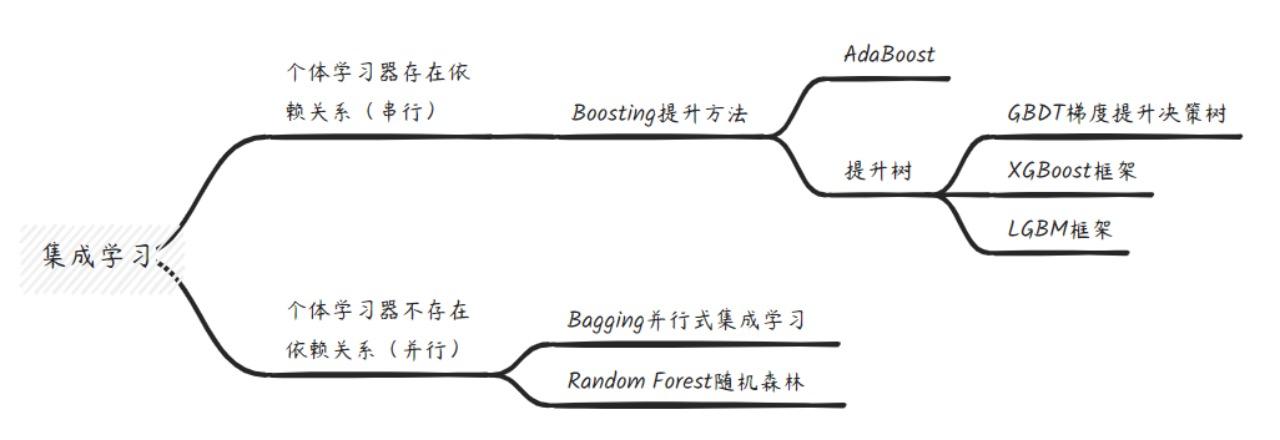
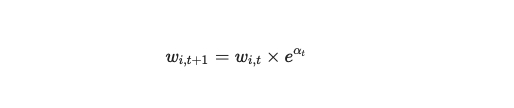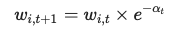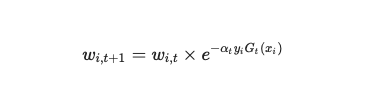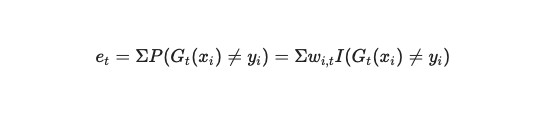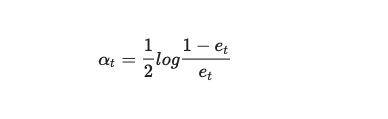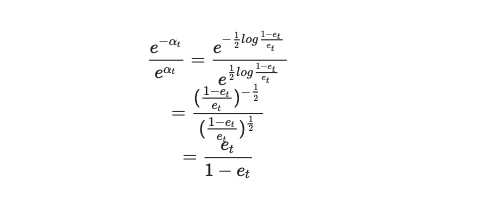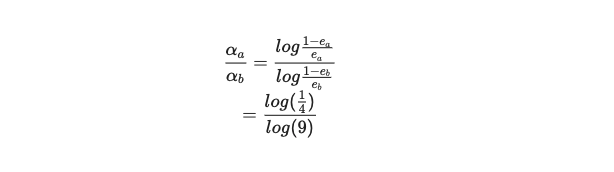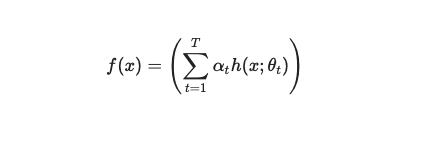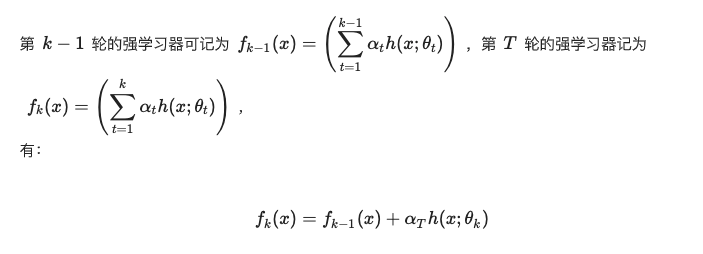先把数据分析,机器学习,人工智能等这些概念搞清楚,就知道要学什么,以及从哪开始学起了。
数据分析,机器学习,深度学习,人工智能的关系我画了这张图
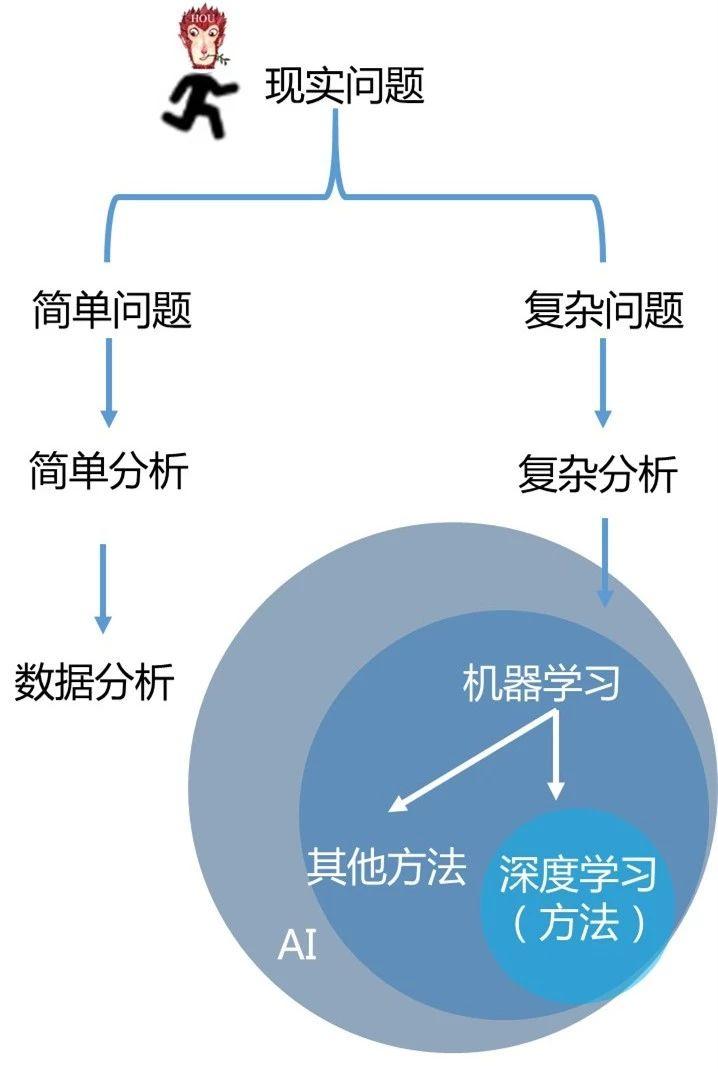
我来解释下这张图。
一切技术的出现都是为了解决现实问题,而现实问题分为简单问题和复杂问题。简单问题,需要简单分析,我们使用数据分析。复杂问题,需要复杂分析,我们使用机器学习。
如果在看这个问题的你对数据分析感兴趣,推荐参加知 乎的【前 IBM 数据分析大咖 3 天实战训练营】,一线互联网大厂大牛带队,直播互动讲解互联网数据分析工作流+常见分析模型运作原理,还有大厂真实案例带练实操,打破简历 0 项目经验!升职加薪指日可待!现在参加还有最新 Excel 自学手册 1-6 部免费赠送,数量有限,先到先得,有需要的点击卡片即可:
1、什么是简单问题?
比如公司领导想知道每周的销售情况,这种就是简单问题。简单问题可以用数据分析来处理,通过分析数据来分析出有用的信息。
最简单的,你用 excel 分析一家淘宝店铺的销售数据,每周公司会让你出一份周报一份发现了最近几个月销量下降,然后根据分析产生销量下降的原因是什么,找到原因后制定对应的策略来提高销量。
我们来看一个真实的案例。全球最大的旅行房屋租赁社区 Airbnb 曾在 2011 年纠结于新用户增长的缓慢,有一天,他们的数据分析团队发现房源照片的精美程度,跟房源的预定人数成很大的正相关。
于是,他们提出一种假设,即「附有专业摄影照片的房源要更抢手,因此房主肯定会愿意申请 Airbnb 提供的此项服务」。
他们迅速上线了一个提供专业摄影照片服务的版本,然后跟原版本做 A/B Test,发现同一个房源,使用专业摄影服务的比不使用的多了 2-3 倍的订单量。
2011 年后期,Airbnb 雇用了 20 名专业摄影师,以帮助平台上的房主拍摄房屋照片,几乎在同一时间段,Airbnb 的订单量曲线有了一个陡峭的增长。

2、什么是复杂问题?
比如我们天天使用的淘宝,它会根据你的历史购物习惯(数据),来给推荐你可能感兴趣的商品。淘宝是如何做到的呢?对于这种复杂问题,淘宝背后使用的就是机器学习。
我再举个例子,今日头条是如何靠机器学习逆袭成为新闻客户端老大的。
2010 年前后,门户时代崛起的网易、搜狐、腾讯三巨头向移动端转型,几乎垄断了当时的新闻客户端市场。而仅仅 2 年后,今日头条,使用「机器学习」这把屠龙刀向用户个人性化推荐用户感兴趣的新闻,一举打破巨头垄断,成为新闻客户端老大。虽然,后来腾讯和网易为了对抗头条,推出了类似的产品的天天快报和网易号,但因起步晚和算法不成熟,都失败了。
下面图片是我在知乎一个问题下回答的传播分析报告

在这份报告中,像点赞数、评论数、收藏数、总阅读量这样的分析就是简单分析。像「你可能感兴趣的人」这样的分析,就是复杂分析,需要通过机器学习算法来找到,类似于豆瓣上给你推荐感兴趣的电影、淘宝上给你推荐感兴趣的商品。
3、什么是深度学习?
机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
深度学习在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。我说个例子,你肯定听说过。那就是 2016 年谷歌旗下 DeepMind 公司开发的阿尔法围棋(AlphaGo)战胜人类顶尖围棋选手。阿尔法围棋的主要工作原理就是「深度学习」。

4、什么是人工智能?
人工智能,它的范围很广,广义上的人工智能泛指通过计算机(机器)实现人的头脑思维,使机器像人一样去决策。
机器学习是实现人工智能的一种技术。所以我把人工智,机器学习,深度学习放到不同的圆圈里,他们三者是包含的关系:
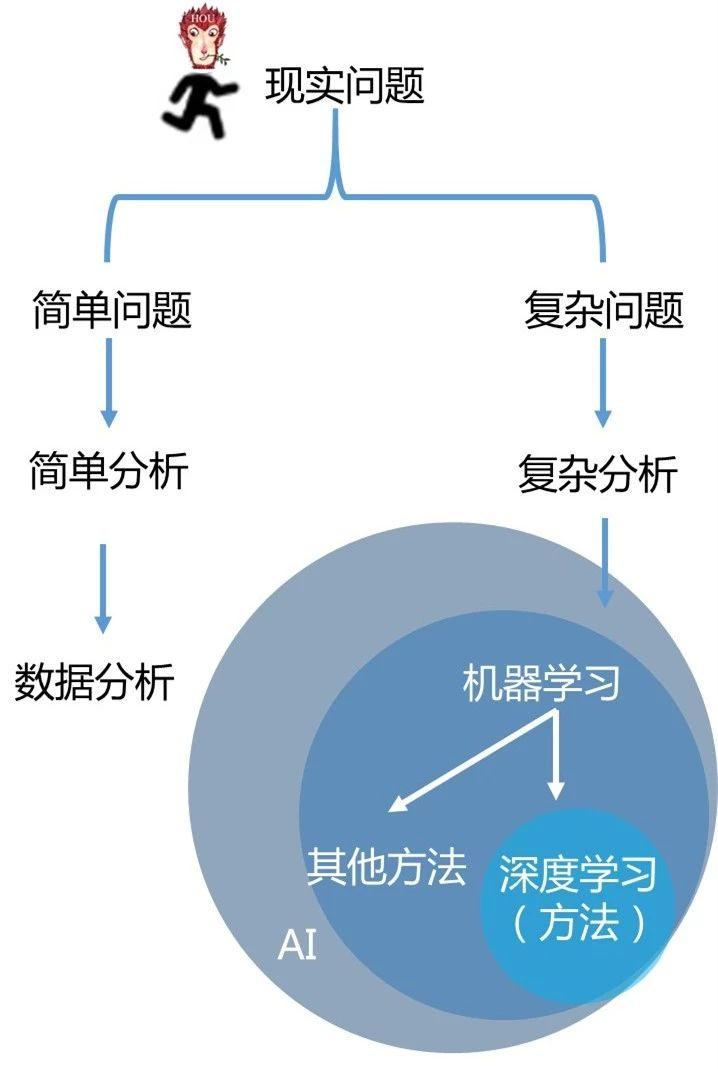
现在,你已经清楚了数据分析、机器学习、深度学习这些概念的关系了。当我们从解决现实问题的角度来看,很多概念会清楚。处理不同的问题,使用不同的方法。
5、数据分析与人工智能的关系?
你可能会问了:「上图中没看出数据分析和人工智能有什么关系呀,是不是学习数据分析没什么用?那我是不是一开始就学习机器学习了,这样可以直接进人工智能时代,享受时代红利了?」
这么想是不对的。
机器学习是很多学科的知识融合,而数据分析是机器学习的基础。只有学会了数据分析处理数据的方法,你才能看懂机器学习方面的知识。这就好比,你想上初中(机器学习),必须先读完小学(数据分析)才可以。
所以,我在下面图片中画了两条黄色的线,表示数据分析的两个方向,如果你喜欢深入技术,学会了数据分析,你才能打好基础,去学习机器学习。如果你喜欢商业方面的内容,可以往人工智能业务方向发展。
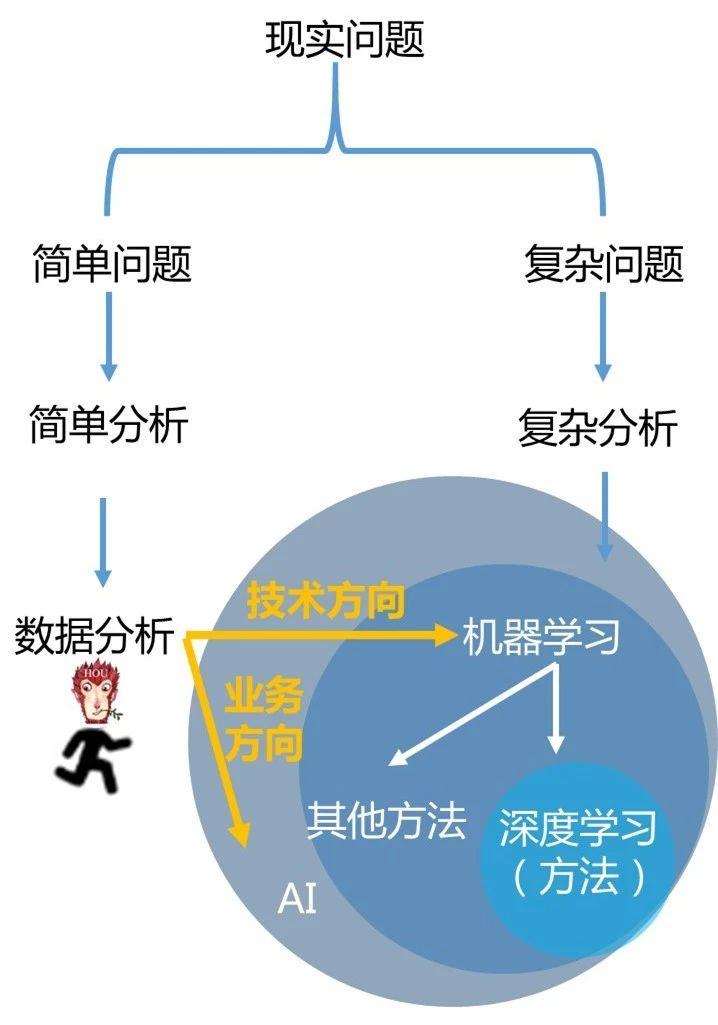
职业社交网站领英在《2018 新兴工作岗位报告》中说,2018 年,15 个新兴职位里有 6 个与人工智能相关,这说明,与人工智能相关的技能开始渗透到各个行业,而不仅仅是技术行业。
领英把人工智能技能定义为:开发和有效使用人工智能工具和技术的技能。这是领英上增长最快的一个技能,从全球来看,2015 年到 2017 年这个技能增长了 190%。
之前很多人本来就是零基础,却买来一堆机器学习的课程和书来学习,最后看的是晕头转向,觉得自己不适合。
其实,这是走错了路。如果你是零基础,想进入人工智能这个相关的职业,要先从数据分析开始学起。
6、总结
1)人工智能是指使机器像人一样去决策
2)机器学习是实现人工智能的一种技术
3)机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
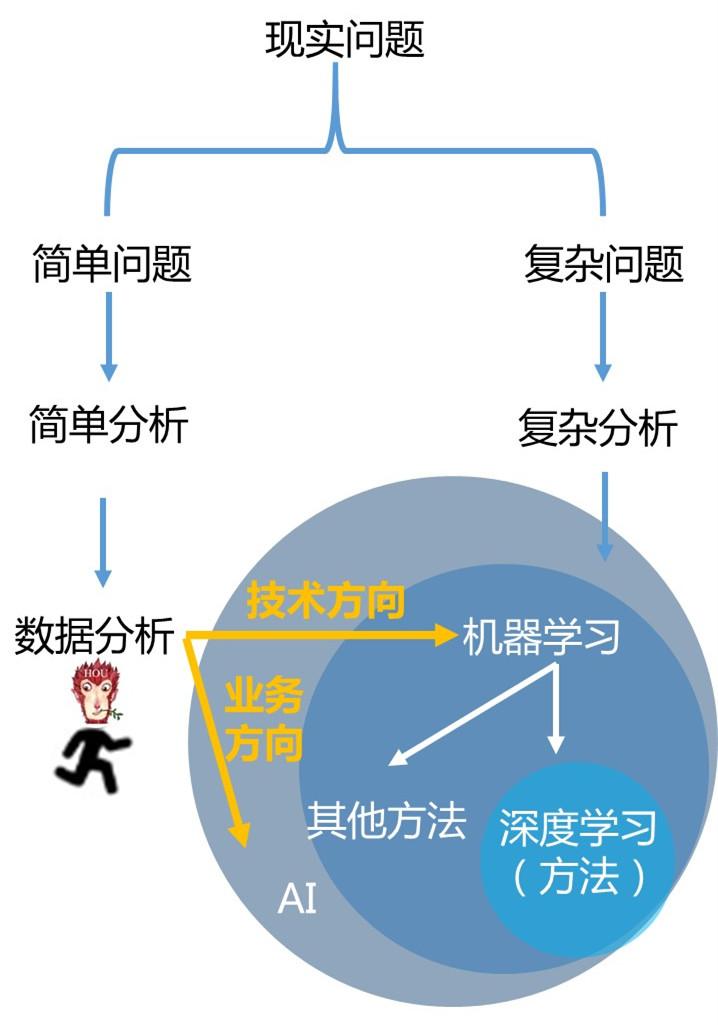
4)数据分析可以帮助你从零进入人工智能时代。如果你喜欢深入技术,学会了数据分析,你才能打好基础,去学习机器学习。如果你喜欢商业方面的内容,可以往人工智能业务方向发展。
5)下面这张图是它们之间的关系
7.如何学习?
了解了这些基本概念以后,你就知道了应该从哪开始学习了。建议时间紧张的朋友看我总结好的视频课版本,节省时间精力。3 天时间,分析工具带练+模型结构拆解+大厂案例实战,能力深度对标阿里 P6+,可以帮助大家系统性地掌握数据分析技能和提升数据分析思维,实现升职加薪梦!
原文作者:猴子
使用 App 查看完整内容目前,该付费内容的完整版仅支持在 App 中查看
<a href="http://oia.zhihu.com/answer/2819570634/" class="internal" style="color: #0084FF;text-decoration:none;border-bottom:none;">🔗App 内查看 |