ChatGPT和GPT-4消灭了大部分nlp工作,刚刚Meta放出了大招-SAM模型,知乎网友评价“这下cv真的不存在了,<快跑>”,这篇论文只做了一件事情:(零样本)分割一切。类似 GPT-4 已经做到的「回答一切」。
看看Twitter上的评论
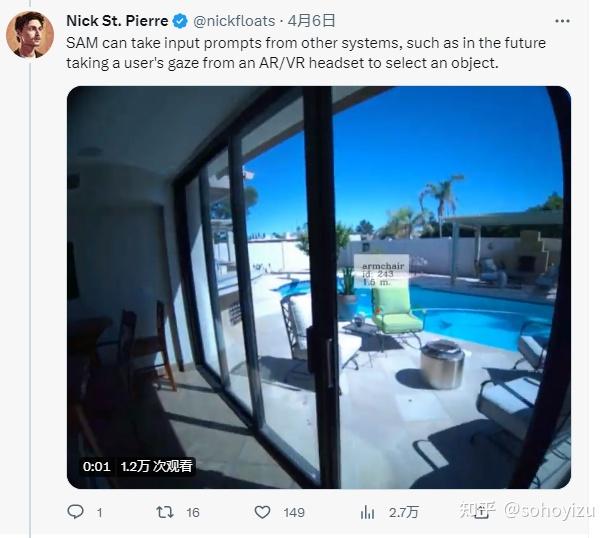
这个模型是Meta元宇宙的研究成果,将会给图像分割领域带来巨大的变革,同时对于自动驾驶以及AR现实领域也有想象空间。meta自己的博客里面展望未来,在SAM 可用于通过 AR 眼镜识别日常物品,该眼镜可以向用户提示提醒和说明;SAM也许有一天会帮助农业部门的农民或协助生物学家进行研究。
Meta在博客中介绍说,「SAM 已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』上即开即用,无需额外的训练。」在深度学习领域,这种能力通常被称为零样本迁移,这也是 GPT-4 震惊世人的一大原因。
论文地址:https://arxiv.org/abs/2304.02643
项目地址:https://github.com/facebookresearch/segment-anything
Demo 地址:Segment Anything
方法介绍
此前解决分割问题大致有两种方法。第一种是交互式分割,该方法允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。第二种,自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子)。这两种方法都没有提供通用的、全自动的分割方法。
SAM 很好的概括了这两种方法。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面允许用户以灵活的方式使用它,只需为模型设计正确的提示(点击、boxes、文本等),就可以完成范围广泛的分割任务。
总而言之,这些功能使 SAM 能够泛化到新任务和新领域。这种灵活性在图像分割领域尚属首创。
模型结构
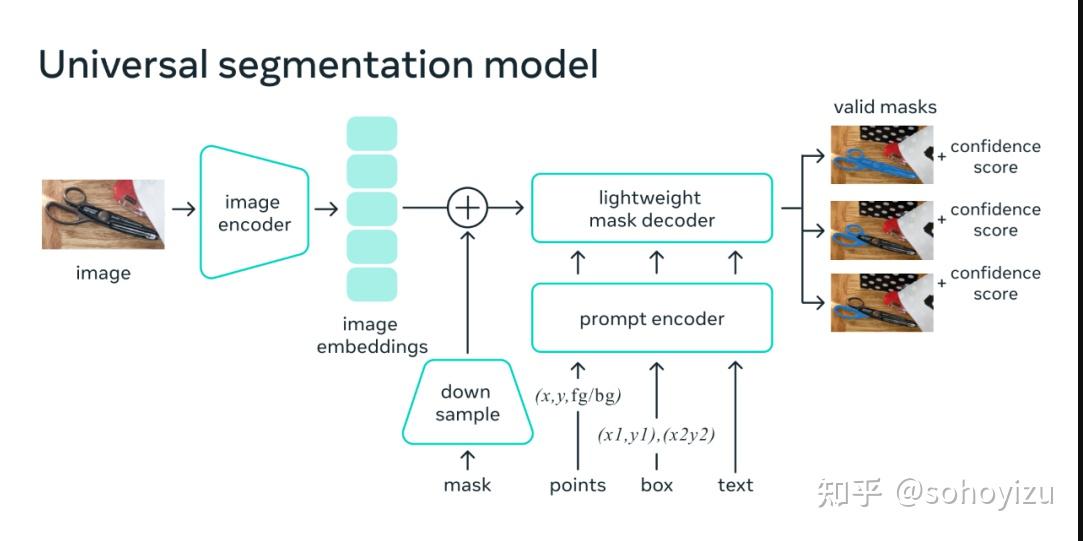
图1 SAM模型架构
图像编码器:采用MAE预训练的ViT模型,将图片提取为embedding
提示词编码器:考虑两种不同的提示编码器,稀疏编码和稠密编码,其中point和box和采用[1]中的Coordinate-based MLP来编码,每个prompt类型一个编码,然后加上CLIP提取text编码。
mask解码器:mask解码器有效地将图像嵌入、提示嵌入和输出标记映射到一个mask。 该设计受 [2,3]的启发,采用了 Transformer 解码器块的修改,后跟动态掩码预测头。Meta修改后的解码器块在两个方向(提示-图像嵌入和反之亦然)使用提示自注意力和交叉注意力来更新所有嵌入。 运行两个块后,我们对图像嵌入进行上采样,MLP 将输出标记映射到动态线性分类器,然后计算每个图像位置的蒙版前景概率。
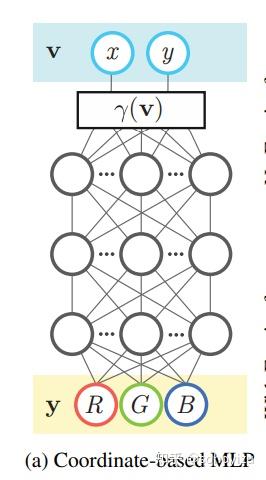
图2 Coordinate-based MLP
解决歧义:对于一个输出,如果给出的提示不明确,模型将平均多个有效掩码。 为了解决这个问题,我们修改模型以预测单个提示的多个输出掩码(见图 1)。 我们发现 3 个掩码输出足以解决大多数常见情况(嵌套掩码通常最多三个深度:整体、部分和子部分)。 在训练期间,我们仅通过掩码反向传播最小损失, 为了对掩模进行排名,该模型预测每个掩模的置信度分数(即估计的 IoU)。
训练细节:使用[2]中使用的focal loss 和dice loss的线性组合来监督学习mask预测。 作者通过在每个mask 11 轮中随机抽样几何提示和text提示来模拟交互式设置,从而允许 SAM 无缝集成到数据引擎中。
SA-1B数据集:1100 万张图片,1B+ 掩码
为了训练他们的模型,需要大量多样的数据源,这在工作开始时并不存在。 meta今天发布的分割数据集是迄今为止(迄今为止)最大的。 使用 SAM 收集数据,特别是,标注者使用 SAM 交互式地标注图像,然后使用新标注的数据依次更新 SAM。 多次重复此循环以迭代改进模型和数据集。
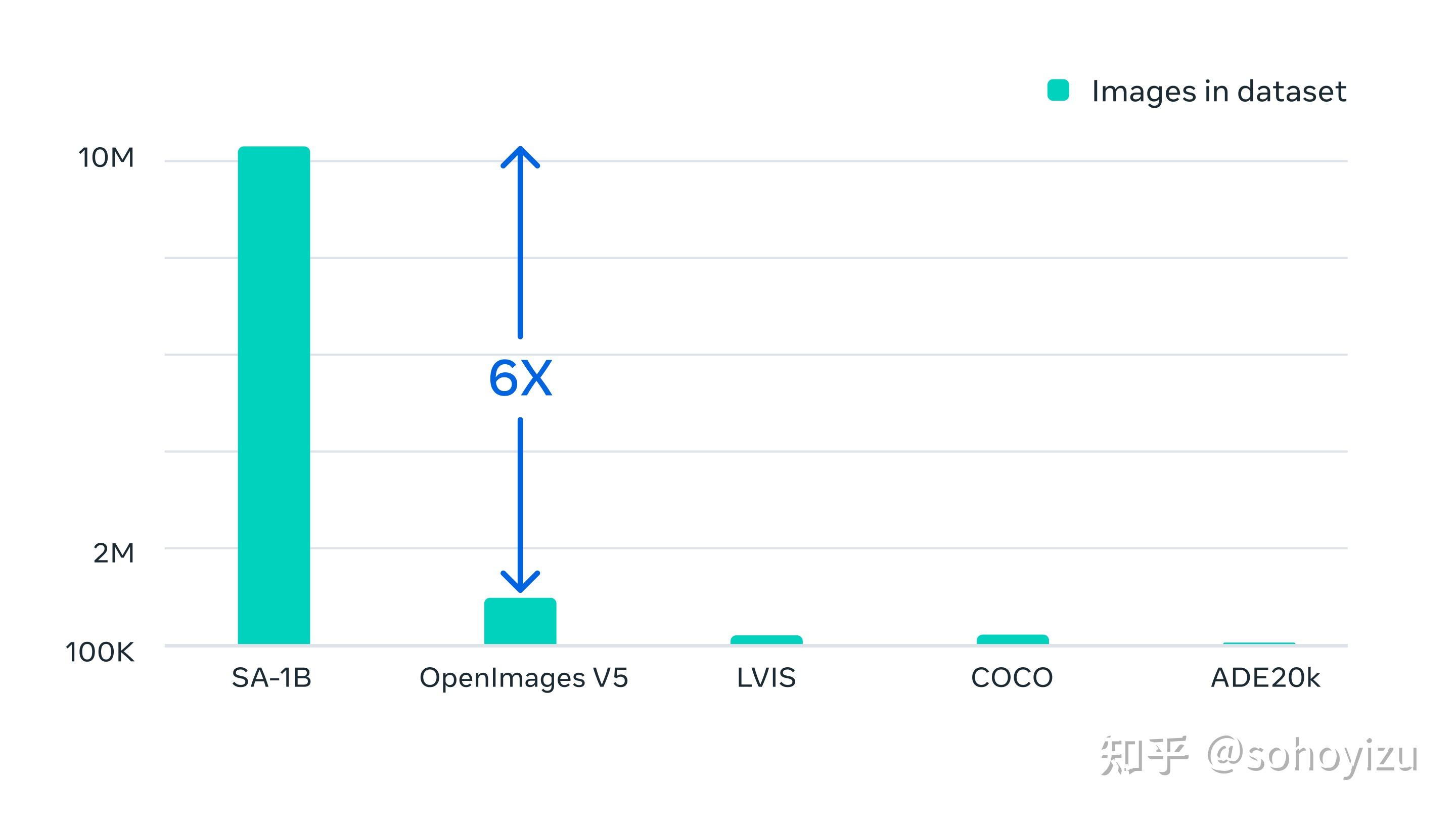
图3 数据集中图片的大小
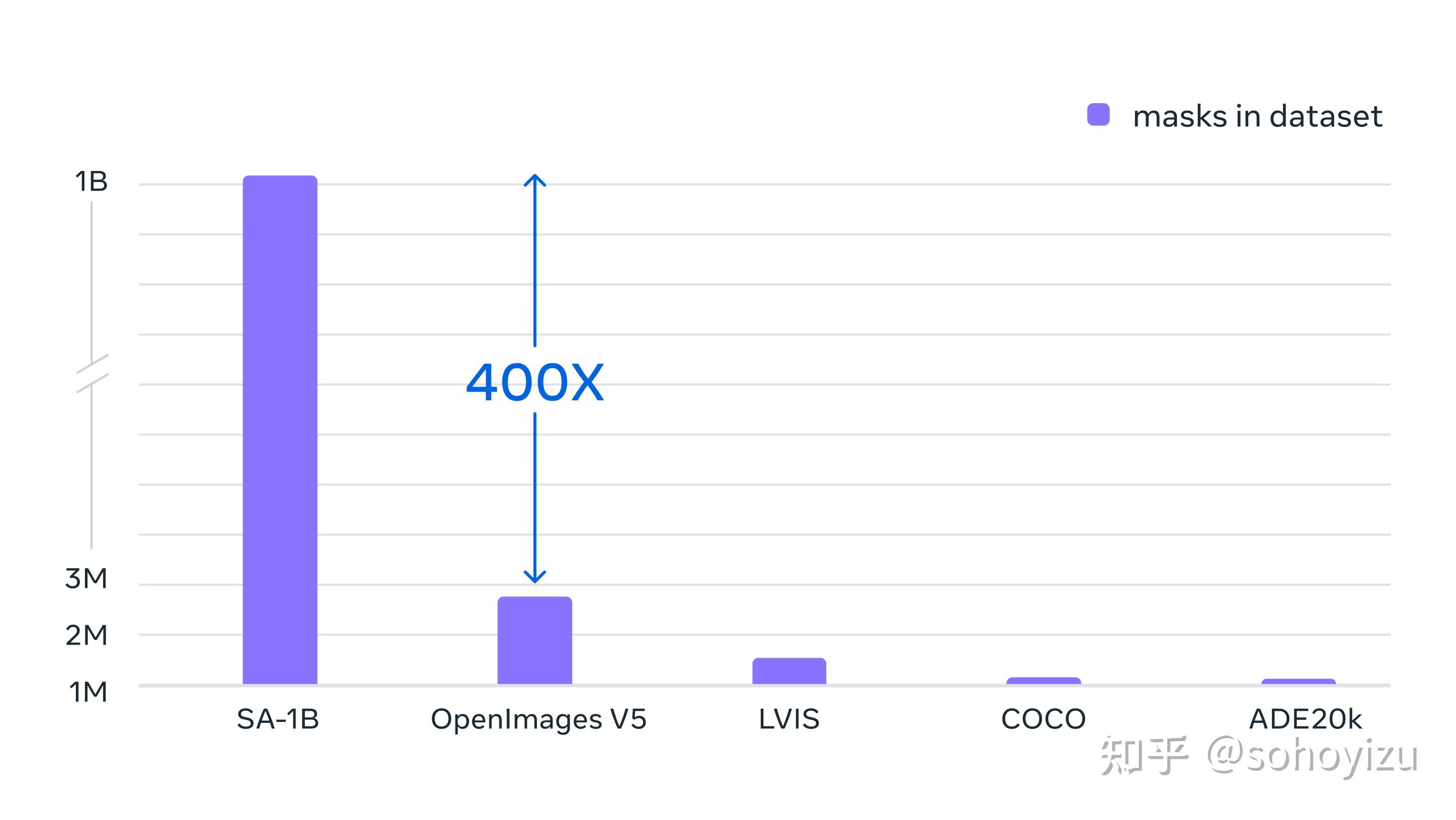
图4 图片中mask的大小
跟gpt一样,SAM模型惊艳的效果也是大力出奇迹的效果,海量的数据是模型效果的保证。
参考文献:
[1]Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. NeurIPS, 2020. 5, 16
[2]Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with Transformers. ECCV, 2020. 5, 16, 17
[3]Bowen Cheng, Alex Schwing, and Alexander Kirillov. Perpixel classification is not all you need for semantic segmentation. NeurIPS, 2021. 5, 16, 17 |





