希望可以开源Grok-0 33B模型【狗头】
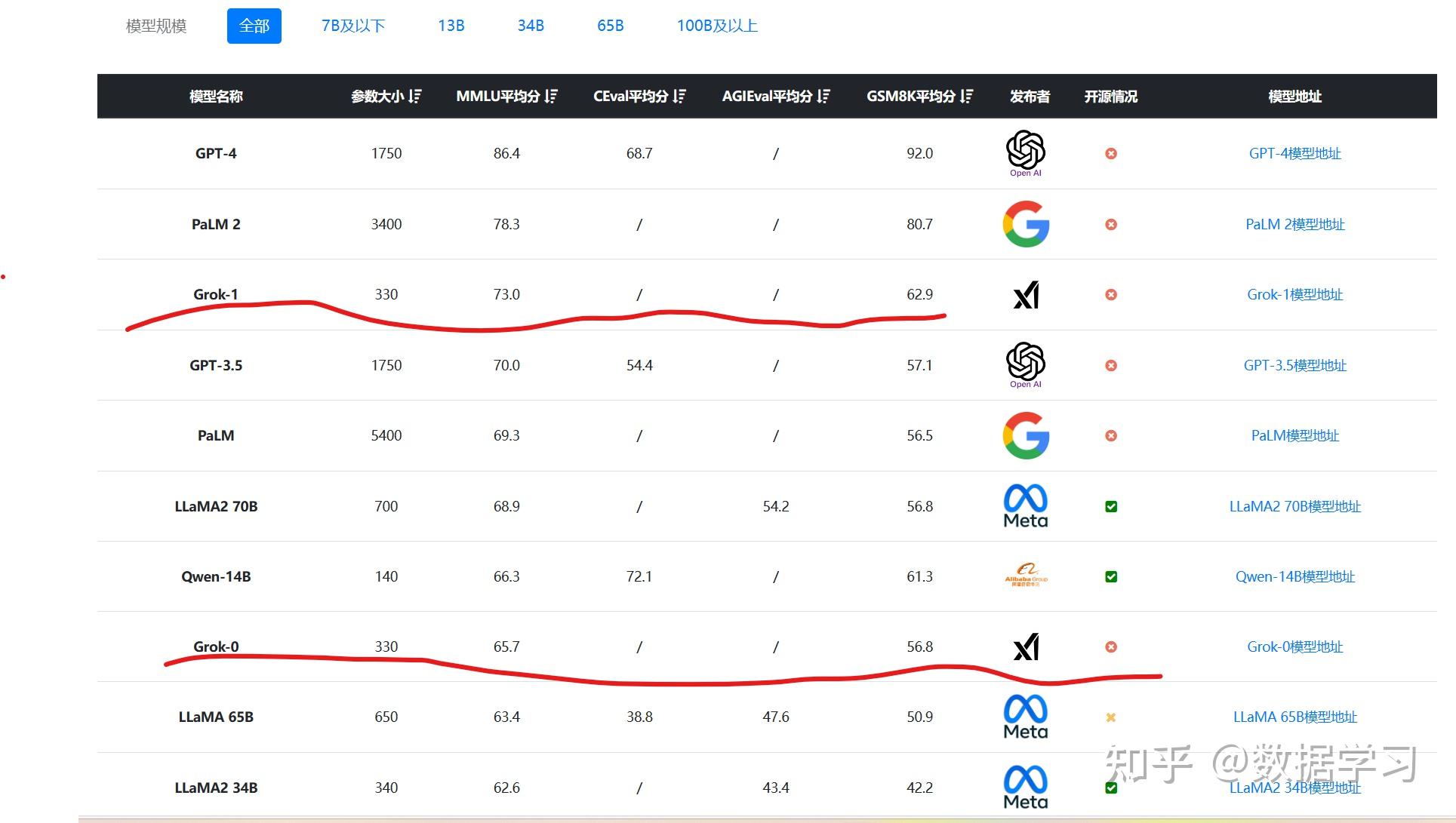
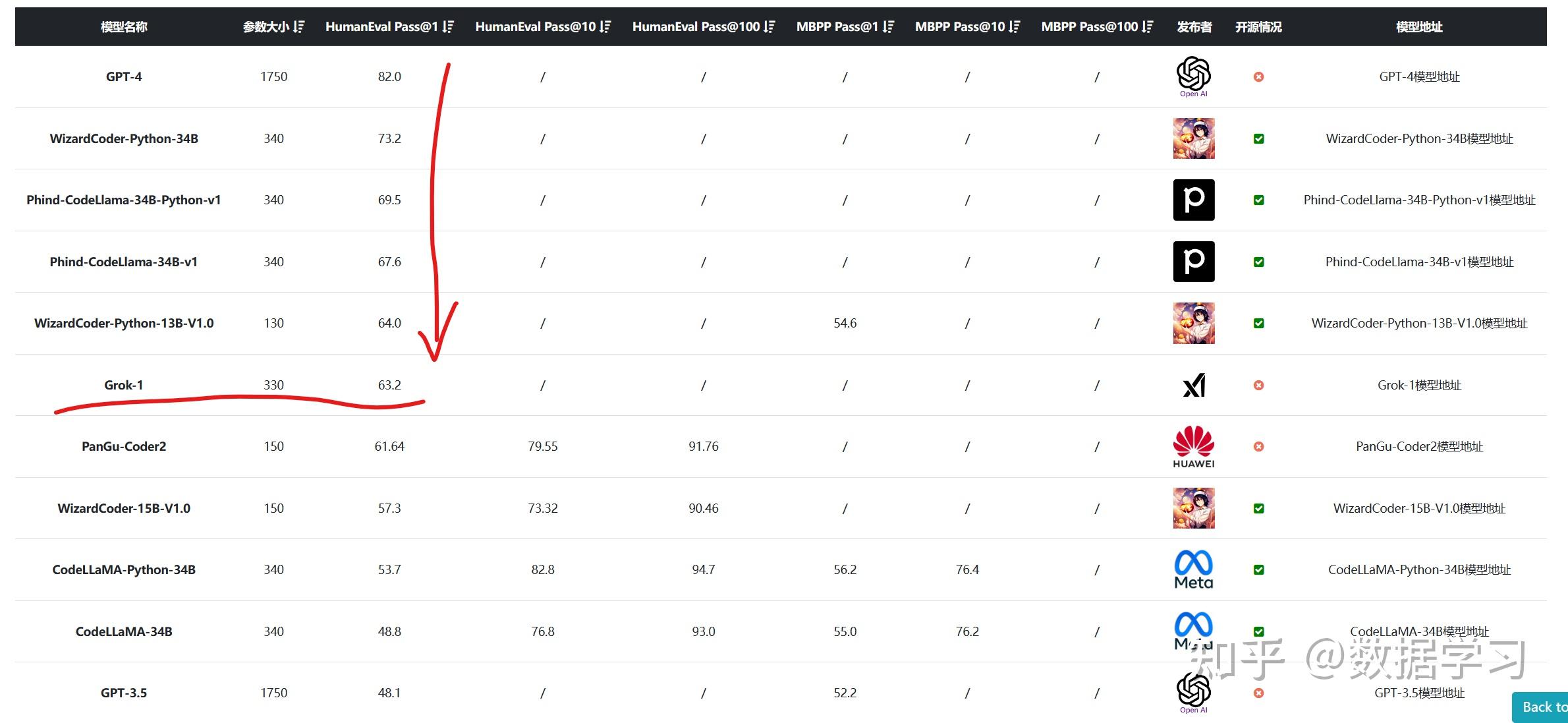
<hr/>从blog的结果上可以看到Grok-0在一些基础能力上有很有竞争力的表现,在数学和代码上都强于llama 2 70B这个模型,可以说是很有竞争力了。而Grok-1的数学,代码和推理能力都很强,完全可以成为一个构建当前众多应用的基石,可见xAI团队刚刚组建就交出了一份顶尖的作业。
值得注意的是,在blog里面还包含了未来的一些研究方向,可以看出xAI的目标也是提供更好的基础模型的服务,他们着重强调的内容如下。
Scalable oversight with tool assistance. Human feedback is essential. However, providing consistent and accurate feedback can be challenging, especially when dealing with lengthy code or complex reasoning steps. AI can assist with scalable oversight by looking up references from different sources, verifying intermediate steps with external tools, and seeking human feedback when necessary. We aim to make the most effective use of our AI tutors&#39; time with the help of our models.
Integrating with formal verification for safety, reliability, and grounding. To create AI systems that can reason deeply about the real world, we plan to develop reasoning skills in less ambiguous and more verifiable situations. This allows us to evaluate our systems without human feedback or interaction with the real world. One major immediate goal of this approach is to give formal guarantees for code correctness, especially regarding formally verifiable aspects of AI safety.
Long-context understanding and retrieval. Training models for efficiently discovering useful knowledge in a particular context are at the heart of producing truly intelligent systems. We are working on methods that can discover and retrieve information whenever it is needed.
Adversarial robustness. Adversarial examples demonstrate that optimizers can easily exploit vulnerabilities in AI systems, both during training and serving time, causing them to make egregious mistakes. These vulnerabilities are long-standing weaknesses of deep learning models. We are particularly interested in improving the robustness of LLMs, reward models, and monitoring systems.
Multimodal capabilities. Currently, Grok doesn’t have other senses, such as vision and audio. To better assist users, we will equip Grok with these different senses that can enable broader applications, including real-time interactions and assistance. 最后想说,上面的提到的内容确实就是我最想做的东西,也十分羡慕有这样的一个团队可以向这样的目标努力。 |