MFA是一款基于Kaldi的音频文件和文字脚本在时间纬度上自动对齐的工具。优点是使用简单,无需学习kaldi即可使用,缺点是基于kaldi的声学模型,二次开发能力不够。针对中文拼音对齐能力不足,针对长文本处理能力不足。
Montreal-forced-aligner by MontrealCorpusTools音频和文字脚本对齐是在2018年之前ASR领域里很重要的一个步骤,当然随着CTC损失函数在机器学习领域的广泛应用,音频和文字准确对齐不再是一个必须的过程。
MFA使用了Kaldi的工具集,包括音频特征参数提取,模型构建,训练方法等。据我观测,MFA应该是使用了Kaldi比较早的nnet模型,模型比较小,训练起来非常快。MFA本身已经提供了一些预先训练好的声学模型包括english和mandarin模型,可以直接下载后使用。English的acoustic模型是基于librispeech训练的,用起来已经比较顺手了,比较准确。但是mandarin的声学模型好像数据量不够大,导致对齐效果差。所以就尝试使用自己的数据重新训练一个声学模型,结果还是不错的,见首图。以下为具体步骤(Kaldi和MFA的安装都略去了,大家可以自行按官方的方法进行安装):
首先准备好音频数据和对应的文字,如果文字是中文需要转化为拼音,我使用了pypinyin进行转化,每个中文汉字对应一个拼音,脚本如下,将中文字转为拼音:- # coding:utf8
- import os
- import sys
- import numpy as np
- from pypinyin import pinyin, lazy_pinyin, Style
- import re
- root_dir = "../train/"
- pattern = re.compile(r'(.*)\.txt$')
- for root, dir, files in os.walk(root_dir):
- for filename in files:
- #print(filename)
- output = pattern.match(filename)
- if output is not None:
- print(root, filename)
- text_file = open(root+"/"+filename)
- line = text_file.read().strip()
- line = line.replace(",", "")
- pinyin = lazy_pinyin(line, style=Style.TONE3, neutral_tone_with_five=True)
- pinyinline = ' '.join(pinyin)
- print(line)
- target_text_file = open(root+"/"+output.group(1)+".lab", "w")
- target_text_file.write(pinyinline)
- target_text_file.close()
T0055G0002S0001.wav 和 T0055G0002S0001.lab
准备好数据之后,使用MFA代的G2P模型生成词典文件:- mfa g2p mandarin_pinyin_g2p ./corpus/tiny/ dict_tiny.txt
- 其中tiny目录如下:
- $ ls tiny
- G0002 G0135 G0269 G0326 G0726 G0931 G1492 G1634 G1777 G1889 G1966
- $ ls G0002
- T0055G0002S0001.lab T0055G0002S0081.lab T0055G0002S0001.wav T0055G0002S0081.wav
- $ cat T0055G0002S0001.lab
- yi3 hou4 ni3 shi4 nan2 hai2 zi5
- dict大概这个样子:
- <eps> 0
- !sil 1
- <unk> 2
- an1quan2 3
- ba1shi2nian2dai4 4
- bao1luo1wan4xiang4 5
- mfa train --config_path /home/yons/data/mfaligner/Montreal-Forced-Aligner/montreal_forced_aligner/config/basic_train.yaml /media/yons/SSD1T4K/kaldi/kaldi_data/corpus/tiny/ dict_tiny.txt result_tiny
这个运行完成后,默认会在路径:- /home/yons/Documents/MFA/tiny/tri_ali
- $ ls tri_ali
- acoustic_model.zip ali.1 ali.2.scores aligned.2 log nbest.2 phone_ctm.2 word_ctm.0
- ali.0 ali.1.scores aligned.0 final.mdl nbest.0 phone_ctm.0 textgrids word_ctm.1
- ali.0.scores ali.2 aligned.1 final.occs nbest.1 phone_ctm.1 tree word_ctm.2
使用下面的命令进行对齐我们的音频:- mfa align --config_path /home/yons/data/mfaligner/Montreal-Forced-Aligner/montreal_forced_aligner/config/basic_align.yaml my_example2/ dict_tiny.txt /home/yons/Documents/MFA/tiny/tri_ali/acoustic_model.zip my_result3
接下来使用工具Praat进行 textgrid和 wav文件的对比分析,看看是不是准确对齐了。
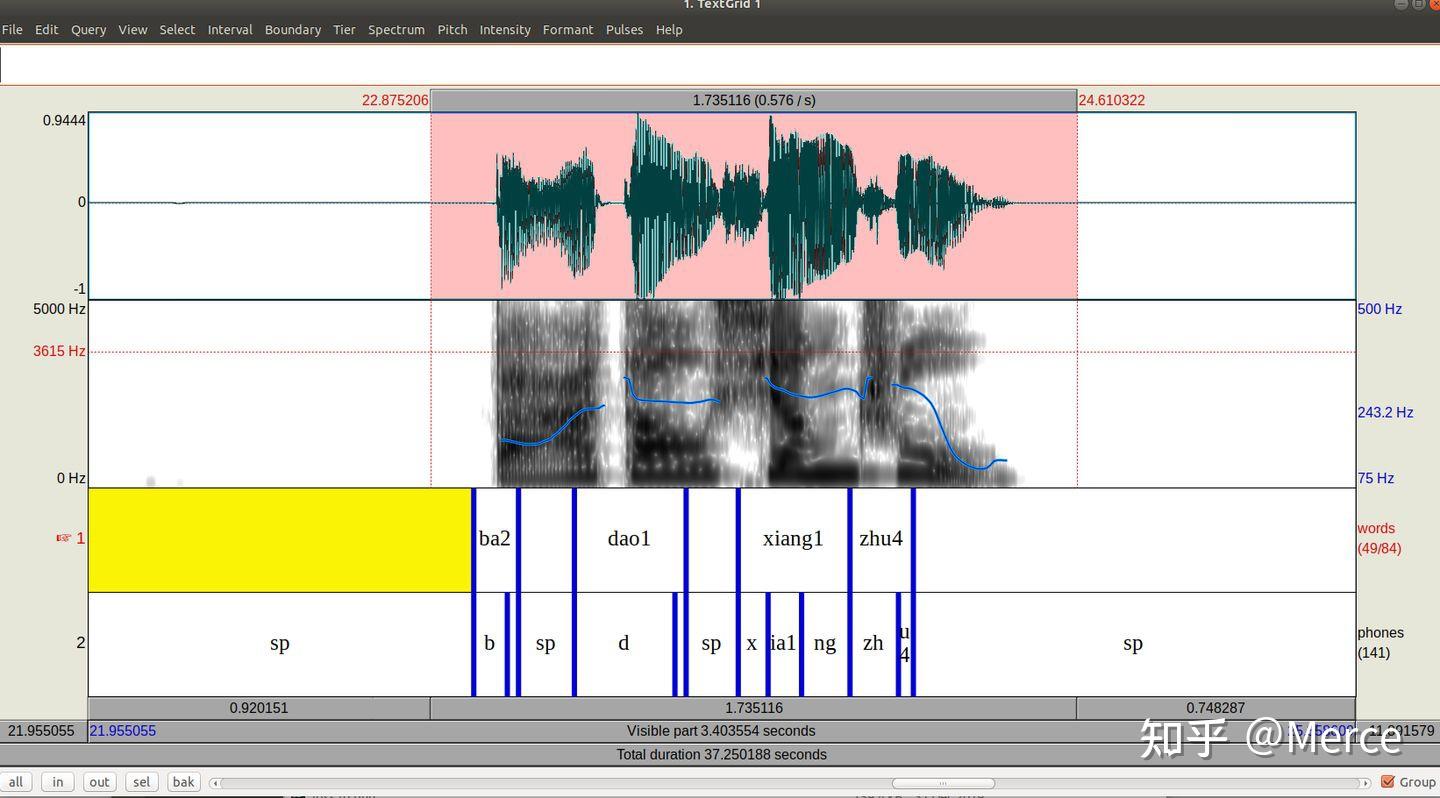
拔刀相助 对应拼音和音素 |



