
首先确定一个研究方向
NLP是很大的课题,敲定一个自己感兴趣或是擅长的方向。可以先了解目前各个方向的状况与前景,可以参考学术范。
学术范官方根据发文数量、被引次数等多个维度的数据统计,细分出以下自然语言处理的研究方向。其中最火的还是文本挖掘方向。
- Text mining
- Sentence
- Machine translation
- Natural language
- Parsing
- word error rate
- Syntax
- Phrase
- Noun
- Lexicono
- Sentiment analysis
- lnformation extraction·
- Language mode
- lNIST
- Automatic summarization
- Rule-based machine translation
- Realization (linguistics)
- Question answering
- Semantic similarity
- Computational linguistics
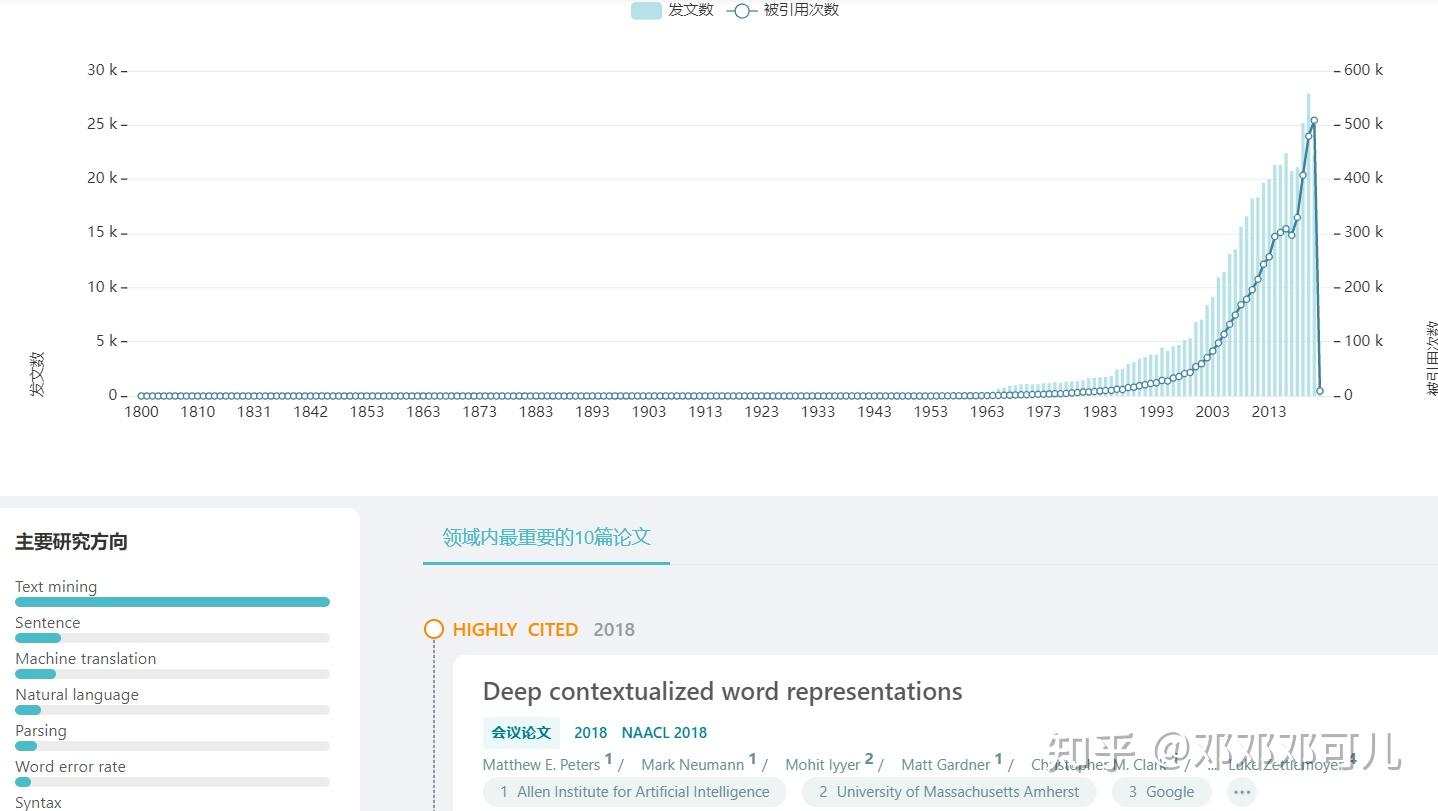
详情可以点击链接了解哦~
等对这些有了基本的了解后,再有针对地开始阅读十篇近年来最重要的论文。
推荐下NLP这个领域内最重要的10篇论文吧(依据学术范标准评价体系得出的10篇名单):
(下列文献访问网页后可以使用翻译功能)
一、Deep contextualized word representations
作者:Matthew E. Peters / Mark Neumann / Mohit Iyyer / Matt Gardner / Christopher M. Clark / ... / Luke Zettlemoyer
摘要:We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
全文链接:文献全文 - 学术范 (xueshufan.com)
二、Enriching Word Vectors with Subword Information
作者:Piotr Bojanowski / Edouard Grave / Armand Joulin / Tomas Mikolov
摘要:Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models to learn such representations ignore the morphology of words, by assigning a distinct vector to each word. This is a limitation, especially for languages with large vocabularies and many rare words. In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character n-grams. A vector representation is associated to each character n-gram, words being represented as the sum of these representations. Our method is fast, allowing to train models on large corpora quickly and allows to compute word representations for words that did not appear in the training data. We evaluate our word representations on nine different languages, both on word similarity and analogy tasks. By comparing to recently proposed morphological word representations, we show that our vectors achieve state-of-the-art performance on these tasks.
全文链接:文献全文 - 学术范 (xueshufan.com)
三、Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
作者:Yonghui Wu / Mike Schuster / Zhifeng Chen / Quoc V. Le / Mohammad Norouzi / ... Jeffrey Dean
摘要:Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.
全文链接:文献全文 - 学术范 (xueshufan.com)
四、GloVe: Global Vectors for Word Representation
作者:Jeffrey Pennington / Richard Socher / Christopher D. Manning
摘要:Recent methods for learning vector spacerepresentations of words have succeededin capturing fine-grained semantic andsyntactic regularities using vector arith-metic, but the origin of these regularitieshas remained opaque. We analyze andmake explicit the model properties neededfor such regularities to emerge in wordvectors. The result is a new global log-bilinear regression model that combinesthe advantages of the two major modelfamilies in the literature: global matrixfactorization and local context windowmethods. Our model efficiently leveragesstatistical information by training only onthe nonzero elements in a word-word co-occurrence matrix, rather than on the en-tire sparse matrix or on individual contextwindows in a large corpus. The model pro-duces a vector space with meaningful sub-structure, as evidenced by its performanceof 75% on a recent word analogy task. Italso outperforms related models on simi-larity tasks and named entity recognition.
全文链接:文献全文 - 学术范 (xueshufan.com)
五、Sequence to Sequence Learningwith Neural Networks
作者:Ilya Sutskever / Oriol Vinyals / Quoc V. Le
摘要:Deep Neural Networks (DNNs) are powerful models that have achieved excel-lent performance on difficult learning tasks. Although DNNswork well wheneverlarge labeled training sets are available, they cannot be used to map sequences tosequences. In this paper, we present a general end-to-end approach to sequencelearning that makes minimal assumptions on the sequence structure. Our methoduses a multilayered Long Short-Term Memory (LSTM) to map theinput sequenceto a vector of a fixed dimensionality, and then another deep LSTM to decode thetarget sequence from the vector. Our main result is that on anEnglish to Frenchtranslation task from the WMT’14 dataset, the translationsproduced by the LSTMachieve a BLEU score of 34.8 on the entire test set, where the LSTM’s BLEUscore was penalized on out-of-vocabulary words. Additionally, the LSTM did nothave difficulty on long sentences. For comparison, a phrase-based SMT systemachieves a BLEU score of 33.3 on the same dataset. When we usedthe LSTMto rerank the 1000 hypotheses produced by the aforementioned SMT system, itsBLEU score increases to 36.5, which is close to the previous best result on thistask. The LSTM also learned sensible phrase and sentence representations thatare sensitive to word order and are relatively invariant to the active and the pas-sive voice. Finally, we found that reversing the order of thewords in all sourcesentences (but not target sentences) improved the LSTM’s performance markedly,because doing so introduced many short term dependencies between the sourceand the target sentence which made the optimization problemeasier.
全文链接:文献全文 - 学术范 (xueshufan.com)
六、The Stanford CoreNLP Natural Language Processing Toolkit
作者:Christopher D. Manning / Mihai Surdeanu / John Bauer / Jenny Finkel / Steven J. Bethard / David McClosky
摘要:We describe the design and use of theStanford CoreNLP toolkit, an extensiblepipeline that provides core natural lan-guage analysis. This toolkit is quite widelyused, both in the research NLP communityand also among commercial and govern-ment users of open source NLP technol-ogy. We suggest that this follows froma simple, approachable design, straight-forward interfaces, the inclusion of ro-bust and good quality analysis compo-nents, and not requiring use of a largeamount of associated baggage.
全文链接:文献全文 - 学术范 (xueshufan.com)
七、Distributed Representations of Words and Phrases and their Compositionality
作者:Tomas Mikolov / Ilya Sutskever / Kai Chen / Greg Corrado / Jeffrey Dean
摘要:The recently introduced continuous Skip-gram model is an efficient method forlearning high-quality distributed vector representations that capture a large num-ber of precise syntactic and semantic word relationships. In this paper we presentseveral extensions that improve both the quality of the vectors and the trainingspeed. By subsampling of the frequent words we obtain significant speedup andalso learn more regular word representations. We also describe a simple alterna-tive to the hierarchical softmax called negative sampling.An inherent limitation of word representations is their indifference to word orderand their inability to represent idiomatic phrases. For example, the meanings of“Canada” and “Air” cannot be easily combined to obtain “Air Canada”. Motivatedby this example, we present a simple method for finding phrases in text, and showthat learning good vector representations for millions of phrases is possible.
全文链接:文献全文 - 学术范 (xueshufan.com)
八、Natural Language Processing (Almost) from Scratch
作者:Ronan Collobert / Jason Weston / Léon Bottou / Michael Karlen / Koray Kavukcuoglu / ... Pavel P. Kuksa
摘要:We propose a unified neural network architecture and learning algorithm that can be applied to various natural language processing tasks including part-of-speech tagging, chunking, named entity recognition, and semantic role labeling. This versatility is achieved by trying to avoid task-specific engineering and therefore disregarding a lot of prior knowledge. Instead of exploiting man-made input features carefully optimized for each task, our system learns internal representations on the basis of vast amounts of mostly unlabeled training data. This work is then used as a basis for building a freely available tagging system with good performance and minimal computational requirements.
全文链接:文献全文 - 学术范 (xueshufan.com)
九、Evaluation: from Precision, Recall and F-measure to ROC, Informedness, Markedness and Correlation
作者:David M. W. Powers
摘要:Commonly used evaluation measures including Recall, Precision, F-Measure and Rand Accuracy are biased and should not be used without clear understanding of the biases, and corresponding identification of chance or base case levels of the statistic. Using these measures a system that performs worse in the objective sense of Informedness, can appear to perform better under any of these commonly used measures. We discuss several concepts and measures that reflect the probability that prediction is informed versus chance. Informedness and introduce Markedness as a dual measure for the probability that prediction is marked versus chance. Finally we demonstrate elegant connections between the concepts of Informedness, Markedness, Correlation and Significance as well as their intuitive relationships with Recall and Precision, and outline the extension from the dichotomous case to the general multi-class case.
全文链接:文献全文 - 学术范 (xueshufan.com)
十、Glove: Global Vectors for Word Representation
作者:Piotr Bojanowski / Edouard Grave / Armand Joulin / Tomas Mikolov
摘要:Recent methods for learning vector space representations of words have succeeded in capturing fine-grained semantic and syntactic regularities using vector arithmetic, but the origin of these regularities has remained opaque. We analyze and make explicit the model properties needed for such regularities to emerge in word vectors. The result is a new global logbilinear regression model that combines the advantages of the two major model families in the literature: global matrix factorization and local context window methods. Our model efficiently leverages statistical information by training only on the nonzero elements in a word-word cooccurrence matrix, rather than on the entire sparse matrix or on individual context windows in a large corpus. The model produces a vector space with meaningful substructure, as evidenced by its performance of 75% on a recent word analogy task. It also outperforms related models on similarity tasks and named entity recognition.
全文链接:文献全文 - 学术范 (xueshufan.com)
接着还可以访问学术范上计算机自然语言处理方向的页面:
Natural language processing详情-学术范 (xueshufan.com)
学术范从数据(历年来的发文及被引数据)维度展现了NLP的发展趋势,同时提供顶刊、顶会、顶尖学者等各类榜单,帮助你快速地了解该领域的研究分布情况。
最后,推荐以下五位NLP界的大佬:
(学术范官方根据发文数量、被引次数等多个维度的数据统计得出)
1、Christopher D. Manning
所属机构:Stanford University
数据如下:
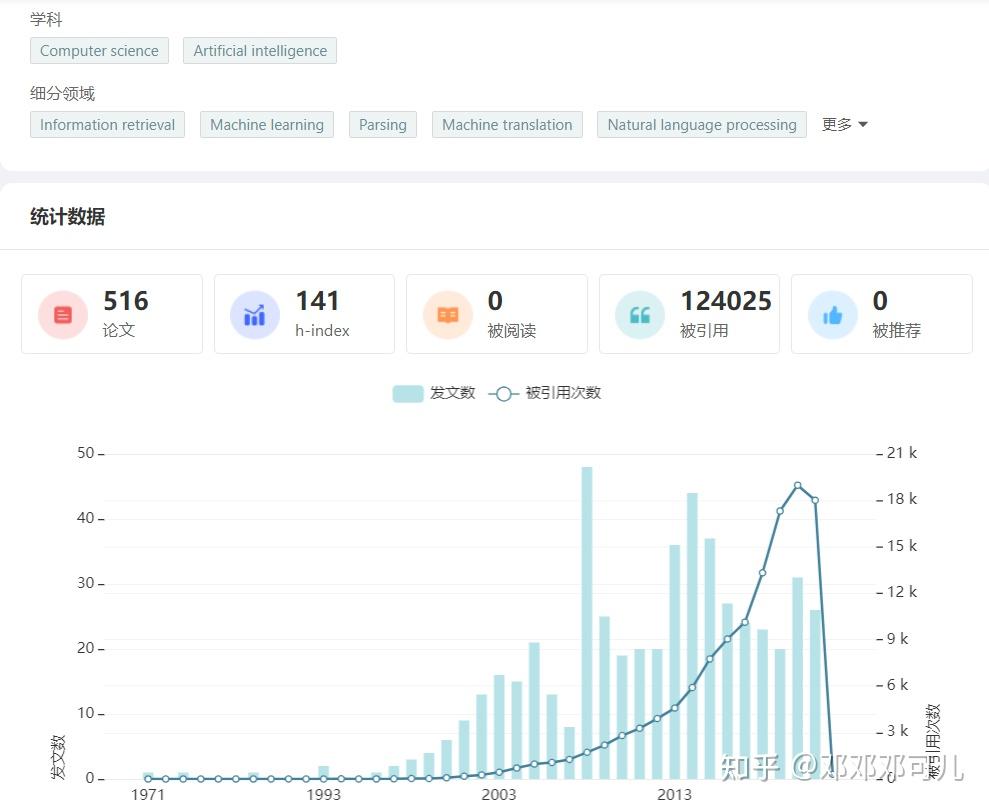
关于 Christopher D. Manning 的学术成果,请访问:学者学术成果 - 学术范 (xueshufan.com)
2、Tomas Mikolov
所属机构:Czech Technical University in Prague
数据如下:
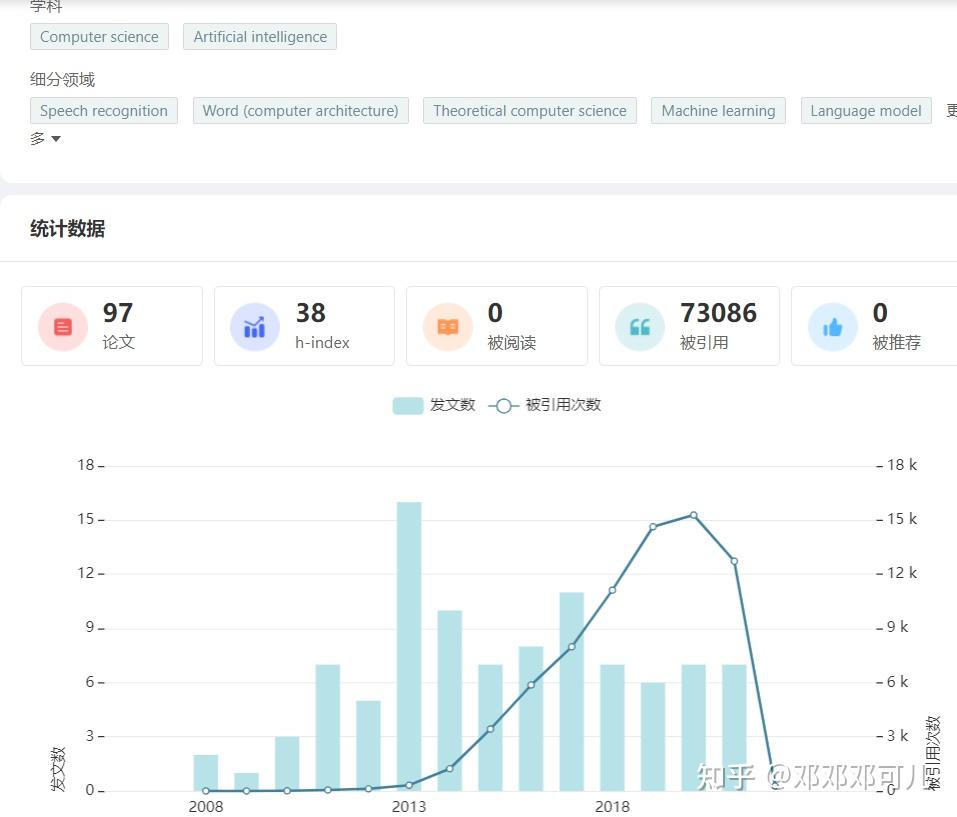
关于Tomas Mikolov 的学术成果,请访问:学者学术成果 - 学术范 (xueshufan.com)
3、Richard Socher
所属机构:http://Salesforce.com
数据如下:
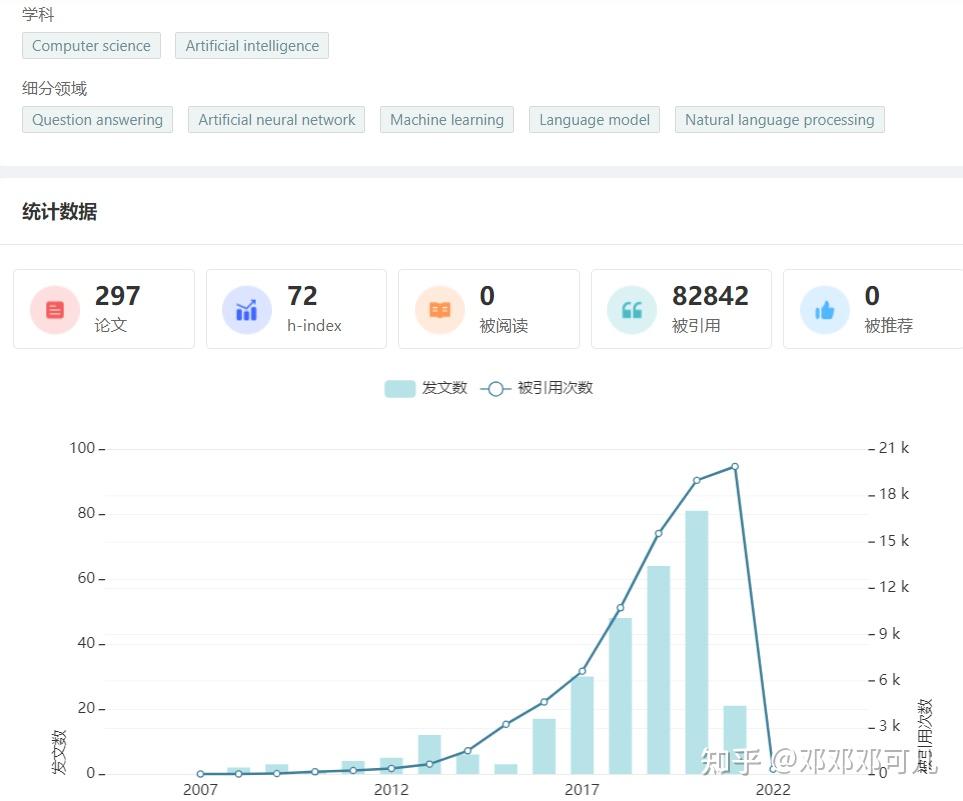
关于Richard Socher 的学术成果,请访问:学者学术成果 - 学术范 (xueshufan.com)
4、Ilya Sutskever
所属机构:OpenAI
数据如下:
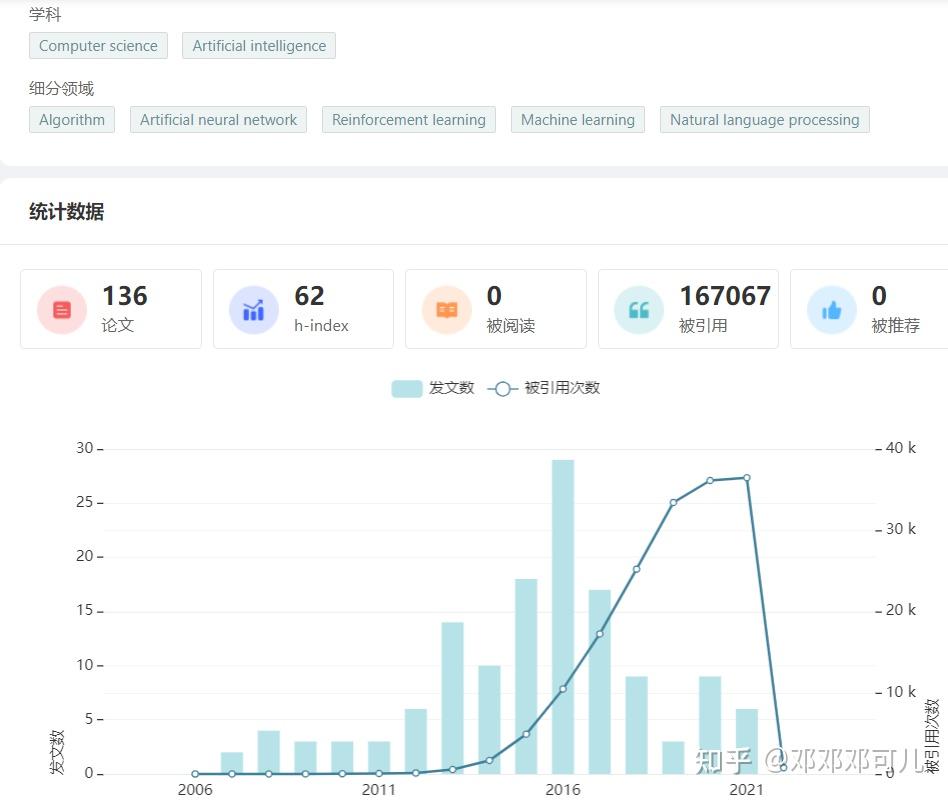
关于Ilya Sutskever 的学术成果,请访问:学者学术成果 - 学术范 (xueshufan.com)
5、Jeffrey Dean
所属机构:Google
数据如下:
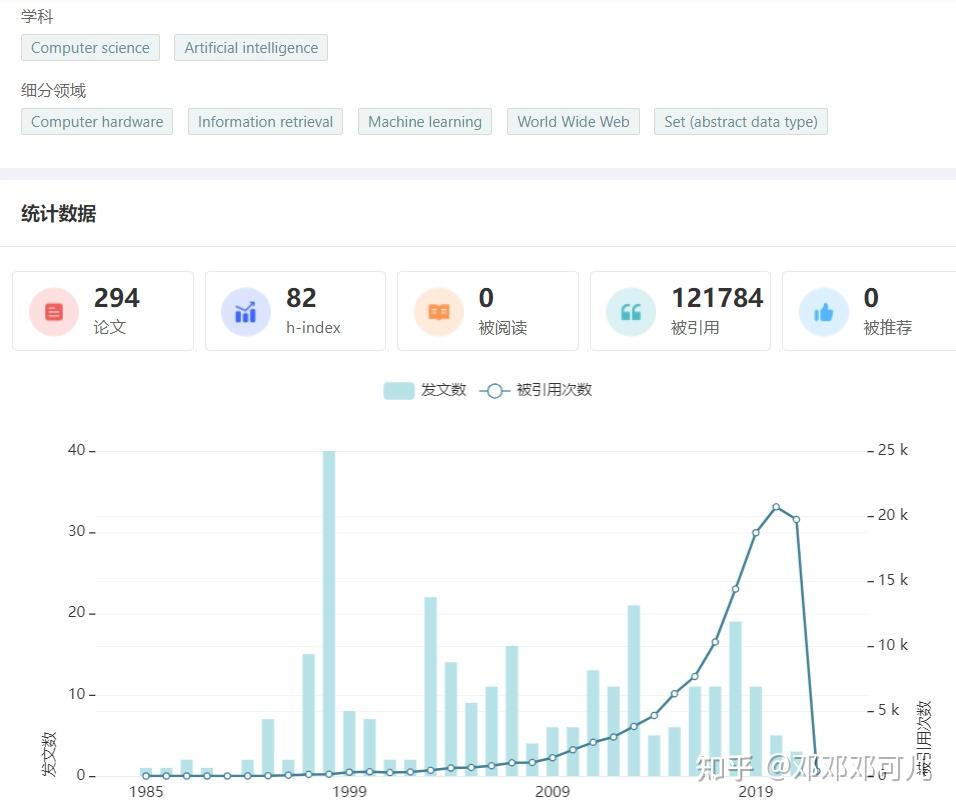
关于Jeffrey Dean 的学术成果,请访问:学者学术成果 - 学术范 (xueshufan.com)
希望可以帮到你~~
<hr/>学术范:一站式文献搜索、阅读批注的学术讨论 |



