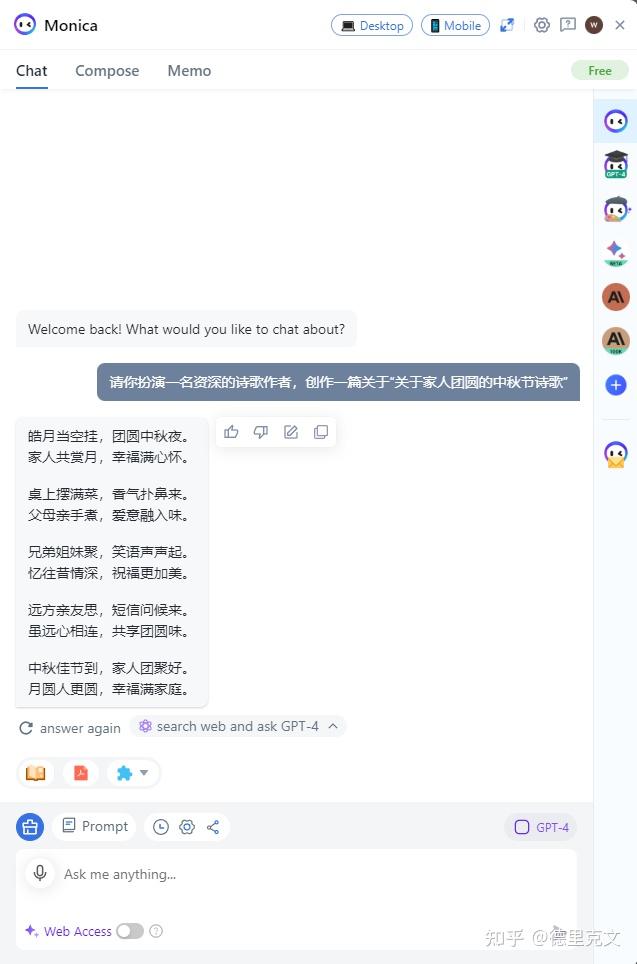
各有优劣。不过不知道题主使用AI工具的目的。这里分别以阅读、写代码、各种创作等角度展开做个分享。 AI工具也不只有ChatGPT,很多 AI 工具可以给工作、生活带来一定提升。
搜索
ChatGPT 刚出世时,很多人说要颠覆 Google。因为原来要找一个知识,需要在 Google 或者百度进行关键词搜索。但搜索完之后,结果将是上万张网页,需要我们一页一页点击链接,查看信息。这其中,10 条链接或许只有 1 条和问题相关。当我们没找到相关信息时,还需要重新输入关键词再搜索。
而在 ChatGPT 中,对于提问可以直接解答。不过 ChatGPT 有两个缺陷,一是信息只到 2021 年,二是没有联网缺乏及时性的新信息。
New Bing 集成了 ChatGPT 的模型。当我们输入问题后,不仅会触发搜索,还会自动浏览网页文档,并总结相关信息,以结果直接反馈。以代码问题为例,正常搜索跳到 CSDN 等相关类型的开发网站,而 New Bing 将直接列出可运行的代码。这是非常方便且提效的。

延伸到企业内部的搜索,也是同理。企业内部信息管理系统,大部分搜索与 Google 类似,输入关键词,弹出文档链接,里面有标题和正文内容的匹配。这也需要一篇一篇自行寻找。此时通过 GPT 能力的结论直接反馈,将节省大量时间。
除了 New Bing,还有两个项目 perplexity.ai 和 you.com 可以直接访问,也提供了类似ChatGPT形式的问答。搜一个问题,会直接把答案回复出来,而且把相关引用链接都放在里面。这是很好的提效产品。
阅读
阅读方面介绍两个优秀产品 Bearly.ai 和 TLDR this。Bearly.ai 是一个浏览器的插件。当用户打开一篇长文章后,它会自动总结文章内容,提炼出关键结构,有效提升阅读效率。此外,该插件还有一个重要功能,可以在亚马逊等购物网站上,遍历商品的用户评论,并进行好评、差评的总结。
企业内部也常有类似需求,包括邮件、微信的沟通,甚至外部评论,通过收集信息并基于GPT模型的能力,进而快速知晓产品服务的好坏点。
搜索+阅读
除了搜索之外,Google 有 Talk to Books 的产品。当提出问题之后,将从历史上已出版的书籍中摘录问题相关的原文,并展示来源书籍。
这些是问答式的搜索,并不是严格的关键词匹配。如果仅是关键词匹配,效率是不高的。以搜素“不良率”关键词为例,我们会得到很多不相关的信息,因为它不知道我们想要“什么样的不良率”。但如果通过自然语言,详细地提出问题,那模型可以自动理解语义,并找到相关文档进行全面展示。这是很大的基础进步,提升产品体验。

写代码
代码方面目前也有很多成熟应用,通过注释自动生成代码,或者选中代码对齐进行语义注释,甚至测试、检查性能等等。这里面有大名鼎鼎的 ChatGPT、Copilot ,类似的还有 Tabnine,CodeGeeX 等,也有一些专门领域的生成工具,例如 Warp 中自带的 AI 能力可以生成终端命令,PingCAP 之前做的 Chat2Query,可以帮助自动生成 SQL,以及像 Seek.ai,Manson 等更面向业务用户的数据分析工具。
除了代码生成外,还有专门面向自动化测试生成的 Codium,自动文档生成的 Mintlify,以及各种功能都集成到一起了的 Bito。
创作
创作领域,以“写一份软件质量提升计划”为例。我们通过 notion.ai 生成 10-20 个不错的计划建议,还能进一步通过交互式的指令,展开二级列表,并进行排期执行。

在工作中需要做各种各样的计划时,这些工具可以把常识性的计划罗列出来。我们只需在此基础上,结合公司的实际情况,进行个性化修改即可。
prompt engineering
自 ChatGPT 推出以来,很多人的工作是在 ChatGPT 里完成的。这里出现了一个问题,我们该怎么样更好地去向 ChatGPT 提问题。因为ChatGPT的回答能力很强,但这需要我们把问题描述地足够清楚,它才能够给到高质量的回答。
这里分享一系列的工具,提示我们有一个场景问题时,该怎么提问。这些工具网站提供了提示词模板,帮助我们更好的提问。此外,还有其他用户反馈的优质提问经验的分享。
- https://github.com/f/awesome-chatgpt-prompts
- https://sharegpt.com/explore
- https://untools.co/thinking-tools-guide
- https://prompthero.com/
常见问题
ChatGPT 产品本身有一些常见问题:
- ChatGPT 回答可能会胡编乱造;
- 只知道 21 年前公开网络的信息;
- 数据隐私安全问题。
针对胡编乱造的现象,目前有一些方式可以优化。例如提问“某公司的业绩表现如何”,该公司根本没有对外披露过该数据,那它可能会给到假数据,这实际上是错误的。
此时,我们需要一些提示词,并构建回答的语境,这很大程度上能避免胡编乱造的情况。此外,针对信息时效性的问题,可以使用 New Bing。New Bing 结合了 ChatGPT 的总结能力,并且基于它本身的搜索能力,可以获取最新讯息,更大程度上降低了胡编乱造的概率。
针对公开信息的局限性。在企业内部,可以进行信息输入,进一步训练,提升模型的信息广度。例如,2021 年之前的外部信息,没有“观远数据的吉祥物是观小猿”这一信息。当信息提交模型后,它可以进一步加以训练。
这里发散开来,将有很多的实际应用。很多公司都有帮助文档,以观远数据 BI 产品帮助文档为例。虽然所有人都可以看到帮助文档,但 ChatGPT 很大概率没有将其纳入训练过程。那么利用信息再输入的方式,可以把这些观远数据公开的BI产品信息提交给模型,再向其提问。如此一来,它就成为了企业定制化的智能问答机器人。
针对数据安全问题。以业务问题为例,例如想获取上季度的营业额,我们通过给 ChatGPT 提交 schema 信息,而不是完整的数据表信息,让 ChatGPT 返回 SQL。我们再在内部通过这条 SQL 搜索获取数据,就能有效避免数据泄露。另外,如果是非常敏感的数据,相信未来可以进行私有化的部署,完全不对公网,数据安全也可以得到一定的保障。
AI Thinking
谈了这么多 AI 产品的使用,可以发现在 AI 时代,过去很多要花大量时间做的重复劳动、甚至脑力劳动、知识劳动,现在都可以用 ChatGPT 来替代。那么我们人类在新时代中要发挥什么样的价值?要去做什么样的事情?
首先要了解 AI 基础的运作模式,大致明白它的工作原理;其次是 AI 和人类智能的区别,AI 擅长做哪些事情,不擅长做哪些事情;最后怎么样把日常工作中的事情可以交给AI来做,哪些事情我们自己做。
如果可以利用好 AI,相信我们的工作效率能得到数倍的提升。这里着重分享下人和AI区别的个人理解。
- 首先是批判性的思维和创造力。这是AI非常匮乏的,因为AI只有收到我们的指令后,它才能做事。
- 其次是同理心,AI 很难理解用户所在处境,但人和人之间比较好理解。
- 最后,在有了同理心后,人类可以进行产品构思、具体原型打造,以及后续产品发布的测试与迭代。这些事情都是模型不太擅长的。
但在上述过程中,chatGPT 可以起到很好的辅助作用。例如在产品构思时,可以帮助我们进行头脑风暴并列出关键意见。
Chat2SQL
最后分享一个观远数据发布的“BI Copilot 产品化应用系列”首发产品 Chat2SQL。
Chat2SQL 是一款浏览器插件,可以在 ETL 开发中实现自然语言生成 SQL、解释 SQL 等功能。围绕“快速上手、广泛推广、活跃用起来”而建设的 Chat2SQL,能以极低的使用门槛帮助更多业务人员快速自主进行 BI 分析,有效减少 IT 繁琐的取数、做表工作。
生成 SQL:自动化,交互式
Chat2SQL能通过自然语言交互协助生成 SQL 查询语句。以实际工作流程为例:
1. 接收用户的自然语言查询请求,例如“每个品牌的退款额是多少”;
2. 将用户的查询请求转化为机器可理解的 SQL,例如“SELECT `商品名称`, SUM(`退款金额`) AS `退款额` FROM input1 GROUP BY `商品名称`”,将生成的 SQL 查询语句返回给用户;
3. 进一步交互式的追问,例如“再加上渠道维度”;
4. 再次转换为 SQL,例如“SELECT `商品名称`, `渠道`, SUM(`退款金额`) AS `退款额` FROM input1 GROUP BY `商品名称`, `渠道`”,并返回给用户。
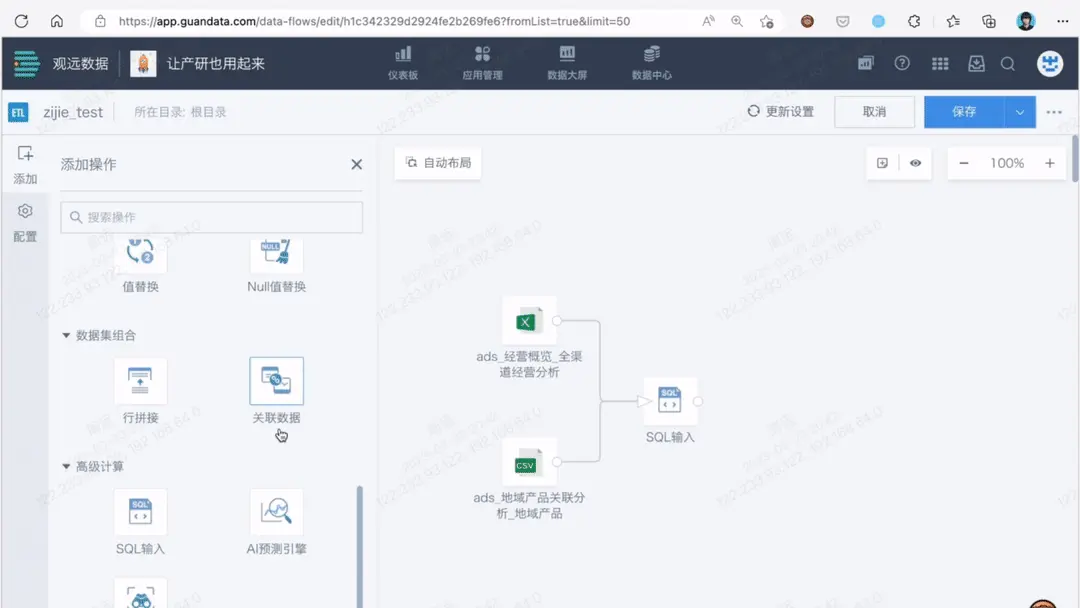
Chat2SQL 集合了 ChatGPT 能力,可以识别自然语言查询请求中的实体、关系和条件,并将其转化为 SQL 返回给用户,有效提高了数据查询的效率和准确性。
解释 SQL:更易懂,高效能
除去生成 SQL 语句,反过来,Chat2SQL也提供了解释 SQL 语句的能力。同样以实际工作流程为例:
1. 接收用户提供的SQL查询语句;
2. 使用ChatGPT训练的自然语言生成模型将SQL查询语句转化为易懂的自然语言句子;
3. 进行交互式提问,例如“这段 SQL 是否可做进一步性能优化”。
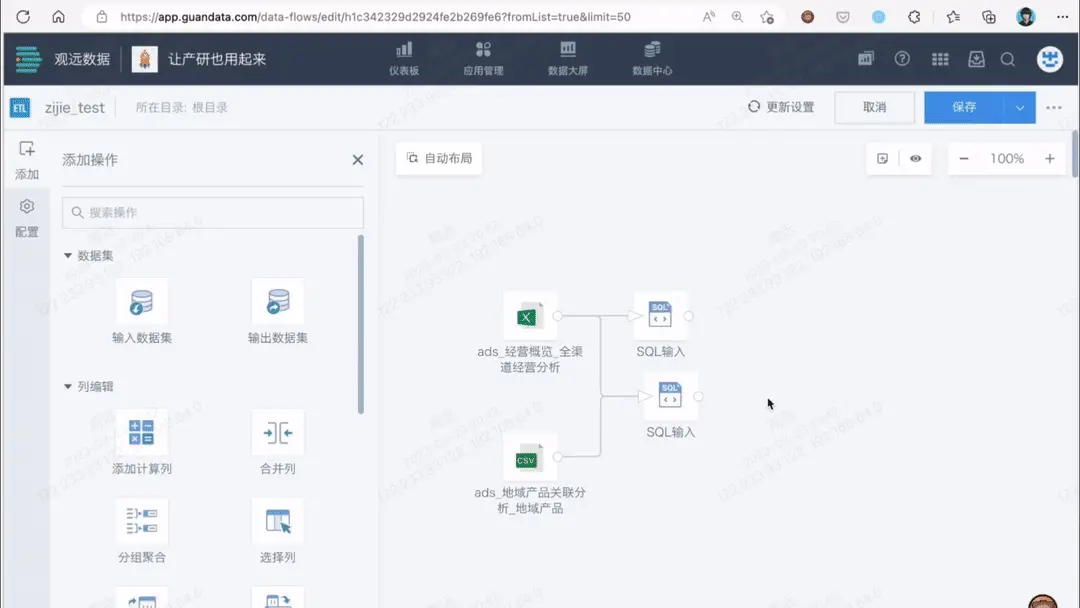
通过解释 SQL 查询语句,将 SQL 转化为易懂的自然语言,乃至后续交互式的互动提问,Chat2SQL 有效提高用户对数据查询语句的理解和使用效率。
欢迎大家试用Chat2SQL~
Chat2SQL试用申请 |