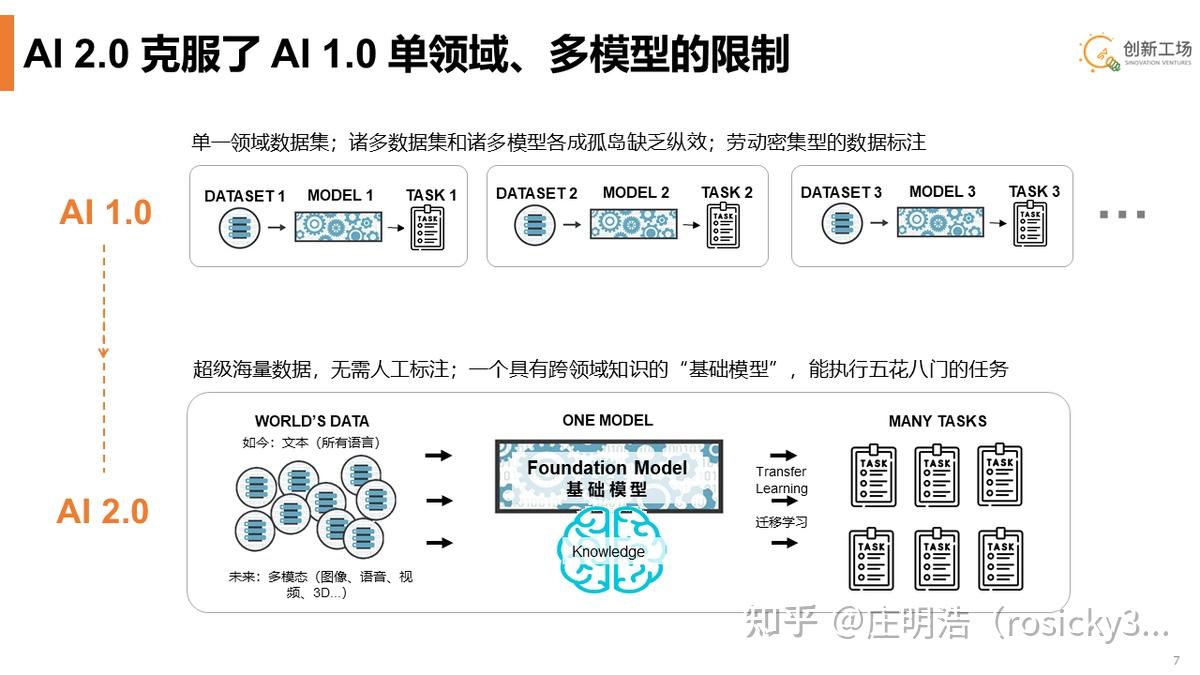
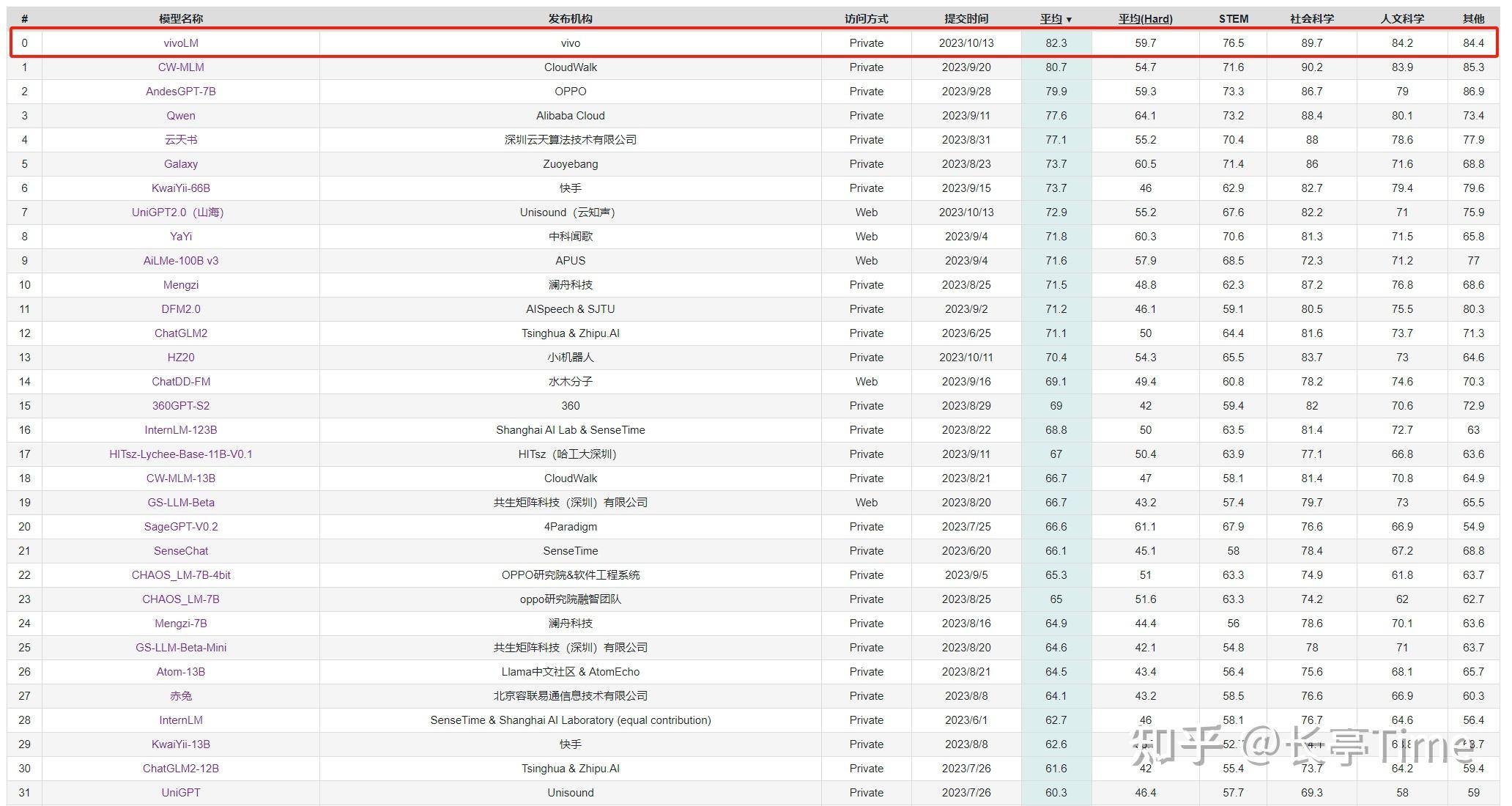
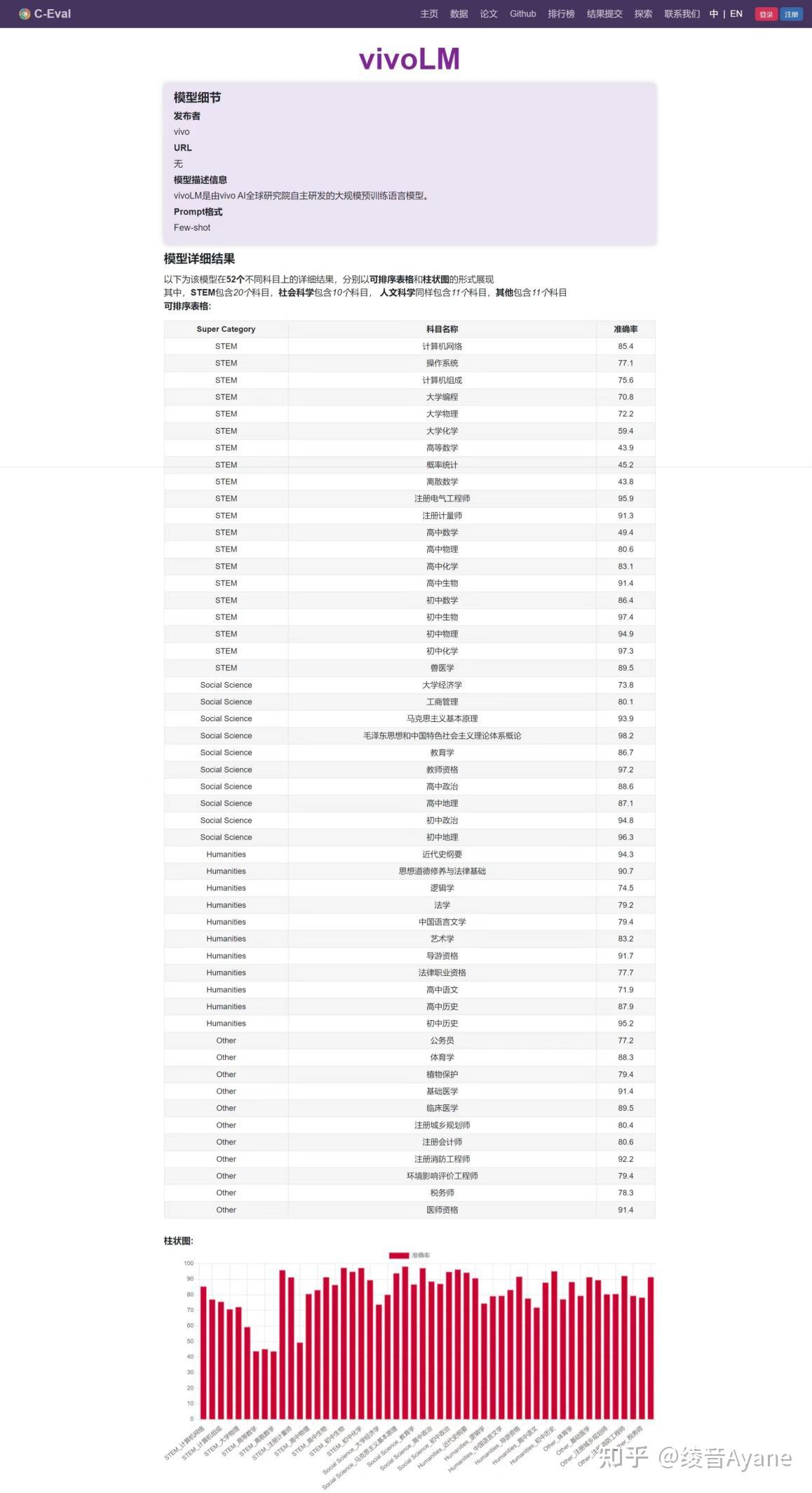
简单说说vivo的大模型排名第一的这个C-Eval,这不是一个商业性的排行榜。C-Eval由上海交通大学、清华大学、爱丁堡大学共同搭建,是目前相对权威的多层次多学科中文大模型评测基准。此前知乎上已经有一些科普,大家感兴趣也可以去他们的官网看看。
https://cevalbenchmark.com/vivo一个做手机的公司,怎么就一门心思干起了大模型呢?其实早在2017年vivo就已经组建了人工智能全球研究院,经过这几年的持续扩充,目前已经有600人以上的规模。但vivo一直都是强调本分,很多正在做和没有做成的事情都很低调在处理,所以外界也没有太多关注。
ChatGPT大火之后,可以说是大模型的一个“催熟剂”,而vivo的多项底层建设工作也初见规模,所以这次才有了加持在OriginOS 4上的发布。手机厂商和互联网厂商都在纷纷宣布进军大模型,其实就是在抢夺下一个十年的入场券。
如果说智能手机第一个十年的技术赛道是影像和性能,那新十年的赛道将会是AI和大模型的云端协同及应用。而中国手机品牌,必然是新十年智能手机技术竞争的主导者。
这话听起来是不是觉得不靠谱?但这就是事实。
倒退五年,谁要给你说中国汽车品牌将会是新能源汽车时代的全球主导者,你同样也觉得这是天方夜谭,异想天开。但中国这个全球最大的单一市场主体,加上数量庞大的科技工程师队伍,具备了技术创新时代全产业链所需要的各项有利条件,从而在全球科技创新市场中扮演着极为重要的角色。
暂别宏大叙事,我们今天聚焦用户视角,聊聊用户关心的话题——OriginOS 4上所搭载的大模型对vivo以及整个智能手机行业将会带来哪些新的技术创新可能性?
智能手机如何新生?
每一个产品和技术,都是有生命周期的。不管他曾经多么辉煌,都无法避免走向衰败甚至消亡的那一刻。而手机,则是将这一“丛林法则”演绎得最为淋漓尽致的行业。全球范围内,从功能机延续到智能机的厂商只有一家。而功能机从出现到彻底退出,大概就是十余年的时间。参考这个规律周期,留给这一代智能手机的时间也不多了。
换机驱动减弱,换机周期延长,其实就是技术创新的边际效益日渐稀薄。影像、性能、设计、充电、系统……能卷的都卷了一遍,大家的焦虑日趋严重,都在为找寻新的船票日思夜想。
机会从来都是留给有准备和敏锐洞察力的少数人,AI大模型的出现及火爆,让智能手机厂商们隐约看到了新的曙光。智能手机的前一个十年,完成了初级智能阶段的基础建设,不管是影像还是性能,更多是需要用户的主动操控,手机软硬件系统再通过算法的理解来输出合适的结果。比如影像的多帧合成HDR,游戏的智能帧率稳定等等。

大模型的兴起和成熟,则引领智能手机开始变得有了更有深度和难度“思想和思考”。当用户对其输入一段复杂的需求语音,手机系统触发的不再是单一的简单指令执行,而是由多项工作内容组合的复杂工作体系。这个工作体系可以是你未来一周的旅途安排,也可以是你要向上司汇报的工作总结,甚至可以是将你拍摄的合影挑选每一个人最佳状态生成最理想的一张。有了大模型加持的智能手机,在新的技术周期内必定将“人机合一”的蓝图描绘得更加详实生动。
对于新技术的初级阶段,大部分人都是质疑和否定的。正如作为摄影发烧友的我,当年初初看到手机能拍照时,一样是嗤之以鼻:就这?但经历了十余年技术迭代之后,今天的移动影像已经在多数的消费级场景中完全胜任。智能手机降低了用户的影像使用门槛,助推了社交媒体图片化和视频化的全面升级。
而大模型所助推的全面AI化,融入智能手机后,今天我们觉得难于上青天的很多技术壁垒,在未来都会被逐一击穿。
大模型加持的智能手机会是什么样?
每次谈到未来的新技术发展,总会伴随着一句千古不破的名言:理想很丰满,现实很骨感。当我们在畅谈大模型带给智能手机更广阔的技术空间时,一定会有人站出来吐槽:别扯那么远了,先把现在手机上的语音助手“智障化”解决好吧。
其实……大模型加持的目的之一就是来“清障”。
我们为什么不爱用语音助手?每次对话都需要复读唤醒关键词是其一,其二是系统对略微连续性和复杂的多样化指令会瞬间崩溃,完全不知道应对,其三是需要很清晰精准的关键词才能激活系统,模糊化接收指令的能力很弱。

而这些所有槽点的背后,其实都指向一个相同的软肋——只有大数据,没有大模型。如果我们把人工智能系统看做是一个小朋友,那他一直都只是在做10以内的加减法,即使他一天到晚做了无数道题,可始终就是停留在这个能力范围内。而超过10的加减法甚至是乘除法,他确实就是不会。如果这是活生生的人,他的脑力会成长,会通过得到训练,逐渐学会难度更大的算法。但早年间的手机软硬件系统,将有限的资源都投入到了影像和性能的需求中,所以即使每天有海量的数据进来,但在系统化的大模型训练这部分,成长性是滞后的。
大模型加持后的语音助手,不再是由关键词触发对应的指令。而是根据你提出的需求进行一整套的分析、运算和输出。举个简单的例子:过去我们给手机助手说:给我一杯水。他就只晓得给你一杯水。但如果有了大模型的加持之后,他可能会结合当时的气温、你的身体指标,你是否有运动过等等,再来问你:你是需要热水还是冷水?是否有多少温度的需求?需要500毫升还是200毫升?
当然,这是一个比喻,主要是让我们理解大模型加持后的手机系统,他有了触类旁通的主动思考能力。而OriginOS 4,首先要解决的就是诸如此类沟通能力的改善。
大模型产品进入真实可用的阶段,解决知识图谱的完整和完善,也是非常重要的底层能力。vivo目前已经建立了超过2800T的知识图谱,目前投入系统应用的约有150T。150T是什么概念呢?等于2个半中国国家图书馆藏书里的知识量。
海量知识图谱建立起来以后,对用户意味着什么呢?
过去我们问手机助手:介绍一下大熊猫?他大概率是给你一个类似百度百科的标准化答题。但引入大模型以后,他可能可以给你洋洋洒洒讲半个小时都不带重样。而且如果你再给他一个更精准的范围:如何在小学生兴趣课堂上介绍熊猫?他会在知识科普之外,给你诸如简单的绘本教学、手工教学、儿歌等等一系列的知识供给。
我们有些朋友特别害怕在会上发言,但身在职场又总会面对这样的时刻。手机接入大模型之后,我们先全程对会议内容录音记录,等差不多了就发起“整理记录”的需求。大模型根据你的会议记录,再结合自己数据库里的多种文本需求,在很短时间内就能完成一篇总结发言稿的撰写,并推送到你手机上。
大模型将来可以帮你规划差旅行程,日常工作,但我觉得这些还不足以体现大模型辛辛苦苦的海量数据学习和训练成就,大模型的终极目标应该是提升我们的多项能力。
比如我们来开个脑洞:很多人喜欢拍照,但又苦于拍不出好看的照片。当大模型在得到海量的摄影美学和摄影技巧训练后,他就会变成你随时随地伴随身边的摄影老师了。对你拍摄的照片进行分析,为你提供改进参考。大模型也可以根据你的拍摄习惯,理解你的个性化表达,将你的照片进行统一风格的调色和修图等。
大模型如果与手游结合,可以分析你的技术弱点和优势,帮你挑选更适合的英雄,为你规划更高效的学习成长路径等等,一句话,大模型可以是你的高水平电竞教练。
手机有一个非常强大的天然优势,就是用户已经对手机有长时间贴身的高依赖性,掌握了硬件的入口,是系统抵达用户的第一站。而且手机与用户的对话是多面的,不是某一个仅限于写作或是拍摄App等。而且手机厂商在端云协同优化、资源配置合理和分配等方面,都具有近水楼台先得月的便利条件。
App的优势在于能快速汇集海量的用户群,但其短板就是如果不与终端厂商合作,他们的产品服务都要基于云端来完成。而这一笔巨大的运行成本,在用户规模达到一定量级后,就会反过来遏制其继续扩大规模。
vivo的大模型还有哪些值得关注的点?
据目前所能了解到的信息,vivo搭载到OriginOS 4的大模型主要是配置在端侧为主。如果将算力分布在云侧为主,那肯定是极为强悍,但随之带来的终端测功耗巨高、数据时延明显、流量成本惊人等等,都很难适应大规模商业化。
那如果主要配置在端侧,会不会就失去了大模型的优势凸显呢?至少在目前我认为是不会的。因为大模型怎么用,用到哪些地方,在现阶段还是一个摸着石头过河的阶段,并不会有特别深入的功能需求。手机用户的需求多种多样,所以vivo不是仅限于一两个模型,而是一口气搭建了五个大模型,以覆盖目前手机用户的高频功能需求点。
主要配置放在端侧,还有一个特别重要的刚需——隐私安全。比如国内某著名的输入法,其语音识别准确性高得吓人,就是依靠将用户数据上传到云端的大模型内进行识别。可问题来了,如果信号不好的时候,这个语音输入功能就会罢工。而且有些用户总觉得上传到云端是不能确保数据隐私的,也比较抗拒。
但OriginOS 4将大模型配置到端侧后,语音输入的识别和转换等工作,全部都是在端侧完成,这样一来,不仅时延低,而且数据隐私保护更放心,同时还不用担心网络信号盲区的断网影响。
智能手机大模型化的想象空间有多大?
大模型加持到手机端后的应用场景究竟会是如何?即使我们现在只是看到了朦胧的轮廓,但我们却都坚信这就是未来。原因很简单,大模型所带来的功能是具备“推”和“拉”两个能力的。
推是指大模型能协助完成很多繁杂的重复劳动和低技术含量的工作,将一些必须做但又没啥工作技能需求的工作替代以后,可以大规模释放生产力,去从事更具有创造性价值的工作。这就像人类从人工搬运到有了推车,后来有了蒸汽机和内燃机,直到今天通过电动化来提升搬运效率一样。未来很多只需要输入简单指令就能训练大模型完成的工作,就会从人工测转移出去。
而拉动力——将会是让智能手机焕发新生的重要力量。我们前面提到过大数据通过智能手机与用户建立连接后,不仅是能协助处理日常性工作,更重要的是能充当我们在工作、娱乐、运动等场景中的“第三只眼”。“第三只眼”是什么呢,是洞察我们的优缺点,掌握分析我们的规律性,最后结合大模型数据库来提供具有指导性的建议。
所以大模型的尽头不是让我们与语音小助手的对话更像真人对话这么浅显,更为重要的是能让我们与朝夕相伴的手机一起,可以去发现更好的自我,创造更好的自我。科技创新的目标一定不是让人类懒惰,而是让人类可以集中有限的专注力,去发现更多更值得专注的方向。
OriginOS 4,到底这次能满足我们多少好奇心?相信很快就能揭开谜底。 |