看了下问题日志,2021 年初提的,当时我是刚转入这一领域。转入前我自己的感受:的确人挺少的。但这一年多来的经历,让我发现,做这一行的人还是很可观的,有以下几方面的因素改变了我的认知:
技术层面
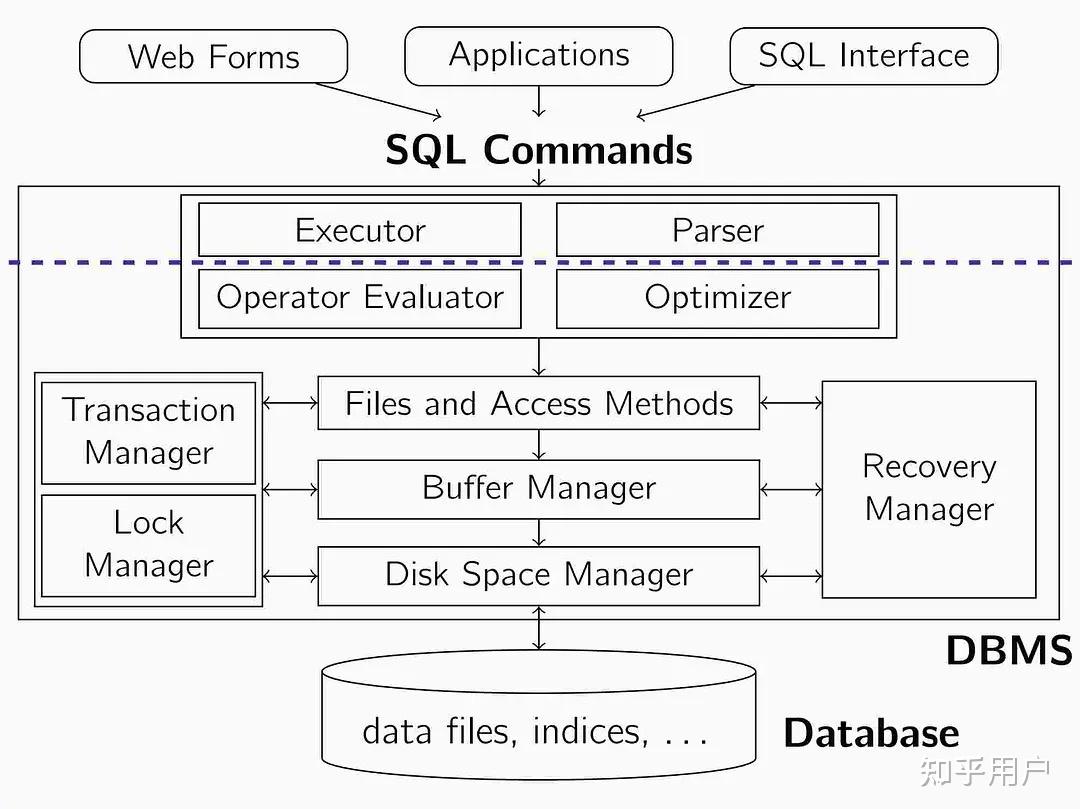
技术层面数据库内核开发可以粗分为查询引擎和存储引擎。前者负责将查询语句经过词法分析、语法分析、执行优化、执行等步骤生成执行计划发给存储层;存储层一般采用简单的 KV 模型,负责最终数据的存储和读写。
在分布式时代,两层又会分别和分布式技术相结合。查询层结合有类似 MPP 的多机计算(如 CRDB),存储层结合就是使用分片对数据分而治之、使用多副本保持每个分片的高可用、使用共识协议让多副本达成一致。当然,还有纵跨两者的场景——计算下推,将本来属于查询层的计算,推到不同的存储节点,进行分布式计算,现在主流 NewSQL (如融资额前三的数据库:CRDB、TiDB、Yugabyte 都走的开源路线)都有实现。
业态层面
我自己在入门时,主要受几个学习资料影响比较大:
- 一本书:DDIA
- 两门公开课:MIT 的 6.824 和 CMU 的 15-445
- 知乎:关注了很多分布式和数据库相关优质的答主(随手写,不分先后):henry liang,BohuTANG,Ed Huang,drdr xp,fleuria,codedump,Bowen Xiao,satanson,KDF5000,丁凯,杨东东,暗淡了乌云,付哲,郁白,申砾,张友东,温正湖,郭宽,谭新宇,孙挺Sunt,迟策,欢歌,不想说 ,一只硬核少年等等。
刚开始在学的时候也缺少一些讨论,于是组织了一个 DDIA 读书会,并建了一个数据库相关中文论坛。通过这些组织,也认识了不少朋友,并了解到一些还在学校的同学的状态。
资本层面
2021 年及以前,就国内而言,资本大量涌入,造就了大量数据库创业公司,我之前一个在 v2ex 的帖子简单列举过一些随手找的融资状态:

政策的倾斜(国产化替代)、资本的涌入造就了大量的岗位,从而导致很多从业人员转进数据库赛道,同时也激励大量还在校同学投入相关方向。
当然,后来的故事我们都知道,2022 年,由于国内国际上各种因素叠加,资本退潮,而尚在存续的数据库公司也尚无找到一个足够粗壮的盈利方式。半年之内,可以从各方面传递来的信号粗略感到,数据库内核人才从供不应求突然就供大于求,很多群里和论坛上的小伙伴开始踟蹰,质疑数据库赛道的前景。(当然,二八原则,真正有实力的人是不受影响的)
小结
回到问题本身,现在来看,数据库内核开发处于一个严重错配的境地:
- 从供给侧:喜欢 infra 的社招同学持续转进、前两年数据库方向的学生开始毕业,造成供大于求。
- 从需求侧:由于资本紧缩,盈利模式不明朗,财务状况吃紧,导致企业 bar 提高不少,也是招不到合适“性价比”的人才。
但我相信,在这个产业信息化不断加深的时代,对于数据存取的需求一定是持续增长的,至于会不会落到数据库上,还是会有其他表现形式,其相关的底层技术不会变。一时的寒冬,可能会吓走投机者,但真正喜欢这一块技术的同学,蛰伏过后,必有将来以待。
最后,欢迎明知山有虎的同学来我们的分布系统&数据库论坛来讨论,让我们把火种延续下去。
分布式系统 & 数据库 |