语音识别相信大家并不陌生,近些年来语音识别技术的应用层出不穷,同时也更加智能。从开始我们简单的询问“你是谁”,到现在可以与我们进行多轮对话,理解我们的意思甚至是心情,语音识别已经实现了长足的发展。可能大多数人觉得语音识别是近些年才出现的技术,其实不然,下面让我们一起从语音技术的历史展开来看。
Part 01 语音识别近70年发展史
1952年,贝尔实验室发明了自动数字识别机,科学家对智能语音有了模糊的概念,可能这时科学家们就已经在畅想我们如今实现的这一切。

1964年,IBM在世界博览会上推出了数字语音识别系统,语音技术也自此走出了实验室,为更多人知晓,贝尔实验室的梦想也变成了更多人的梦想。
1980年,声龙推出了第一款语音识别产品Dragon Dictate,这是第一款面向消费者的语音识别产品。虽然梦想第一次照进了现实,但其高达9000美元的售价,很大程度增加了智能语音技术的普及难度。

1997年,IBM推出它的第一个语音识别产品Via Voice。在中国市场,IBM适配了四川、上海、广东等地方方言,Via Voice也真正的为更多消费者接触、使用到。
2011年,苹果首次在iphone4s上加入智能语音助手Siri。至此,智能语音与手机深度绑定,进入广大消费者的日常生活。随后国内各大手机厂商也先后跟进,为手机消费者提供了五彩缤纷的语音识别功能。

此后,语音识别技术的应用,并没有局限于手机,而是扩展到了各种场景。从各种智能家居,如智能机器人、智能电视、智能加湿器等,到现在智能汽车,各大传统厂商以及造车新势力纷纷积极布局智能座舱。可见智能语音技术已经在我们的衣食住行各个方面得到了广泛应用。


Part 02 语音识别技术简介
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition,ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入。语音识别技术属于人工智能方向的一个重要分支,涉及许多学科,如信号处理、计算机科学、语言学、声学、生理学、心理学等,是人机自然交互技术中的关键环节。
Part 03 语音识别基本流程
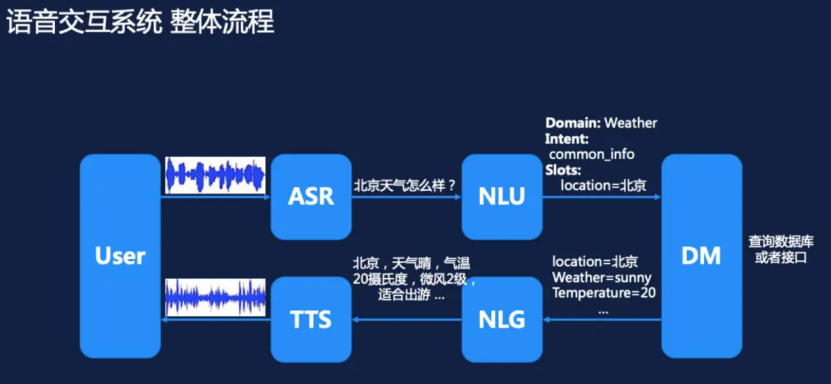
ASR:指自动语音识别技术(Automatic Speech Recognition),是一种将人的语音转换为文本的技术。
NLU:自然语言理解(Natural Language Understanding, NLU)是所有支持机器理解文本内容的方法模型或任务的总称。
NLG:自然语言生成(Natural Language Generation,NLG)是一种通过计算机在特定交互目标下生成语言文本的自动化过程,其主要目的是能够自动化构建高质量的生成人类能够理解的语言文本。
上图展示了一个语音识别的基本流程,用户发出指令后,mic收集音频,完成声音到波形图的转换,通过波形图与人类发音的波形图做对比,可以识别出说的具体音节,通过音节,组合成词、句子,再结合大数据分析出说的最匹配的话,然后NLU模块开始工作,分析出这句话的意图(intent)、域(Domain)等各种信息。分析出意图后开始对话管理DM(Dialog Manager),通过后台数据查询应该给用户什么反馈。然后交给NLG模块,通过查出来的信息,生成自然语言,最后通过TTS模块,将文字转回成波形图并播放声音。
上面的流程涉及到的学科、知识都比较多,由于篇幅原因,不一一展开描述,在这里我节选出ASR来进行相对详细些的学习。
Part 04 ASR实现原理简单剖析
我们首先从ASR声音源来看,当一位用户发出指令,比如说:我爱你。这时麦克风会收集音频到存储设备。我们通过音频处理软件(如Audacity)打开后可以发现音频是一段波形图。
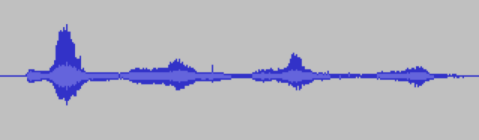
但是这段波形图并没有什么直观的有意义的信息,它的高低只代表了声音的大小,横轴也仅仅是时间。语音识别本身是基于大数据的分析技术,分析的基础是数据的准确,声音大小和发音的时间长短很难有什么统计学的意义,所以此时我们需要对音频进行处理。(这段波形图是四句我爱你的波形图)。
处理的一种常用方法是傅里叶变换,通过傅里叶变换,我们可以将时间维度的波形图,转换成频率维度的波形图。
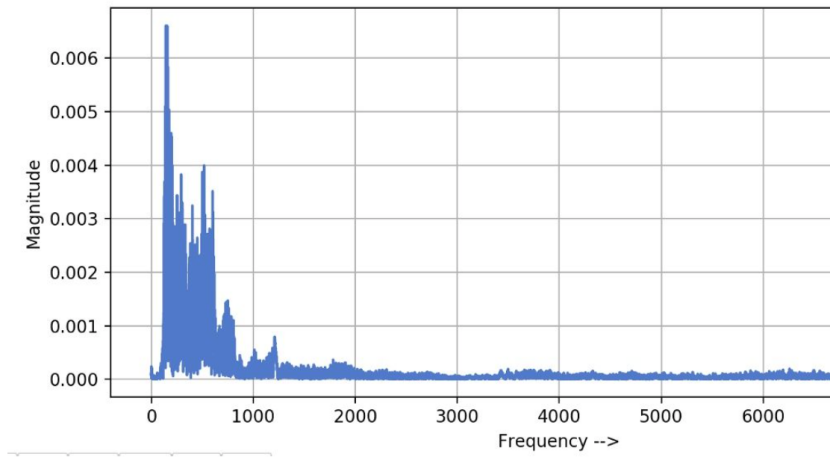
❖ 为什么要处理成频率的维度呢?
因为我们都知道,人类发出的声音,能听到的声音大概在一个频段内。这涉及到生物学、声学的知识,我们人类的身体构造大致相同,这里想当然一下,尽管有个体差异、有性别差异,我们发出的声音的频率相差不会很大。这样我们就把没有统计意义的声音波形图处理成了频率图。
但是我们的时间维度也不能丢掉,我们在将声音分割之后(这里涉及到声音预处理、分帧等知识,暂不展开),可以根据本地的声学模型做比对,看每一帧时间内发出的音素是什么。中文的话,音素指的是我们发音的一个字母,比如“我”由两个音素组成:w和o。
到现在我们知道了如何将声音从音频文件处理成音素。之后再通过语言学、统计学等技术,结合具体语境,将音素组合成词,将词组成句子,从而识别出用户说的语句,ASR大致流程就完成了。
上面的方式其实属于语音识别各种技术中较为简单的一部分,在实际应用中可能还包括各种各样的技术,比如声学特征提取的MFCC方式、上面声音预处理的降噪、分帧、加窗、端点检测等技术。
Part 05 语音识别及相关技术展望和我们能做的事情
随着硬件技术提升、5G技术普及,我们可以在后端对海量的数据进行处理,依靠5G技术的稳定和低时延,为用户提供更可靠、顺畅的服务,可以预见在不久的将来,语音识别及其相关技术必将更加智能、更加稳定。中国移动作为国内拥有绝对用户基础数量优势的电信运营商,可以依靠5G优势、规模优势为用户提供更好的服务,为智慧城市提供有力的保障,为国家发展作出更多的贡献。
参考文献
1.https://www.163.com/dy/article/GPOAIA4G053722QL.html
2.https://baike.baidu.com/item/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB%E6%8A%80%E6%9C%AF/5732447?fr=aladdin
3.基于大数据和深度学习的语音识别研究 温伍正宏 潘甦 张坤 |



