Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差,增强表征保真度,提高音频生成质量。
它采用预训练的语音编码器和语言解码器,提供文本和语音的延续。但是频谱图帧生成比较费时并且无法并行文本和频谱图解码。
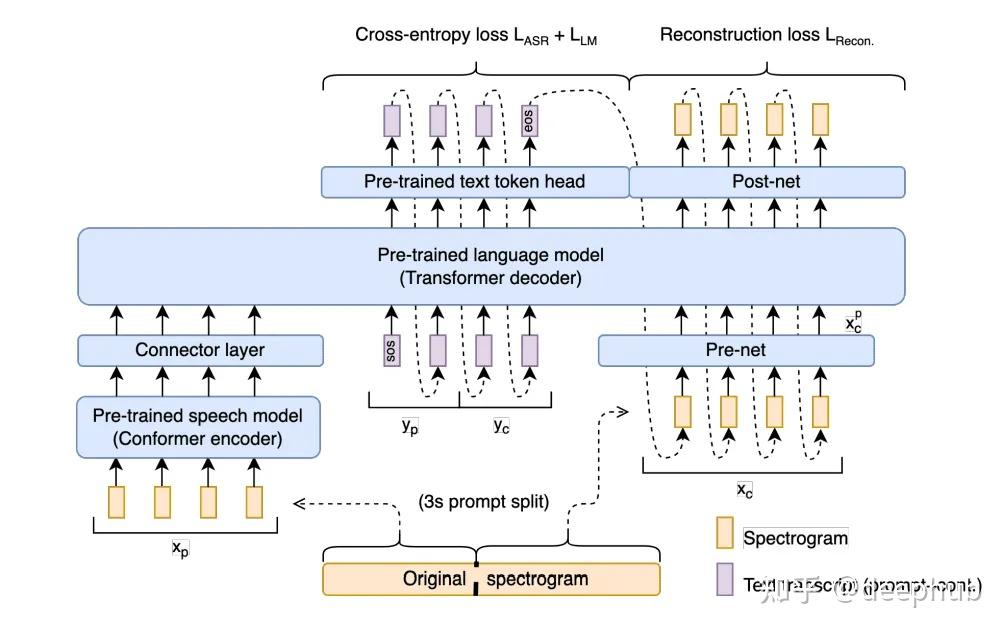
传统上,像GPT-3这样的LLM依赖于深度学习架构,在大量文本数据集上进行预训练,使他们能够掌握人类语言的复杂性,并生成与上下文相关且连贯的文本。而谷歌Research和Verily AI推出了一种新型口语模型Spectron。通过赋予LLM预训练的语音编码器,模型能够接受语音输入并生成语音输出。
Spectron与众不同的是其独特的直接处理频谱图作为输入和输出的能力。谱图是音频信号中频率随时间变化的频谱的可视化表示。Spectron利用中间投影层,和预训练语音编码器的音频功能,消除了通常困扰预训练编码器和解码器的归纳偏差。整个系统是端到端训练的,直接在频谱图上操作,这个方法的关键是只有一个训练目标,使用配对的语音-文本对来联合监督语音识别、文本延续和语音合成,从而在单个解码通道内实现“跨模态”
Spectron作为一个转录和生成文本中间媒介,可以进一步用于音频生成。该模型擅长于捕获有关信号形状的更丰富、更远距离的信息,并利用这些信息通过谱图回归与真值的高阶时间和特征delta相匹配。
Spectron架构的突破性在于双重应用,它可以解码中间文本和频谱图。这一创新不仅利用了文本域的预训练来增强语音合成,而且还提高了合成语音的质量,类似于基于文本的语言模型所取得的进步。虽然Spectron的潜力巨大,但它也有它的复杂性。比如过程需要生成多个谱图帧,这会很耗时。模型目前还不能并行处理文本和谱图解码。
Spectron的引入代表了人工智能领域的重大飞跃。其独特的处理频谱图的方法为改善语音合成和理解开辟了新的可能性。虽然还有技术挑战需要克服,但在各个行业中增强用户体验和生产力的潜力是巨大的,这使得Spectron可以成为市场上的游戏规则改变者。
有兴趣的可以看看官网:
https://michelleramanovich.github.io/spectron/spectron/
还有论文:
https://arxiv.org/abs/2305.15255 |



