NLP已经死了 NLP社区可以大致分为两个group: 一种是相信AGI的,一种是不相信的。
对于前者来说,LLM的兴起当然是极其令人兴奋的。之前的NLP模型对他们来说基本全是玩具,而LLM才是通往AGI的正确道路。 他们会高呼生在这个时代极其幸运,并且all in LLM research。这无疑是正确的方向之一,如果你对LLM有兴趣,野心和激情,那么all in LLM也是一个很不错的选择(如果有计算资源)。 我摘录一些dalao对LLM未来研究的建议(侵删)仅供参考:

某dalao的建议
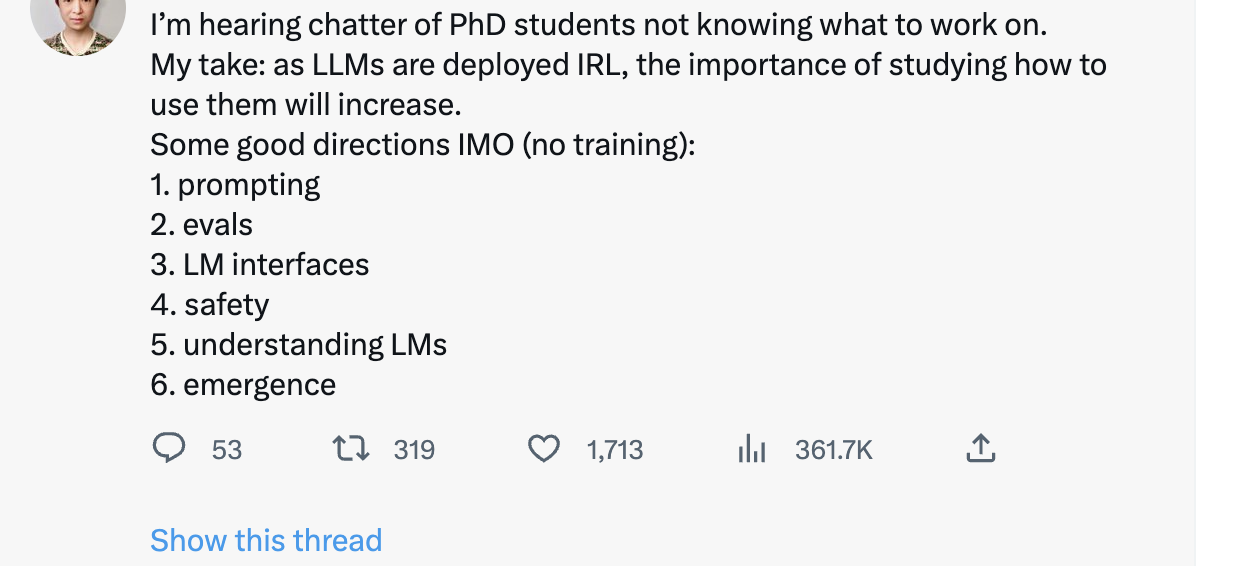
某LLM教父的twitter
可是对我来说,(API-driven or prompt-driven or ..) LLM research只能让我感到无聊,并不能让我感到兴奋,所以我润ML了,非必要不投*ACL(NLP润ML人快来私戳,乐)。(Update:润了,但没完全润,还是准备做点scale up一些非attention架构的work的)
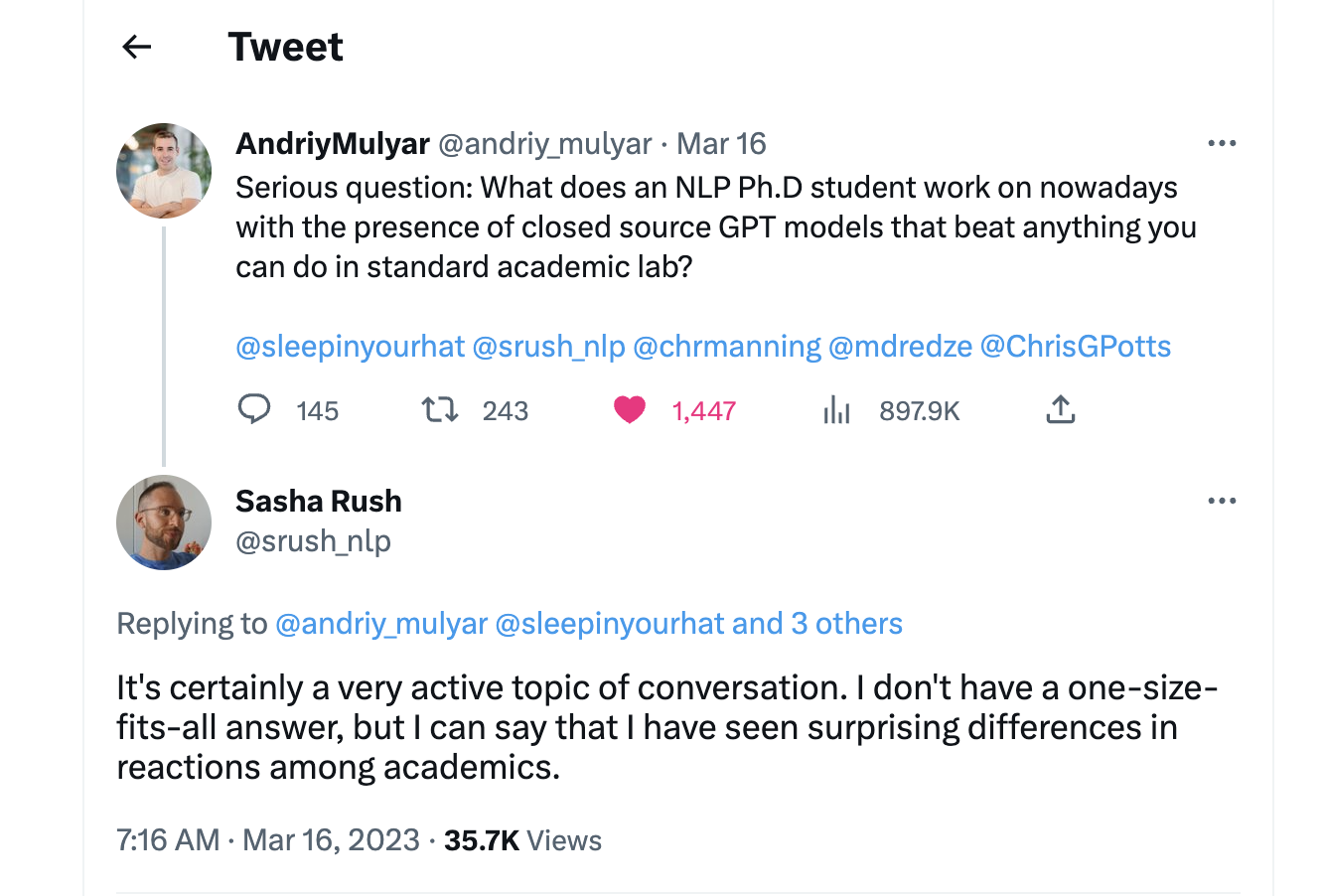
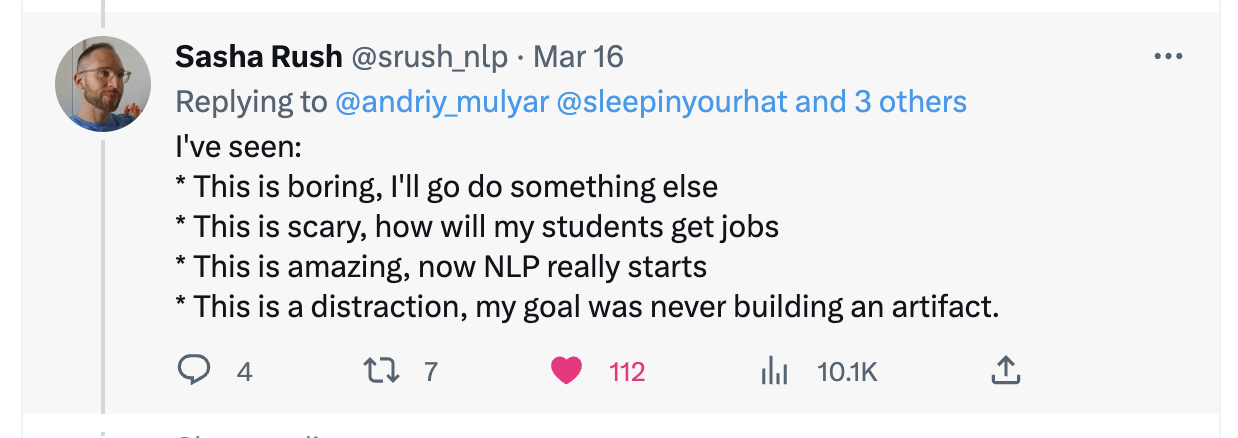
我属于第一类
后者的很多人应该像我一样对LLM的research感到无聊,毕竟整个学科在越来越工程化。如果还打算继续留下来做NLP research的,就需要好好想想如何说服自己,自己做的研究是有意义的。毕竟骗审稿人容易,骗自己难,做自己都认为没价值的research还有什么乐趣呢?在LLM的边边角角继续打不痛不痒的补丁,然后被GPT的下一个版本薄纱,那这样,存在主义危机 (existential crisis) 就会像幽灵一样阴魂不散。
因为我是做Parsing的,所以我很早之前就体会到现在许多人才体会到的心情(See 为什么研究NLP句法分析的人不多? - sonta的回答 - 知乎 https://www.zhihu.com/question/489981289/answer/2148458380) 。就算没有LLM,在其他的比较强的神经网络里面,句法信息也是可有可无的。所以单纯做句法这个方向从实用的角度来看基本上可以说是毫无意义的,跟现在在LLM时代做其他NLP任务一样。 那么我是如何说服自己做的呢?那当然是好玩。Parsing argubly是NLP最有意思的方向(从算法的好玩的角度来看)。现在的Parsing track已经大约有一半的work干脆实验都不做了,直接纯理论分析向(感谢Jason Eisner, Ryan Cotterell),就讲究一个好玩,乐。Parsing这种偏理论的方向至少还能玩玩理论,那么其他更加应用的方向呢?我不知道。反正我感觉没啥好做的。
举Parsing的例子主要是想说,Parsing领域的今天就是很多NLP子领域的明天。NLP很多dalao都是做Parsing起家,那他们为什么现在不做了呢?因为Parsing is almost solved,他们当然转向了其他更有前景的,unsolved的NLP子方向。而如今在LLM时代,NLP整个领域面临solved,很多中间任务几乎没有存在的价值,
ChatGPT 印证了模型大一统的可行性,这在未来五年会对 NLP 从业者带来怎样的冲击?张俊林:通向AGI之路:大型语言模型(LLM)技术精要甚至直接面向应用(e.g. 翻译 润色 纠错 etc)的任务都面临直接被GPT系列薄纱的危机, 那么小润润parsing,大润或许可以考虑润出做纯NLP的research,例如跟我一样润ML,或者做一些NLP与其他学科的交叉,

当然,你也可以跟着Neubig一起去做保护环境(狗头
 |




