首先,基础的机器学习知识必不可少,因为传统的一些方法就是手工特征+机器学习方法等,在2012年以前的ImageNet视觉挑战赛上获胜,这里安利一些资料,不过都是老生常谈了。如周志华老师的《机器学习》、李航老师的《统计学习方法》、《机器学习实践》、吴恩达老师的cs229、李宏毅老师的机器学习视频(B站就有),除此以外,基础的图像处理知识也是必不可少的,比如冈萨雷斯的《数字图像处理》。
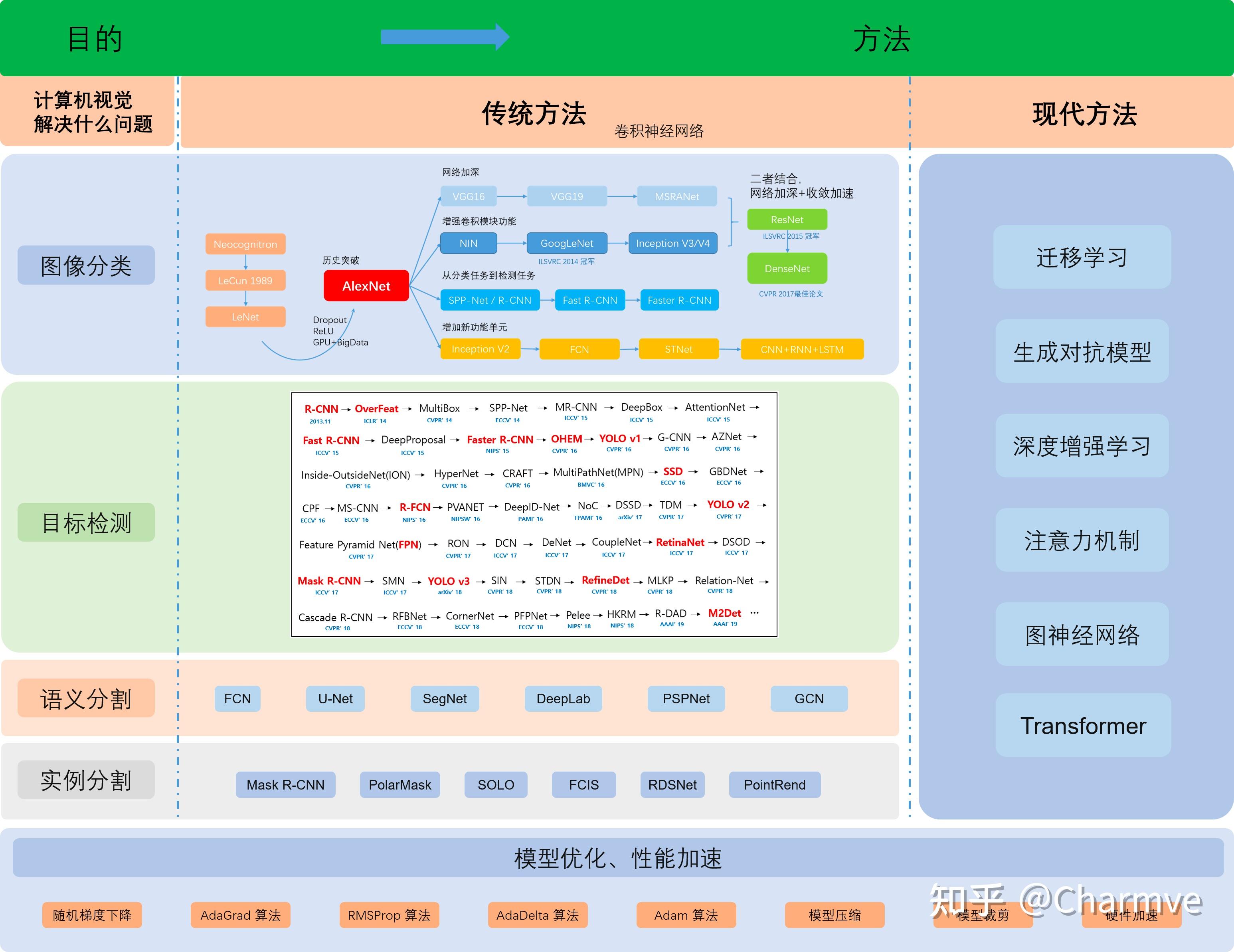
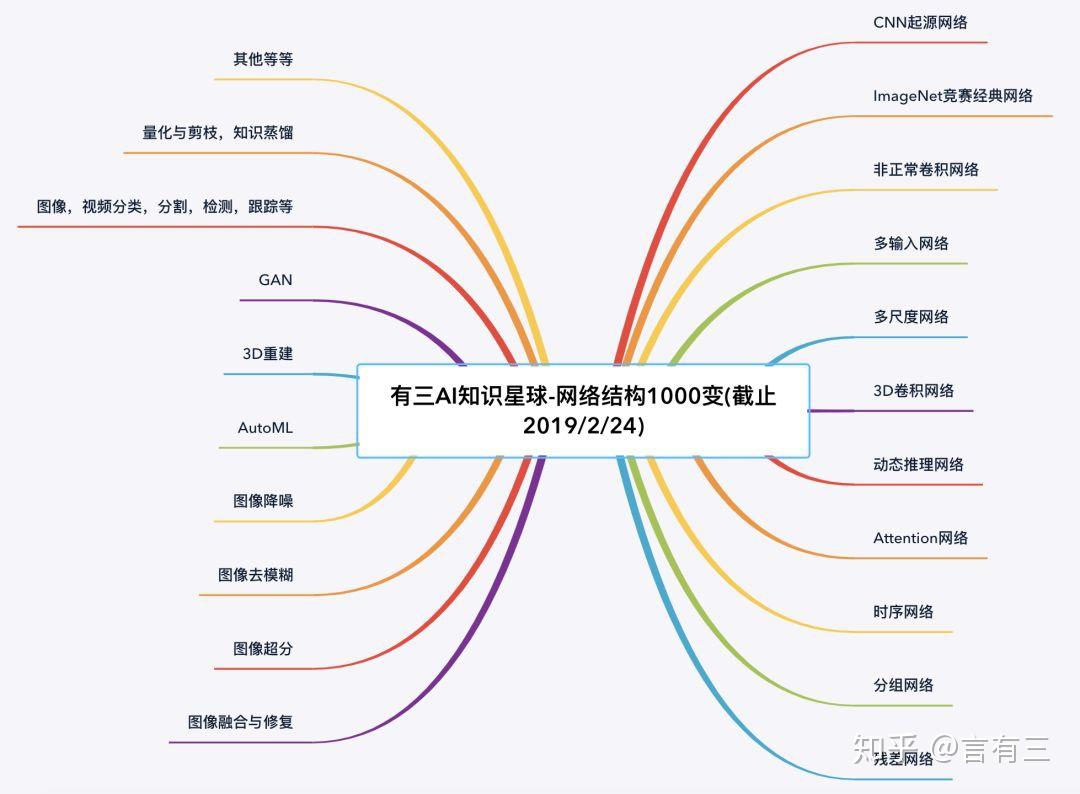
其次的话,就是深度学习了,2012年以后深度学习方法在计算机视觉领域一骑绝尘,经典网络必须要知道,LeNet、AlexNet、VGG、GoogLeNet、ResNet、DenseNet、SENet等,还有一些轻量级的网络,比如ShuffleNet、MobileNet系列,我在第七章节中已经更新了相关论文的解读和源码实现。在更详细的任务中,有一些经典任务,上述的一些网络主要是分类网络,用于分类的,比如给一张图,输出图片是猫还是狗,但是会有很多更复杂的问题,比如图像既有猫又有狗,这时候网络应该输出什么呢?这样就衍生出了经典任务中的检测任务、分割任务等。
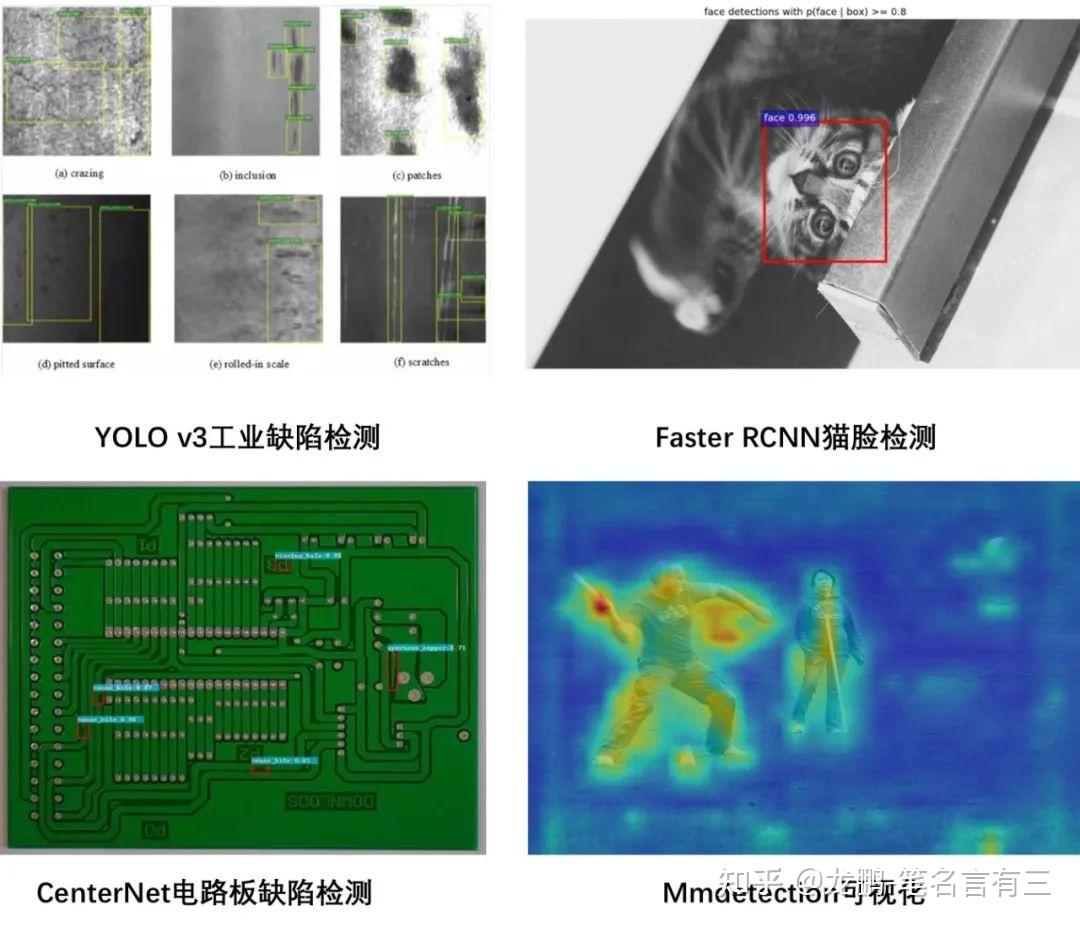
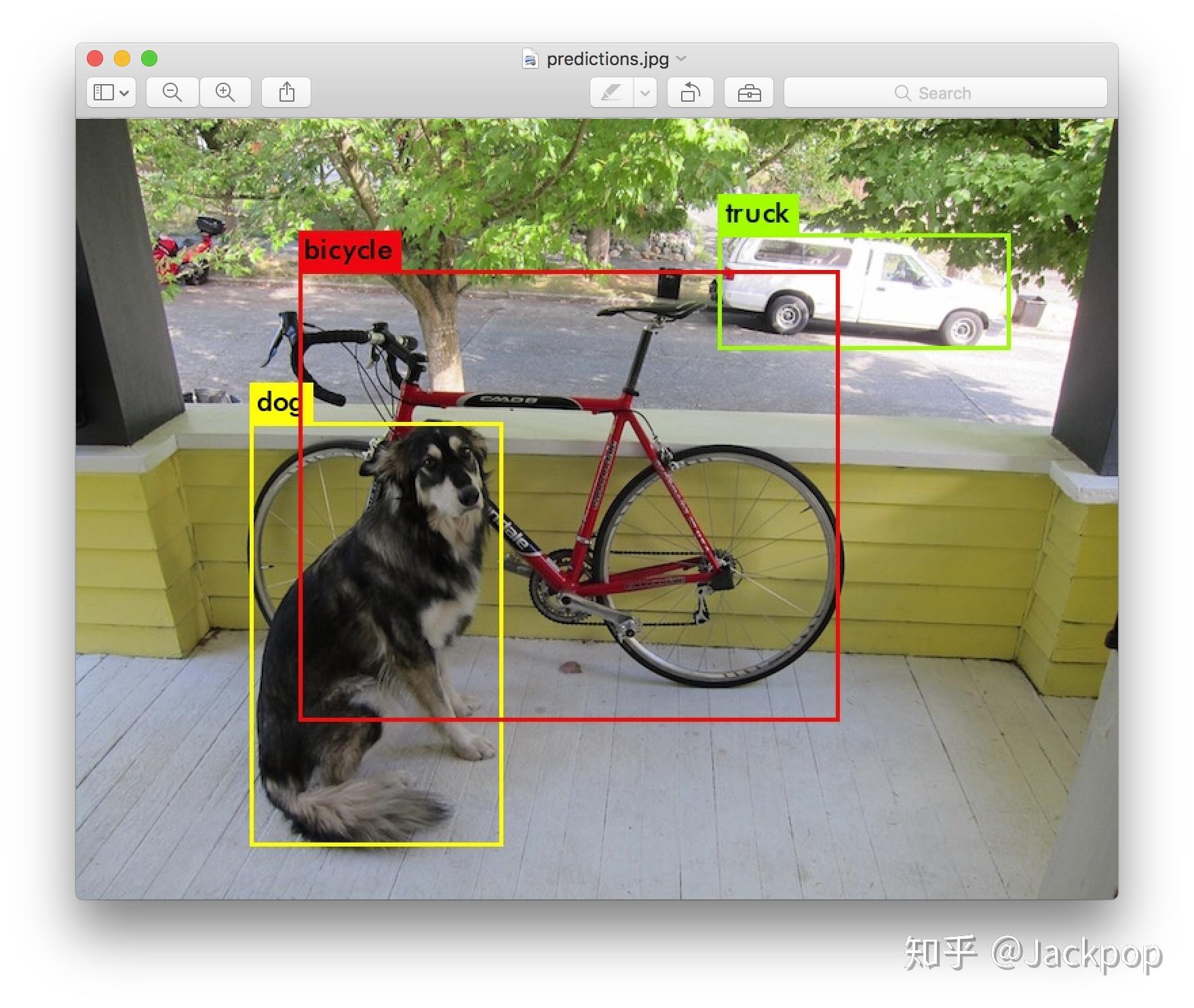
检测任务实际是输出目标的位置和概率,位置就是用bounding box圈出目标物体。目标检测大概的发展是这样(本人水平有限,难免会有错误,欢迎批评指正),在一张图中密集生成候选框,然后提取特征+机器学习分类器,这里就有一个问题如何生成候选框,滑窗法、随机搜索法等,不断发展。2014年出现了一个很出名的文章——RCNN,将深度学习用到目标检测中,但是仅仅是将CNN作为特征提取器。在此就不再赘述,RCNN系列(RCNN、Fast RCNN、Faster RCNN、Mask RCNN)、YOLO系列(YOLO v1、YOLO v2、YOLO v3)以及SSD,从去年开始涌现了一些anchor-free的工作,在ECCV 2018上出现了一个工作——CornerNet,提出了一个想法——把目标检测问题转换成关键点检测问题,之后涌现了CenterNet、ExtremeNet等一系列基于关键点的目标检测工作。最近谷歌有一些NAS和目标检测的工作,以及用强化学习的方式选择数据增广策略(近期我会复现该论文的数据增广策略)。
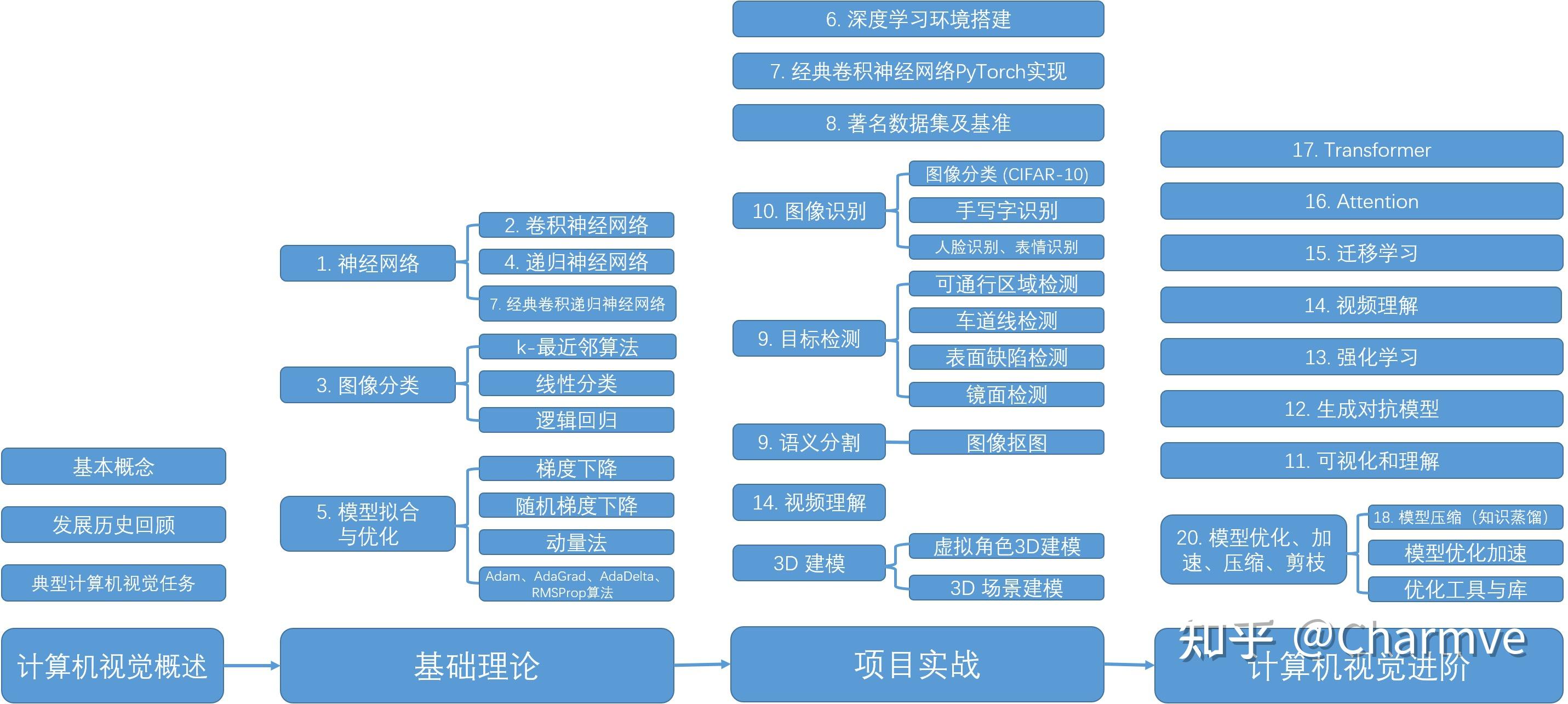
像分割任务,是像素级的分类问题,同样也有传统方法和深度学习方法,深度学习比较经典的方法是FCN,输出大小和输入大小应该是一致的(这里大小是长宽)。目标追踪任务和检测任务有一些相似,但有一些不同之处,对每一帧进行检测的效果和追踪十分类似,但是目标检测通常检测的是已知类别,追踪可以追踪给定的第一帧里的内容,有一些传统方法、相关滤波方法以及深度学习方法,比如孪生网络系列的文章。再衍生出来的话,还有Re-ID。除此以外,还有很多很多计算机视觉任务,比如超分辨率、三维重建(还涉及计算机图形学等),由于篇幅有限就不一一介绍这些任务的基本发展了,可以找一些论文自己研读,注意不仅仅是最近的文章,还有上个世纪的文章,最好写个综述,看个几十上百篇文章,读读代码。
有一些计算机视觉、深度学习方向的课和书籍,比如 @李沐 老师的《动手学深度学习》,有课有jupyter notebook,非常好,相见恨晚,还有花书《深度学习》、《计算机视觉:算法与应用》、《计算机视觉——一种现代方法》、《计算机视觉:模型、学习和推理》等。课的话,可以看cs231n,非常经典的计算机视觉课程,cs224d,虽然这门课是nlp的课,但是RNN这些东西对时间序列建模有非常大的帮助,可以也关注一下。最近需要的关注的还有GNN paper list,用图的思想去处理一些计算机视觉问题,以及CV和NLP结合还有一些任务,比如很早之前就有的VQA、caption等,这里有一篇论文可以参考一下,Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods。
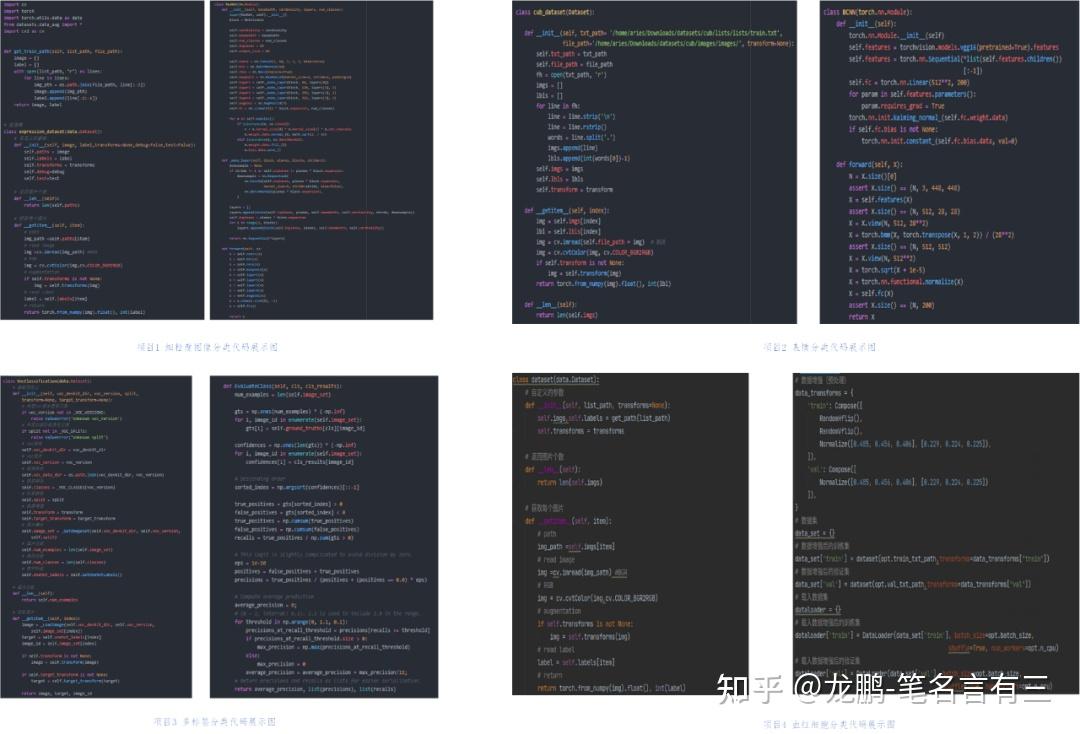
除此以外,代码能力也非常有必要。无论是传统的数字图像处理还是图形学,最近我就在看一些图形学的算法并打算逐一实现,还是深度学习方法,都需要有一定的代码能力,平时多看看别人写的代码,学习一下,最近我就复现了一篇ECCV 2018的文章HairNet,相对我之前的代码就非常工程化,也便于在其他设备上进行使用。传统数字图像处理使用matlab比较多一点,图形学使用C++多一点,深度学习时代的一些代码主要基于python,还有一些深度学习框架,例如pytorch、mxnet、tensorflow、caffe、darknet等,目前这几种都或多或少地使用多,安利前面两种,pytorch目前也是比较主流的框架了,mxnet可以基于李沐大大那本书就学习,对理解底层的代码比较有帮助,我就是通过那个代码理解dataloader具体是怎么实现的。
“快速”二字,我不知道该如何体现,这个因人而异吧,笨鸟先飞,勤能补拙,好好学习总是会有收获的,提升是不知不觉之中的,就像我不知不觉之中就从NLP、KG圈就跑去搞CV、CG了(滑稽脸.jpg)。
那讲了这么多,也是我对计算机视觉领域的理解,我将这些内容从一个初学者的角度设计了一个闭环学习框架,面向实际业务场景,通过工程能力的将计算机视觉这一学习任务处理成为一种在线学习反馈的体验。
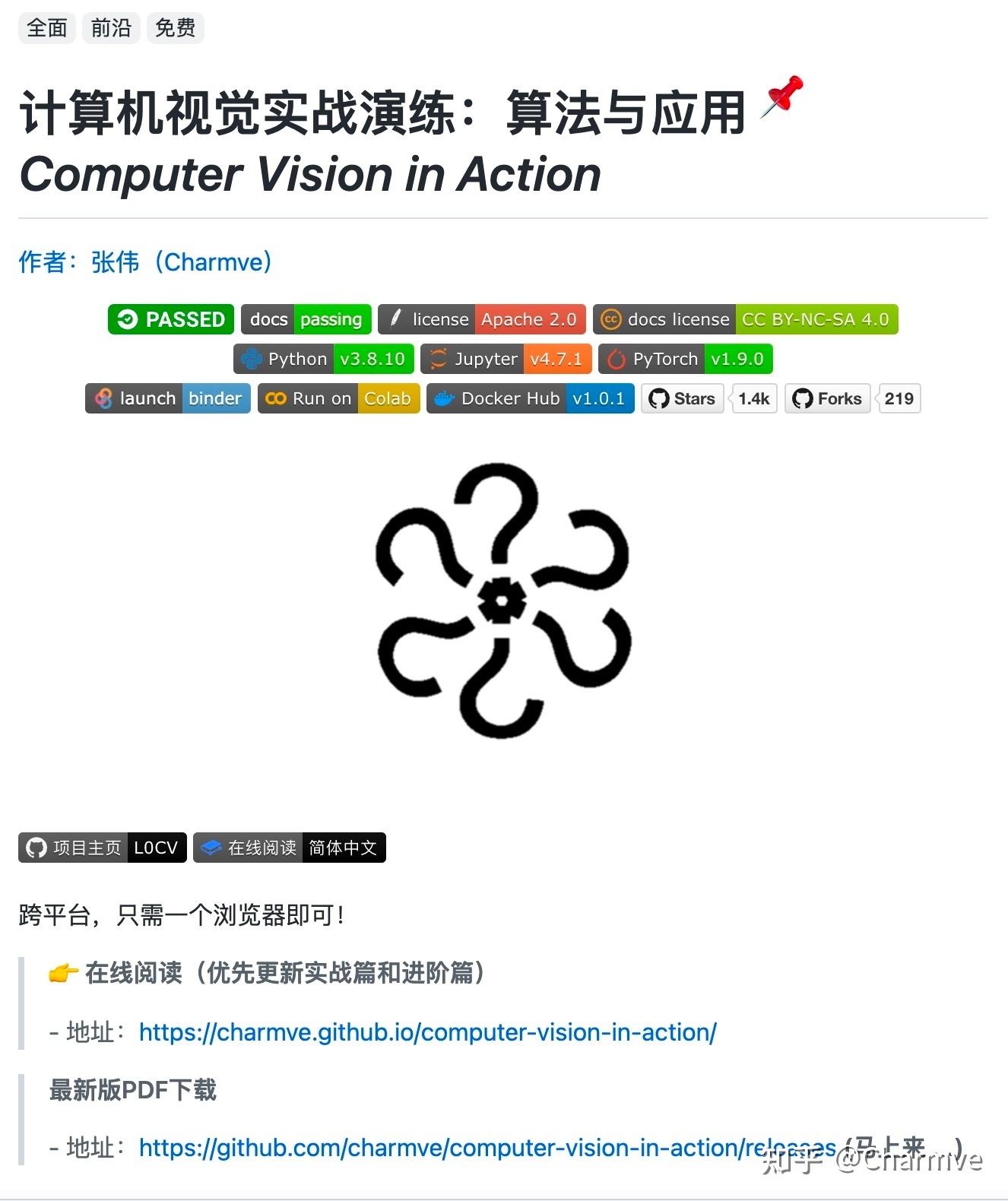
在我们开始写这本书的时候,没有资源能够同时满足一些条件:
- (1)是最新的;
- (2)涵盖了现代机器学习的所有领域,技术深度丰富;
- (3)在一本引人入胜的教科书中,你可以在实践教程中找到干净的可运行代码,并从中穿插高质量的阐述。
我们发现了大量关于如何使用给定的深度学习框架(例如,如何对TensorFlow中的矩阵进行基本的数值计算)或实现特定技术的代码示例(例如,LeNet、AlexNet、ResNet的代码片段),这些代码示例分散在各种博客帖子和GitHub库中。但是,这些示例通常关注如何实现给定的方法,但忽略了为什么做出某些算法决策的讨论。虽然一些互动资源已经零星地出现以解决特定主题。例如,在网站Distill上发布的引人入胜的博客帖子或个人博客,但它们仅覆盖深度学习中的选定主题,并且通常缺乏相关代码。另一方面,虽然已经出现了几本教科书,其中最著名的是:cite:Goodfellow.Bengio.Courville.2016(中文名《深度学习》),它对深度学习背后的概念进行了全面的调查,但这些资源并没有将这些概念的描述与这些概念的代码实现结合起来。有时会让读者对如何实现它们一无所知。此外,太多的资源隐藏在商业课程提供商的付费壁垒后面。
我们着手创建的资源可以:
- (1)每个人都可以免费获得;
- (2)提供足够的技术深度,为真正成为一名应用机器学习科学家提供起步;
- (3)包括可运行的代码,向读者展示如何解决实践中的问题;
- (4)允许我们和社区的快速更新;
- (5)由一个论坛作为补充,用于技术细节的互动讨论和回答问题。
这些目标经常是相互冲突的。公式、定理和引用最好用LaTeX来管理和布局。代码最好用Python描述。网页原生是 HTML 和JavaScript的。此外,我们希望内容既可以作为可执行代码访问、作为纸质书访问,作为可下载的PDF访问,也可以作为网站在互联网上访问。目前还没有完全适合这些需求的工具和工作流程,所以我们不得不自行组装。我们在 :numref:sec_how_to_contribute 中详细描述了我们的方法。我们选择GitHub来共享源代码并允许编辑,选择Jupyter记事本来混合代码、公式和文本,选择Sphinx作为渲染引擎来生成多个输出,并为论坛提供讨论。虽然我们的体系尚不完善,但这些选择在相互冲突的问题之间提供了一个很好的妥协。我们相信,这可能是第一本使用这种集成工作流程出版的书。
在实践中学习
许多教科书教授一系列的主题,每一个都非常详细。例如,克里斯·毕晓普(Chris Bishop)的优秀教科书 :cite:Bishop.2006 ,对每个主题都教得很透彻,以至于要读到线性回归这一章需要大量的工作。虽然专家们喜欢这本书正是因为它的透彻性,但对于初学者来说,这一特性限制了它作为介绍性文本的实用性。
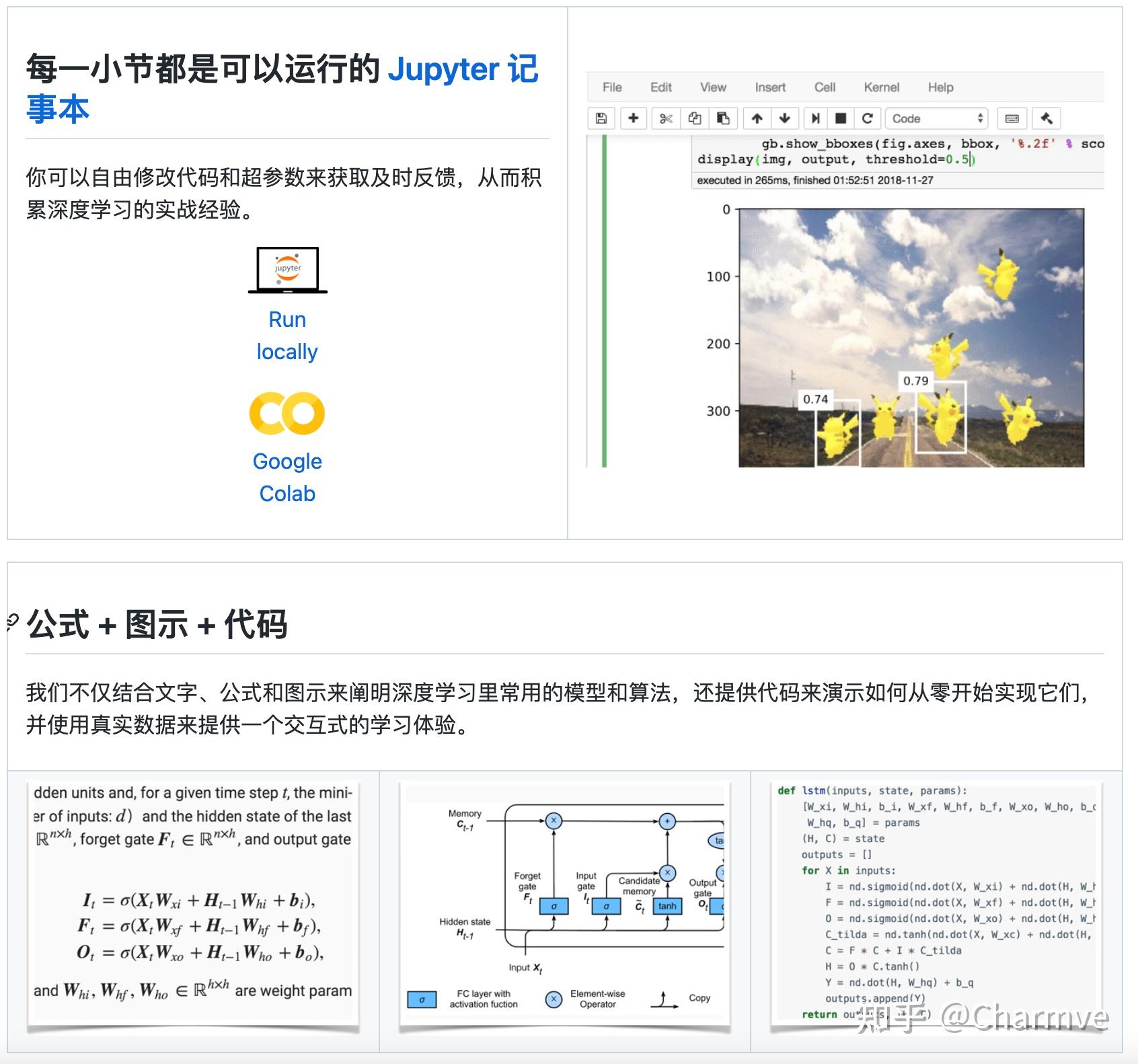
本项目已经发布就收获了大量关注,持续登陆GitHub中文榜前三。
<hr/>最近一些经历给我一些感触,传统的一些数字图像处理方法还是必不可少的,数学上很fancy,实际上可能也比较work,同时兼具解释性等特点。入门计算机视觉,或者其他任何一个学科/领域,脚踏实地比较好,切不可建空中楼阁。
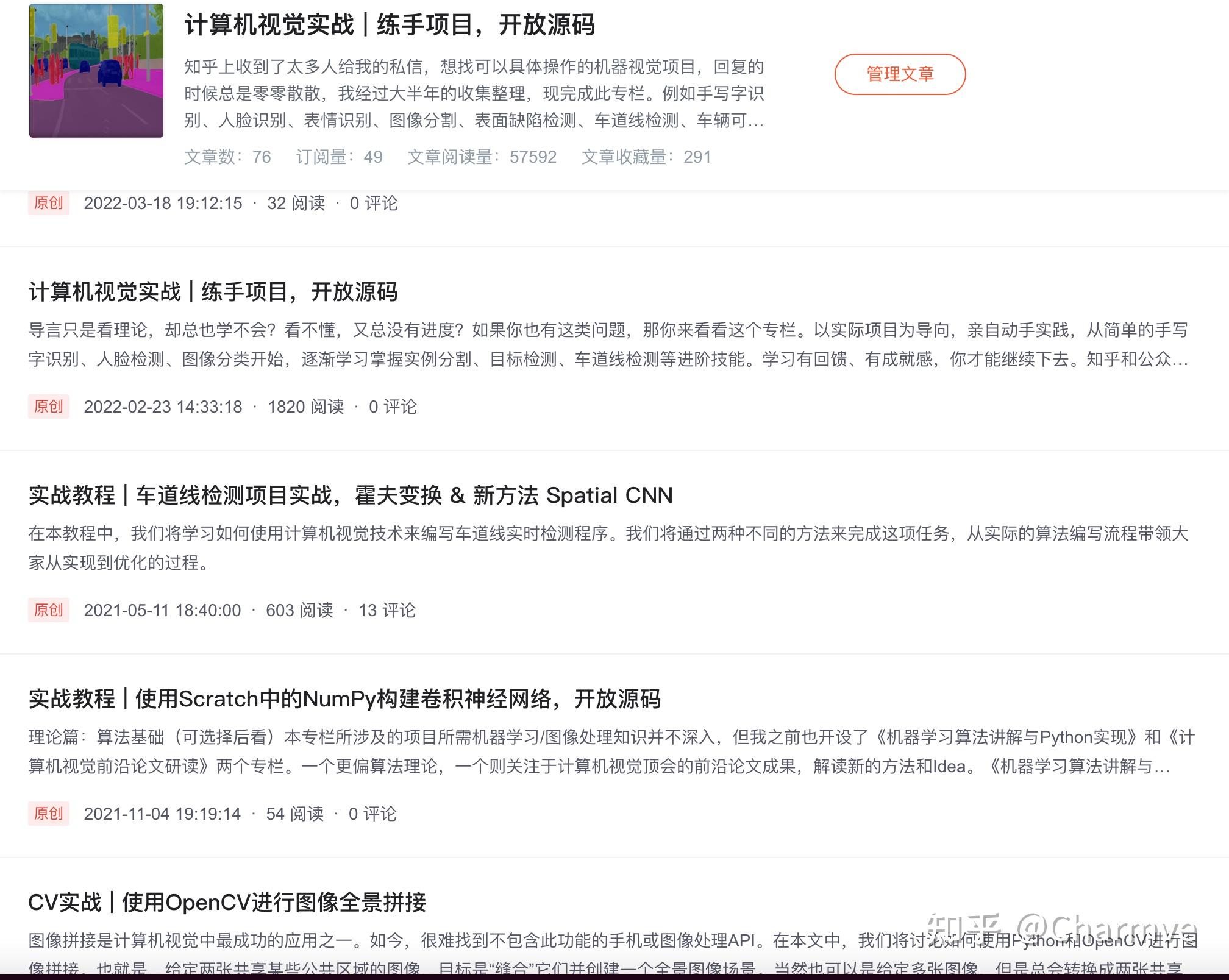
推荐个人计算机视觉实战专栏:
https://blog.csdn.net/charmve/category_10595130.html
 |