽表层,一般为了节省开发成本和服务器资源,都是基于宽表层查询出业务数据)
11 搭建数据仓库(这里的数据仓库的搭建不是指 Hive ,Hive 是搭建数仓的工具,数仓搭建一般会分为三层 ODS、DW、DM 层,其中DW是最重要的,它又可以分为DWD,DWM,DWS,这个层级只是逻辑上的概念,类似于把表名按照层级区分开来的操作,分层的目的是防止开发数据应用的时候直接访问底层数据,可以减少资源,注意,减少资源开销是减少 内存 和 CPU 的开销,分层后磁盘占用会大大增加,磁盘不值钱所以没什么关系,分层可以使数据表的逻辑更加清晰,方便进一步的开发操作,如果分层没有做好会导致逻辑混乱,新来的员工难以接手业务,提高公司的运营成本,还有这个建数仓也分为建离线和实时的)
总之就是离不开写 SQL ... |