序:作为一个长期从事计算机视觉工作的从业人员,也一直在进行计算机视觉底层算法研究。结合多年来的从业经历及科研经历,总结一下2021年计算机视觉领域的技术进展,同时对2022年计算机视觉的热门技术阐述个人的观点。 1. 工业界:对学术研究提出需求
2021年业界最火的两个概念:自动驾驶与元宇宙,这两个概念可能代表了未来一年甚至更久的一个行业走向。因此,工业界对学术界的需求在接下来一段时间大概率是基于自动驾驶与元宇宙的,这将是学术界的研究热点。分析自动驾驶及元宇宙的一些主要组件及底层技术,如图1所示。
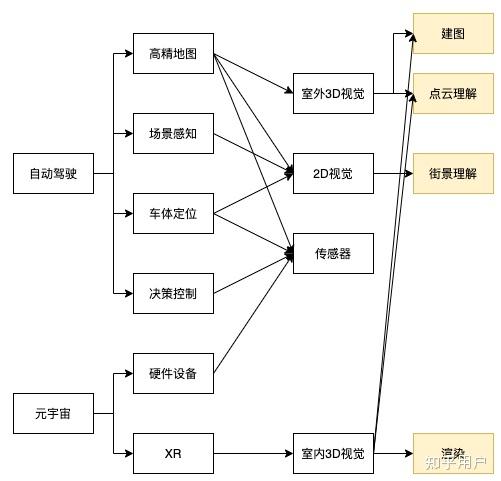
图1 自动驾驶及元宇宙的主要组件及底层技术
可以推出学术界计算机视觉相关的研究热点如下:
(1)建图技术:三维重建技术,包括SLAM、定位、建图、更新等技术;
(2)点云理解技术:三维理解技术,包括点云检测、分割等技术;
(3)街景理解技术:街景图像视频识别、检测、分割等技术;
(4)三维渲染技术。
2. 学术界:自驱的学术研究
分析学术界的研究热点,这里重点以计算机视觉顶级会议CVPR 2021及ICCV 2021为例(2021年没有ECCV,相应的顶级期刊时效性可能没有会议快,因此均暂不分析),分析相应主题的论文接收情况。
CVPR 2021及ICCV 2021的关键字云图及对应文章数量如图2和图3所示。
图2 CVPR 2021(上)及ICCV 2021(下)关键云图
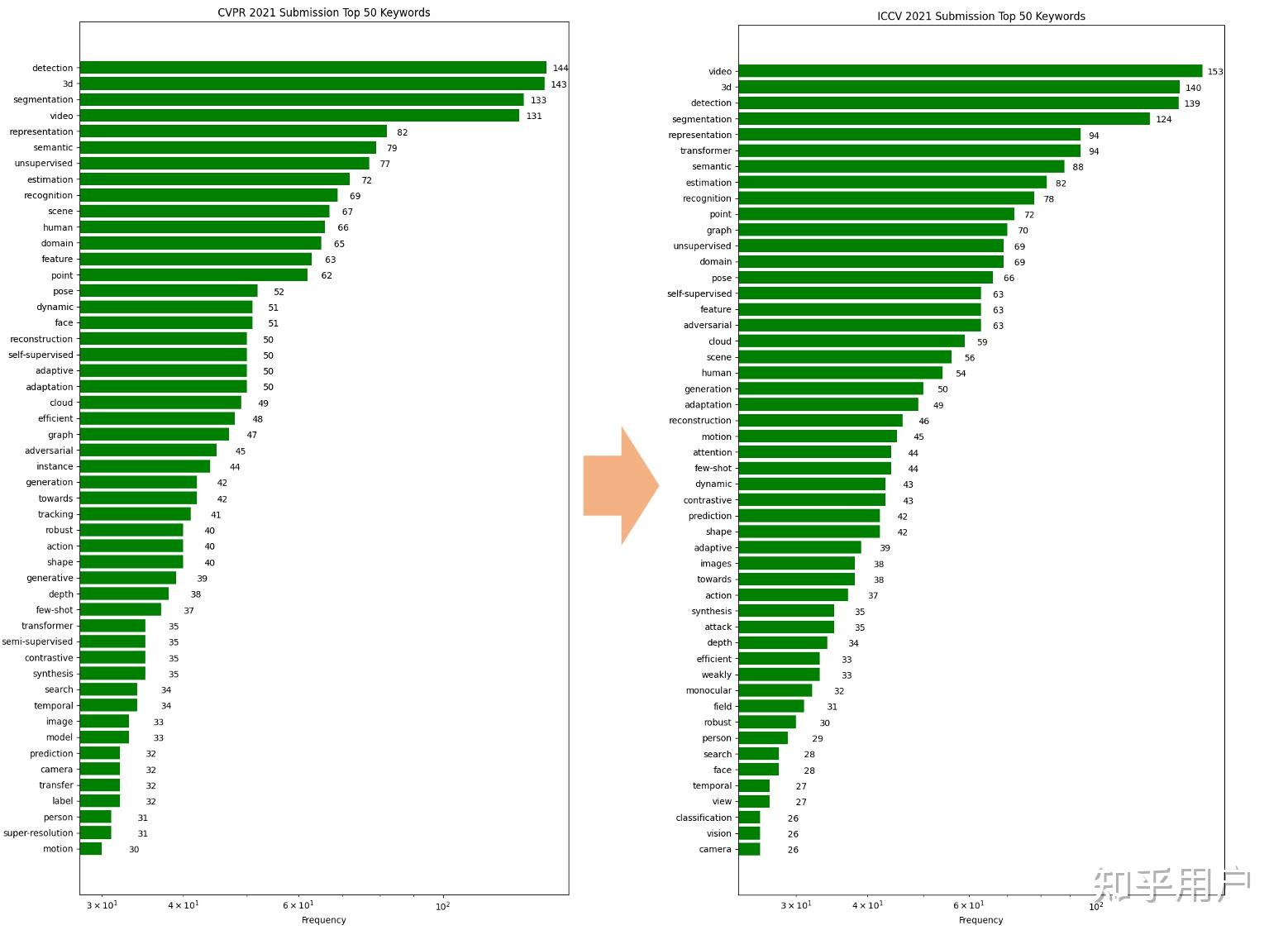
图3 CVPR 2021(左)及ICCV 2021(右)关键字对应文章数量排序(前50)
可以看出:
- CVPR 2021前五的研究热点是:detection, 3d, segmegmentation, video, representation learning;
- ICCV 2021前五的研究热点是:video, 3d, detection, segmentation, representation learning和transformer。
有个重点趋势可以发现:transformer相关文章从CVPR到ICCV不到半年时间增长非常明显(35篇->94篇)。
基于个人在计算机视觉领域的长期论文跟踪,2021年CV圈较火的研究点集中在两点:
- 基于transformer的应用问题(包括检测、分割、3D视觉等);
- 基于self-supervised的应用问题,尤其是transformer。
相应地,计算机视觉在学术界自发(bottom-up)的研究热点可以总结如下:
(4)基于transformer的视觉技术:已有大一统的趋势;
(5)基于self-supervised的无标注视觉技术。
3. 总结一下
接下来的研究热点个人分析主要包括:
面向应用(工业界):
(1)建图技术:三维重建技术,包括SLAM、定位、建图、更新等技术;
(2)点云理解技术:三维理解技术,包括点云检测、分割等技术;
(3)街景理解技术:街景图像视频识别、检测、分割等技术;
(4)三维渲染技术,
面向通用(学术界):
(5)基于transformer的视觉技术:已有大一统的趋势;
(6)基于self-supervised的无标注视觉技术。
更细致的研究方向就要看个人的taste了,喜欢应用层的研究(工业界需求的)可以更多考虑1-4,喜欢底层研究(偏纯学术路线的)可以更多考虑5-6。如果是发文章的话,以上提到的方向是顶会文章最多的,是最近的研究热点,肯定是相对更容易发表的,但也意味着是竞争最大的,因为很多人都会朝着这几个方向努力。
关于更细分的方向可以直接选择以上其一,也可以将以上1-4与5-6排列组合,例如基于transformer的稀疏重建、基于self-supervised的街景目标跟踪等等。
实际上,计算机视觉每个方向深耕都可以做出不错的工作(例如小样本、多模态、增量学习等),并发表顶会顶刊文章,如果已经有明确自己钟爱且值得深入研究的课题请不要放弃,目前我们看到的热点很多其实最初也是1-2篇颠覆性的文章引领起来的,因此沉下心来做出真正有用有意义solid的工作,这比灌水N篇都值得赞赏。
<hr/>如果日常喜欢跟踪最新前沿论文,可以关注专栏:
arXiv每日更新会每天更新arxiv中计算机视觉相关文章,并进行热点分析、分类及简介。 |