谢邀
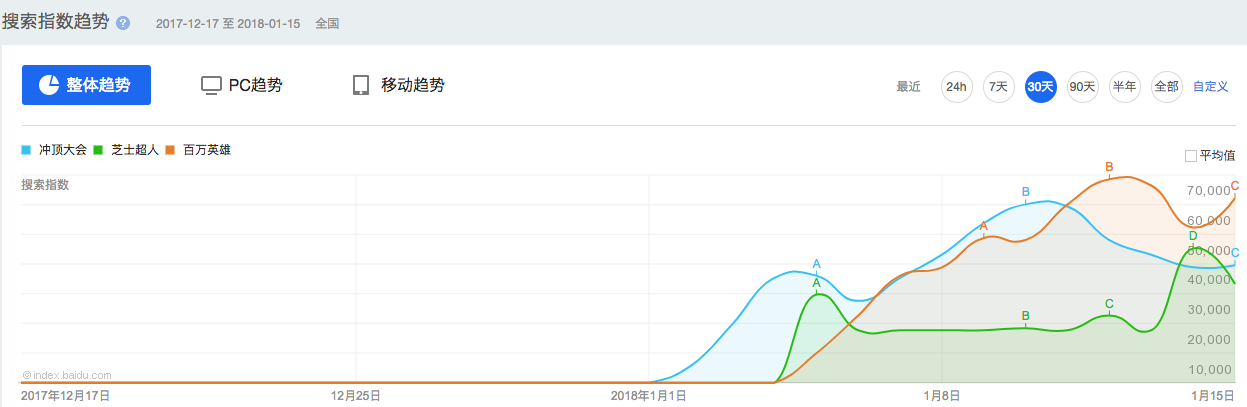
最近,移动端的冲顶答题竞赛在投资人,技术公司以及参赛者的推动下一下火了起来。在这波热潮中,有三个主要参与方:答题平台投资人及其所代表的公司,趁机推出辅助答题神器的技术公司以及直接参与答题竞赛的广大参赛者。
三方所代表的角色不同,所以在这场活动中的目标也不一样。答题平台公司为了争取用户流量,因为流量就是网络公司的生命线。推出辅助答题神器的技术公司则着眼于展示和宣传自己的AI 技术和能力,在这场活动中取得了很好的广告宣传效果。而广大竞答参赛者则多半是为了获取不菲的奖金,高达上百万的现金奖励立竿见影地让他们趋之若鹜。
有需求就有供给,某网络销售平台上马上出现了销售价便宜到不足10元的的答题助手供用户选择,更有国内两大搜索技术公司推出了基于搜索引擎技术的AI答题神器,一时间被部分用户叫好,甚至赞不绝口。
在人工智能 – AI 这个名词已经深入人心的当下,普通用户虽对 AI 都存有敬畏之心,对AI答题助手所展现的能力感到惊叹,却不明白背后到底是咋回事,更不用说掌握后面的技术了。
“开放领域的智能问答(Open Domain Question Answering)”,既是一门技术,也是AI这个大话题下的一个子课题。具体地讲,它是综合利用网络爬虫,信息检索,自然语言理解,机器学习,深度学习,知识表示和推理,知识图谱等技术,为用户提供开放领域的问题答案。
与大家最熟悉的传统搜索引擎相比,它最大的不同在于为用户提供的答案是小片段的单词,短语,一个或少数几个句子,而非一个链接所指向的整篇文档。正是因为它向用户能提供精确答案而非长文本的整个网页,所以技术要求也更高,难度也更大。智能问答系统通常能够比较好的回答事实性的问题(factoid question),比如“谁是美国总统?”,“二战发生在什么时候?”。
世界上最知名的问答系统就要算IBM 的沃森系统(Watson)了,它在 2011 年因在美国游戏竞答电视节目《危险边缘》(Jeopardy!)上一举战胜该节目上的两大常胜将军Ken Jennings 和Brad Rutter 并获得第一名而成名,奖金额高达100 万美元。竞赛期间,沃森问答系统索引并存储了超过2亿的结构化和非结构化页面内容,磁盘空间使用量超过了4TB。
沃森的主要创新并不在于发明和使用新的算法来查找答案,而在于能够同时并行运行多个自然语言分析算法,并将多个算法独立计算出的相同答案作为最可能的答案予以输出并取得好的应答效果。而这种充分利用网络“数据冗余性”的特点来发现并提取最大概率问题答案的方法,是多数基于统计方法的开放领域问答系统背后实现的基本思想。
开放领域智能问答系统牵涉到的技术很多,技术链条比较长。
除了这次推出各种答题助手的企业,其实智能问答系统中的很多技术已经在不少企业中得到了深入应用,京东就是其中一员。
京东作为一家以技术立足,以AI为业务驱动力的知名电子商务公司,始终将AI 专注于自己的核心业务,不断提高用户体验,降低成本并提高效率,并已将AI 广泛应用到各个电商核心业务场景中。我们不妨从开放领域问答系统入手,看看这些人工智能技术的实际应用及发展趋势。问答系统流程如下图所示:
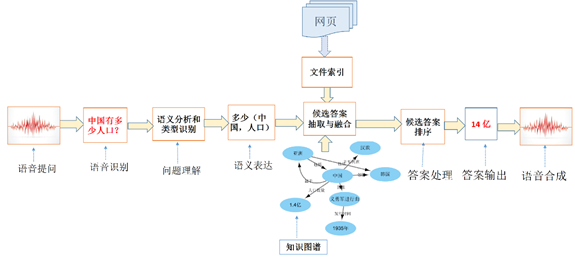
用户通过语音提出问题后,自动语音识别系统将语音转换为文本,“中国有多少人口?” 之后提问进入语义分析和问题类型识别模块,这里可能的处理包括提问式重写,分词,词性标注,命名实体识别,意图识别,问题类型识别等。
如果是图像方式提出的问题,则需要调用OCR(光学字符识别系统)系统。同时,从网络采集数据建立知识库也包括从图像的文字描述中提取知识,这通常也涉及到应用OCR技术将图像中的文本图像有效转换为文本数据。
京东基于深度学习模型的 OCR光学字符识别系统,被广泛应用于商品属性提取和商品知识库的构建中。同样基于深度学习的图像识别能力,每天有数亿次的调用,其应用包括相关业务部门的打假和鉴黄。
语义分析模块的结果是语义表达模块,这里的表达可以是很简单,比如只保留提问式中的内容词汇;也可以很复杂,即生成一种逻辑表达式完整表达提问式的语义,或基于深度学习模型的问题表达向量。
不同的系统设计目标和策略不一样。例如意图识别:针对用户输入的文本,通过意图识别之后对应到订单、售后、商品、闲聊等不同的类别。
意图识别对JIMI非常重要,用户的每一句问话,JIMI首先要判断他的意图,到底说的是订单问题、商品咨询还是售后问题,抑或单纯的闲聊,才会给出更好的反馈。
命名实体识别:先对用户输入的文本进行识别,在对识别后的命名实体进行抽取,对应到人名、地名、商品名、机构名等不同类别,更好地理解用户的语言。所以,命名实体识别其实也是用户意图识别的必须步骤。
之后系统根据生成的语义表达去文件索引或知识图谱中检索答案,如果答案有多个,这里需要进行答案的融合。从知识图谱中检索答案需要将用户的自然语言提问式转化为一种结构化查询语言,比如SPARQL, 然后通过SPARQL 从RDF 三元组库中查询答案,并可以实现基于有向图的逻辑推理而获得新事实或答案。
在智能自动问答和知识图谱应用方面,京东的客服机器人JIMI已经取代人工客服接近一半的工作量,因而大大降低成本和提升效率,并在特定时间段能够提供比人工更优质的客服体验。基于深度学习模型的自然语言理解,对话管理和自然语言生成构成了智能客服问答系统的三大核心模块。包含数十亿级别实体和关系的电商知识图谱,为客服对话系统提供海量的知识,并成为基于图谱推荐和知识推理的核心要素。
从文件中检索答案的第一步是找出包含答案的潜在段落,这通常是通过应用文本检索的词语加权算法TF/IDF 实现的,即问题和文章都表示为通过TF/IDF 加权后的Bag-of-Words 向量,二者的相似性通过比较向量的的相似性得到。
为了提高效果在TF/IDF 的基础上也可以引入N-gram 作为额外特征,通常是 Bi-gram 或 Tri-gram,这样可以在一定程度上将问题和相关段落的词语次序考虑在内。问题的相关句子或段落找到之后,下一步就是从段落中计算精确的答案。
简单的答案提取方法包括将句子中所识别的命名实体与问句中的问题类型做对比,所有与问题类型相同的命名实体全部作为候选答案进行排序。
更常见的做法是通过利用网络“数据冗余性”的特征训练机器学习模型,将概率最大的候选答案反馈给用户,这种情况下一般不会用到深度自然语言处理或知识推理技术。
近年来,基于深度学习的机器阅读理解成为热门的研究课题,因而它也被用到智能问答系统的答案自动提取任务中。
基本方法是将候选答案段落和问题都表示为深度神经网络,通常是多层的“双向长短记忆”的 LSTM 模型,然后将段落向量和问题向量作为输入训练分类器,分类目标是识别段落中答案字符串的起始和终止边界。
在搜索和推荐方面,由于京东拥有海量的商品数据和用户数据,以及为满足不同业务需求而广泛采集的网络数据,京东的大数据平台建立了海量的大数据索引,包括文本索引。以此为基础的搜索应用包括以深度学习模型为基础的智能搜索,智能问答,以图搜图、精准推荐、用户画像、商品画像、地域画像、语音识别,AR扫描拍照购以及大规模舆情数据分析等。
问题答案被精确提取后,通过语音合成模块将答案通过音频传给用户。
上面流程图中开头和结尾分别是语音识别与语音合成模块,当前二者都是通过深度学习模型实现的,得益于大量可得的训练数据,在多数场景下效果通常非常好。
语音识别的热点技术模型和机制包括 CTC+RNN,Deep CNN, Attention, 而语音合成也主要是应用深度学习模型取代传统的隐马尔科夫模型(HMM),比如 Deep MixtureDensity Network (MDN),结合深度神经网络 DNNs+GMM架构。
上面介绍了开放领域问答系统的整个流程和技术方案,也不难看出,在京东这样的企业中,相关的人工智能技术已经得到广泛应用,消费者可能不知道,您在电商购物时享受的便利服务,就是这些可以轻松应对知识问答挑战的智能后台系统在支持。
京东下一个十二年发展的核心是技术,而事实上经过过去几年的战略性转型,重点布局和技术沉淀,京东已经成为一家名副其实的,以AI为核心驱动力的技术公司。
2017 年 11 月 27 日,京东集团宣布与斯坦福人工智能实验室启动京东-斯坦福联合AI研究计划,京东将联合斯坦福人工智能实验室围绕机器学习、深度学习、机器人、自然语言处理和计算机视觉等前沿技术方向,结合京东实际应用场景和数据,开展以研究项目为基础的合作。
首期启动的项目主要侧重于自然语言理解和知识图谱在电商场景下的前沿技术及应用。
京东集团副总裁,AI平台与研究部负责人周伯文博士在与斯坦福的签约仪式上表示, “斯坦福在人工智能领域的研究世界瞩目,京东与斯坦福的合作必会将AI驱动的第四次零售革命带向新的高度。”
京东将以首个海外联合AI研究计划开始,以人工智能技术为核心,推动成本、效率和用户体验的不断优化,加速京东的技术驱动转型之路。 |