开源且离线可用的,那当然是现在最火的OpenAI家的whisper啊,在安装后下载模型文件后就可以直接离线使用,即可以用whisper命令行调用,也可以使用Python调用。这个开源离线可用的东西,有国外已经部署在树莓派上,实现了离线的智能家具语音识别控制。
https://github.com/openai/whisper安装
使用以下指令:- pip install -U openai-whisper
- pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
- # on Ubuntu or Debian
- sudo apt update && sudo apt install ffmpeg
- # on Arch Linux
- sudo pacman -S ffmpeg
- # on MacOS using Homebrew (https://brew.sh/)
- brew install ffmpeg
- # on Windows using Chocolatey (https://chocolatey.org/)
- choco install ffmpeg
- # on Windows using Scoop (https://scoop.sh/)
- scoop install ffmpeg
有五种模型大小可供选择,其中除了large模型外还提供了只支持英文的版本。模型越小占用显存越少,速度也更快,但精度也更低,所以在使用时需要自己在速度和准确度之间权衡。以下是可用模型的名称、近似内存需求和相对速度。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed | | tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x | | base | 74 M | base.en | base | ~1 GB | ~16x | | small | 244 M | small.en | small | ~2 GB | ~6x | | medium | 769 M | medium.en | medium | ~5 GB | ~2x | | large | 1550 M | N/A | large | ~10 GB | 1x |
英语模型中的.en模型(仅适用于英语应用程序)往往表现更好,特别是对于tiny.en和base.en模型。
Whisper的表现在不同语言下会有很大差异。下图展示了使用large-v2模型对Fleurs数据集进行的WER(词误率)语言拆解。数值越小,表示表现越好。
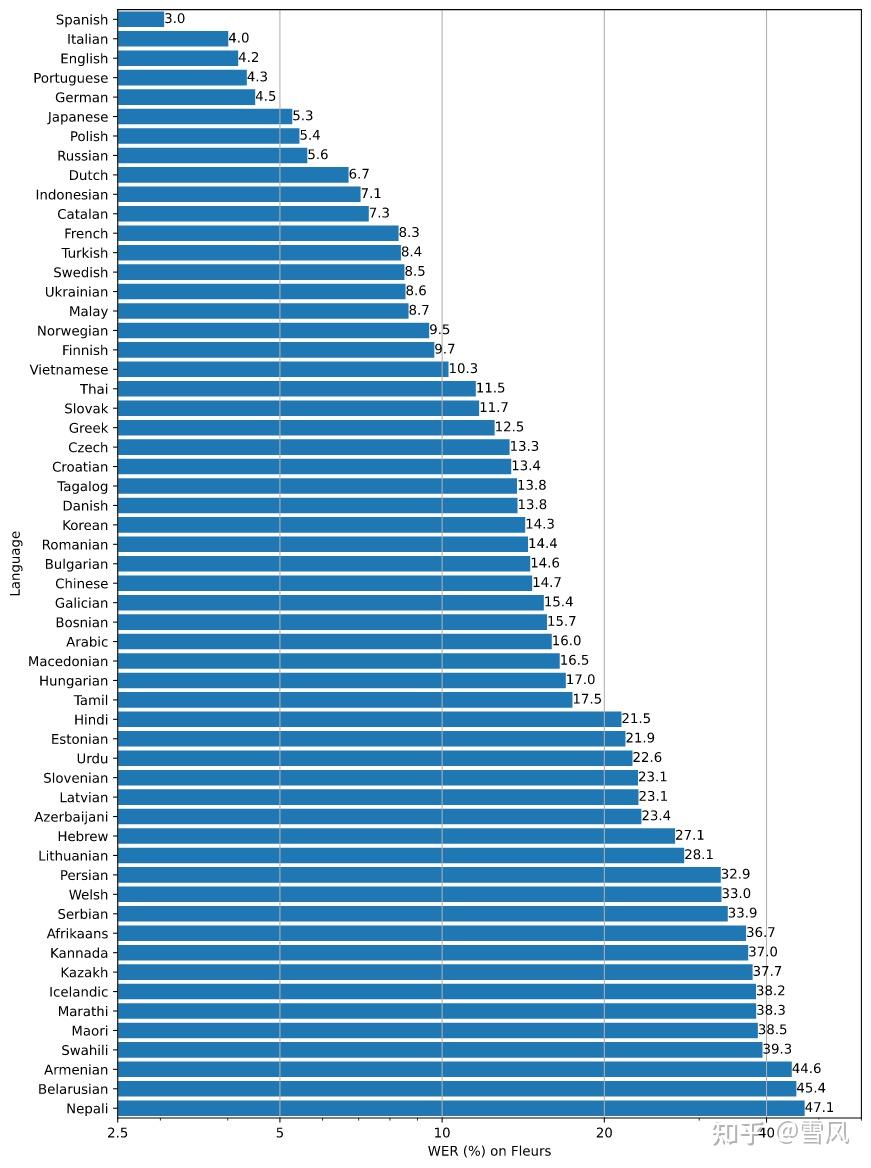
简单的说,目前whisper最擅长的6种语言是西班牙语、意大利语、英语、葡萄牙语、德语和日语。中文的WER达到14.7,处于中等水平,所以表现不是那么好,但可用,后面会测试。
用法
直接使用whisper指令识别音频和视频文件为文本,如:这里需要重点说明的是,默认会生成5个文件,文件名和你的源文件一样,但扩展名分别是:.json、.srt、.tsv、.txt、.vtt。除了普通文本,也可以直接生成电影字幕,还可以调json格式做开发处理。
前面介绍了whisper有多种模型,默认使用的是small模型,占用显存少,识别速度快,但准确率没大模型高,以下--model medium命令将使用medium模型转录音频文件中的语音:- whisper audio.flac audio.mp3 audio.wav --model medium
- whisper japanese.wav --language Japanese
- whisper chinese.mp4 --language Chinese --task translate
除了使用whisper指令,也可以使用python开发使用,这很方便,但这里不多做介绍,以下是Python示例: - import whisper
- model = whisper.load_model("base")
- result = model.transcribe("audio.mp3")
- print(result["text"])
安装whisper后,可以根据以上说明直接命令行执行,会自动下载指定的模型:
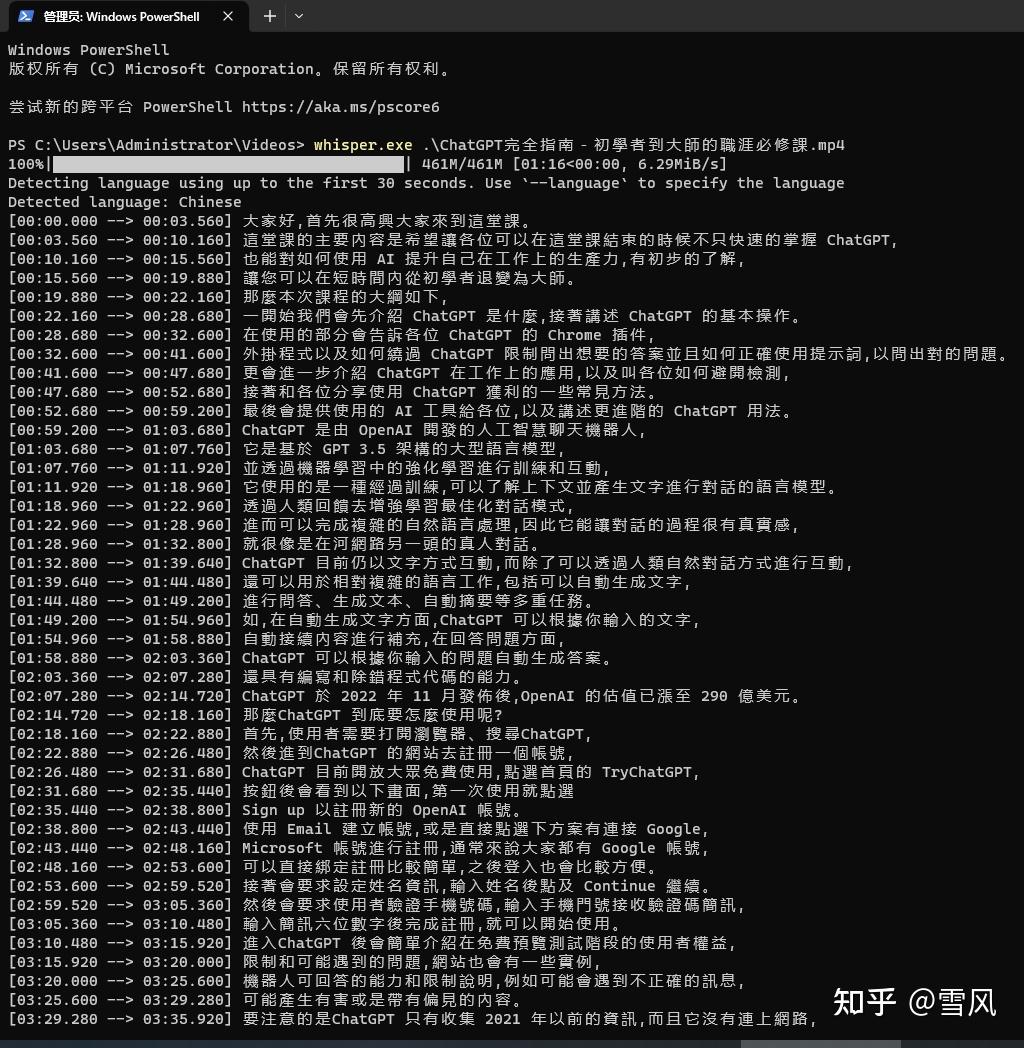
这里我是转换一个视频,会自动生成字幕格式的,使用非常方便:
除了直接识别语音生成文字和视频字幕,还可以直接转换中文为英文:
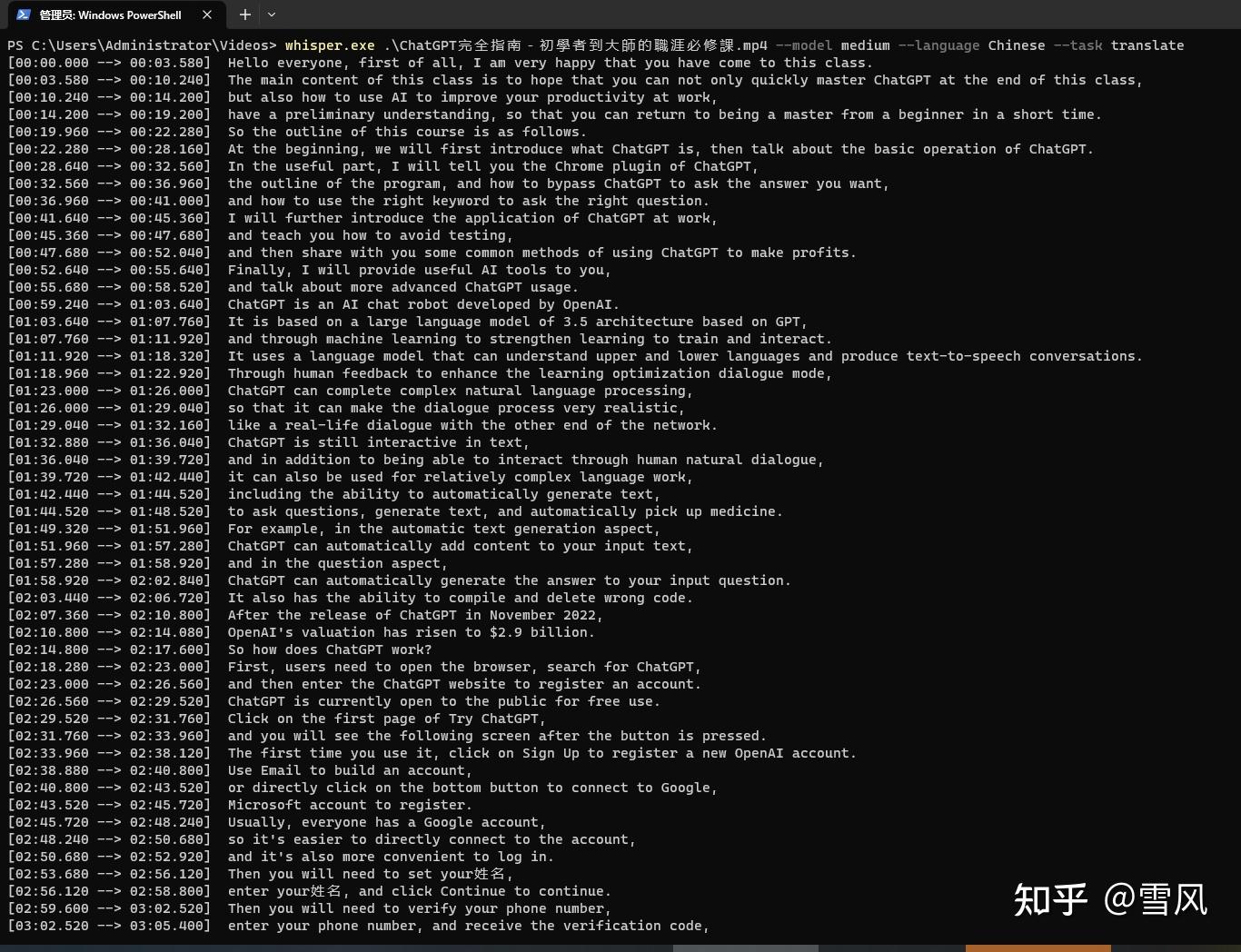
直接把中文视频生成英文字幕:
 补充:模型只自带了所有语言转英文的能力,那如果需要把英文翻译成中文怎么办?可以利用chatGPT实现,最简单的思路:1. 直接用whisper生成英文字幕,2. 把字幕文件发给chatGPT让它翻译,注意保持格式不变。这样就可以生成你需要的其它语言的字幕了,而且因为whisper识别英文能力很强,翻译出来的质量还很高。 - WEBVTT
- 00:00.000 --> 00:03.600
- 大家好,首先很高興大家來到這堂課
- 00:03.600 --> 00:10.200
- 這堂課的主要內容是希望讓各位可以在這堂課結束的時候不只快速的掌握ChatGPT
- 00:10.200 --> 00:14.200
- 也能對如何使用AI提升自己在工作上的生產力
- 00:14.200 --> 00:19.200
- 有初步的了解,讓您可以在短時間內從初學者蛻變為大師
- 00:19.900 --> 00:22.200
- 那麼本次課程的大綱如下
- 00:22.200 --> 00:25.400
- 一開始我們會先介紹ChatGPT是什麼
- 00:25.400 --> 00:28.000
- 接著講述ChatGPT的基本操作
- 00:28.800 --> 00:32.600
- 在使用的部分會告訴各位ChatGPT的Chrome插件
- 00:32.600 --> 00:37.000
- 外掛程式以及如何繞過ChatGPT限制問出想要的答案
- 00:37.000 --> 00:41.000
- 並且如何正確使用提示詞,以問出對的問題
- 00:41.800 --> 00:45.400
- 更會進一步介紹ChatGPT在工作上的應用
- 00:45.400 --> 00:47.800
- 以及教各位如何避開檢測
- 00:47.800 --> 00:52.000
- 接著和各位分享使用ChatGPT獲利的一些常見方法
- 00:52.800 --> 00:55.800
- 最後會提供使用的AI工具給各位
- 00:55.800 --> 00:58.600
- 以及講述更進階的ChatGPT用法

最后,做一个不同模型耗时测试,前面说了模型大识别更精确,但也更耗时,这里使用默认的small模型和指定的medium模型对比,转换一个1小时20分钟的视频,结果如下:
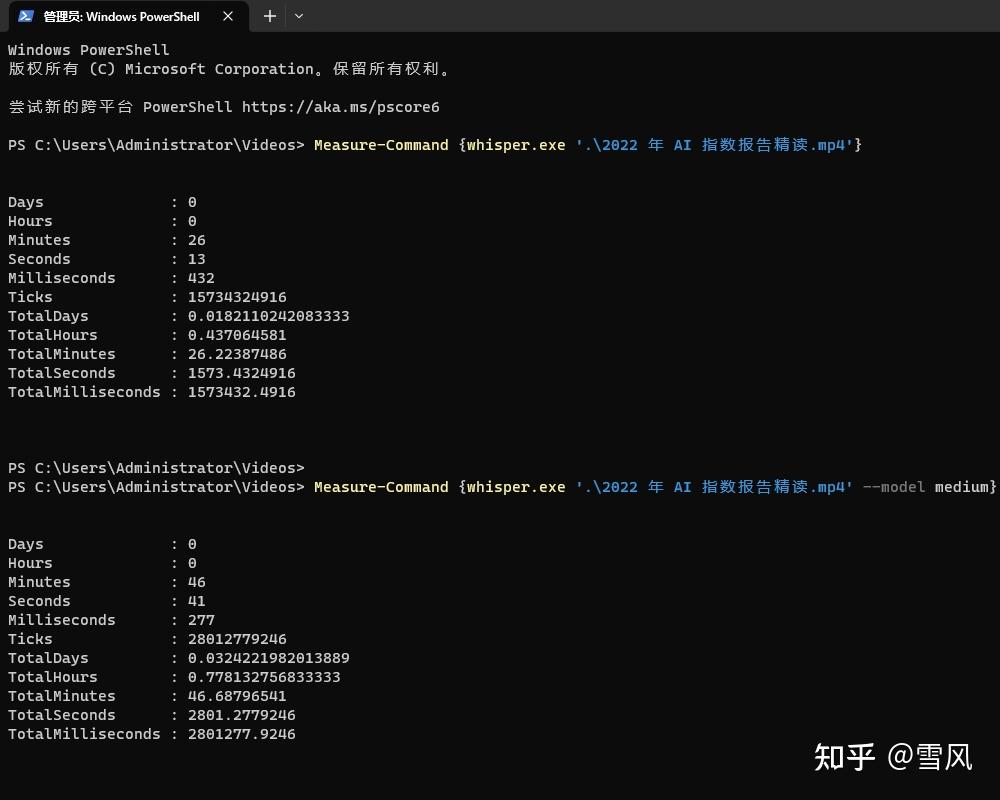
small模型耗时26秒13秒,medium模型耗时46分41秒。虽然耗时更长了,但识别结果的确是更准确,下面是内容对比,左边是medium模型识别结果,右边是small模型识别结果:
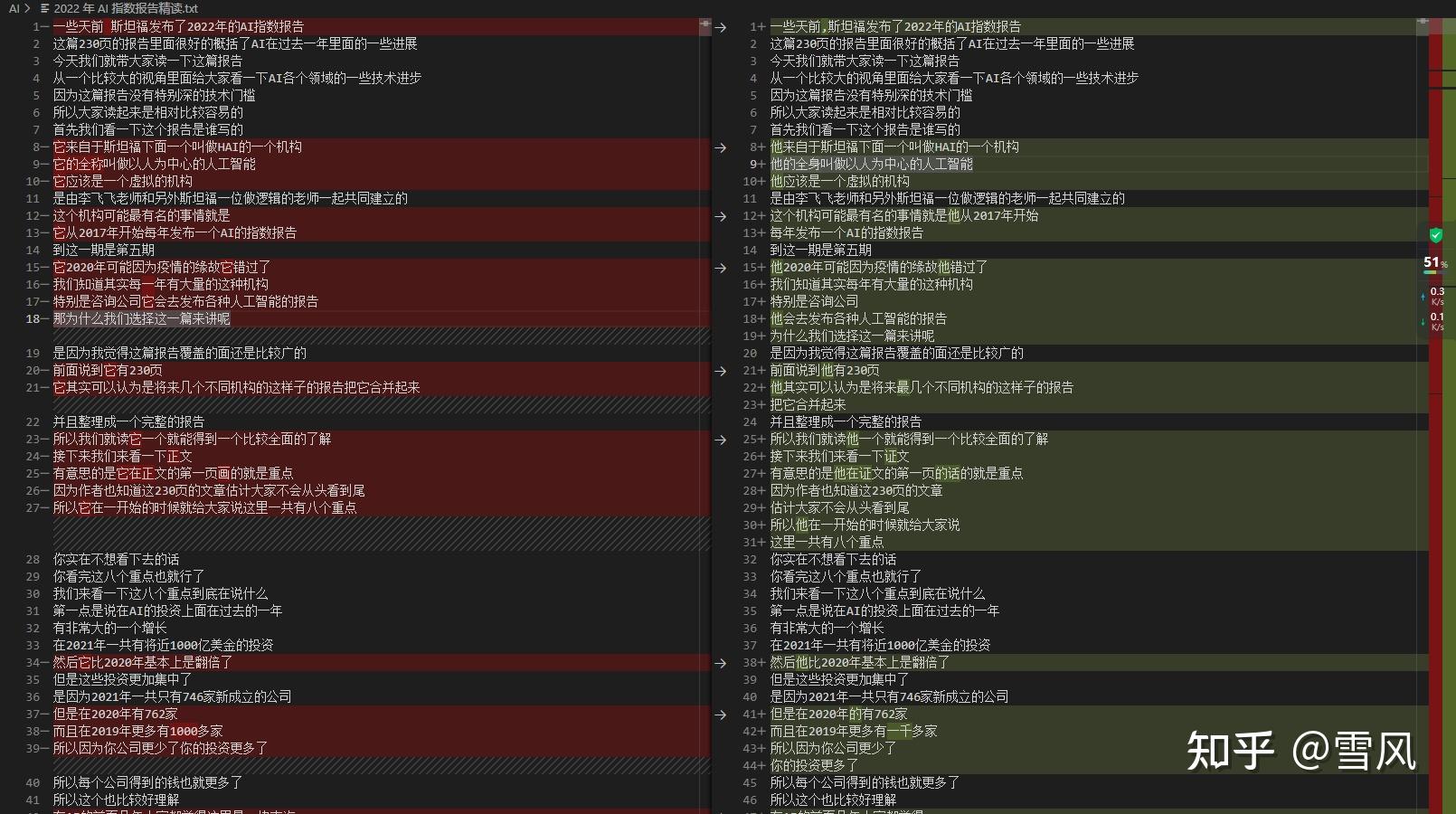
总体来说,如果你的显存足够,建议用更大的模型,否则直接用默认的small模型就好。
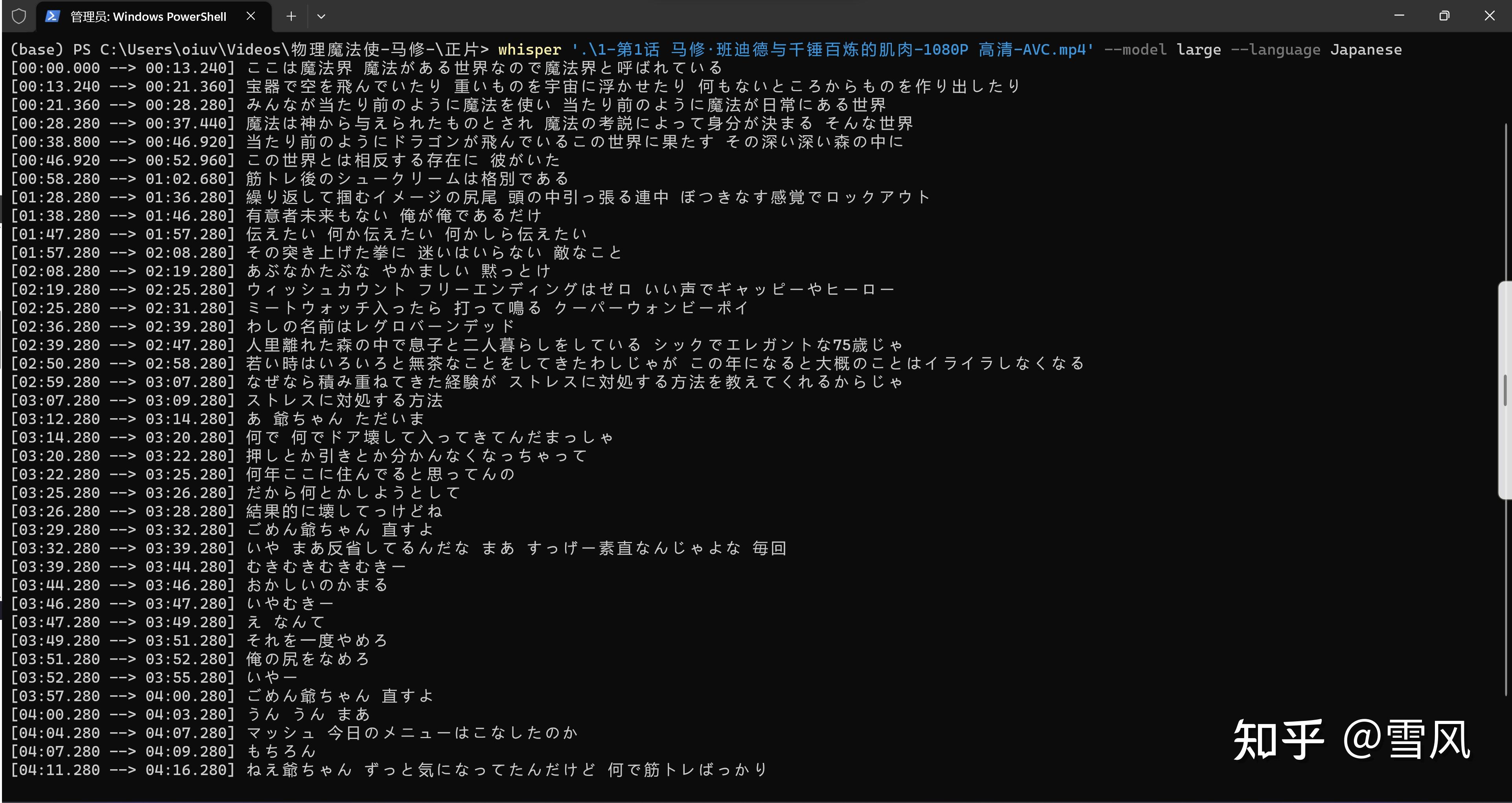
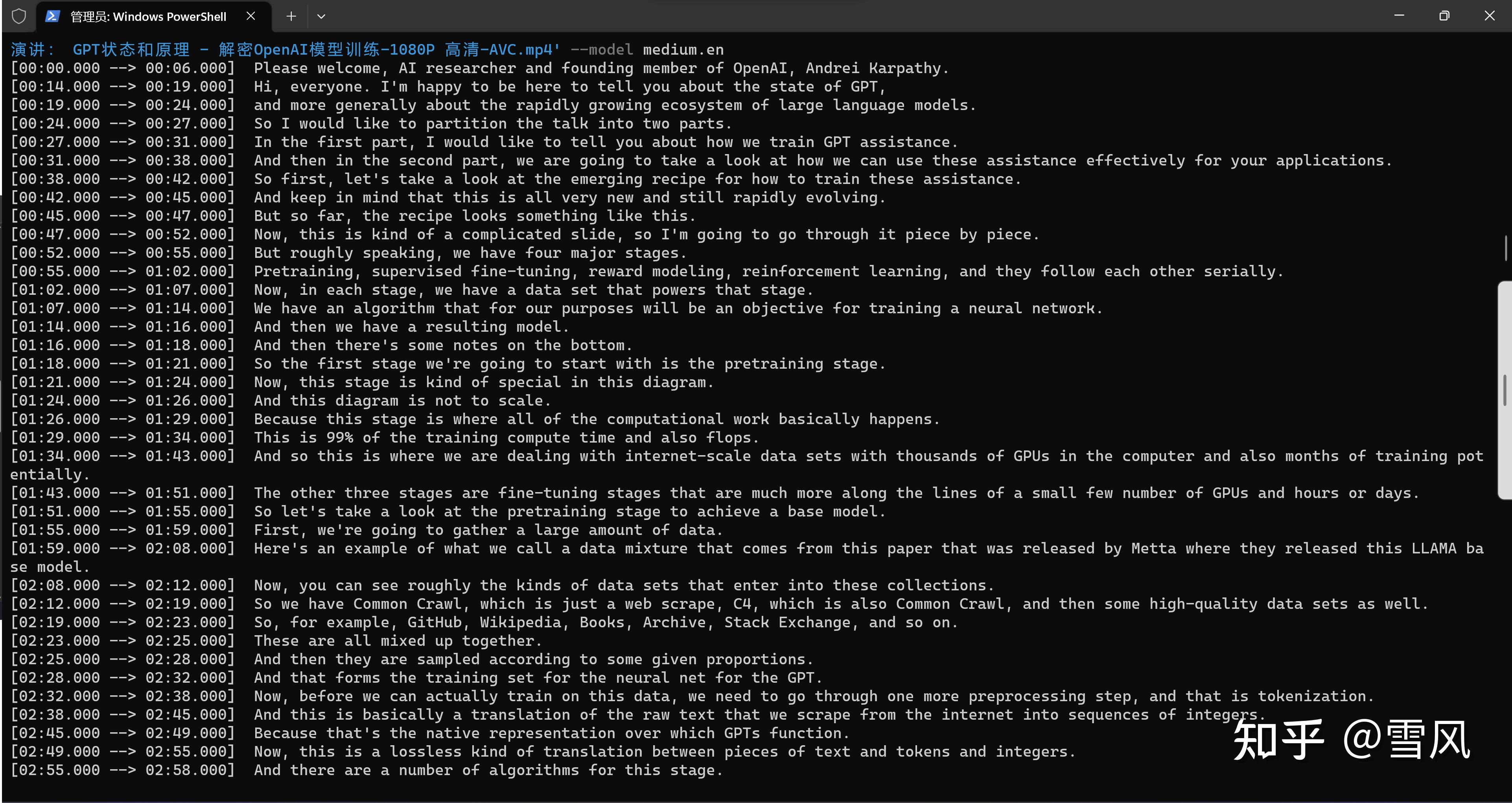
前面说了whisper模型最擅长的几中语言包括英语和日语,测试识别堪称完美:
<hr/>补充一下:有网友问怎么部署到树莓派上,因为whisper模型最小的也得要1G的显存呀,实际上是有大牛在whisper的基础上搞了一个C++版的whisper.cpp,对模型做了优化,需自己编译,可以在各种平台上运行:
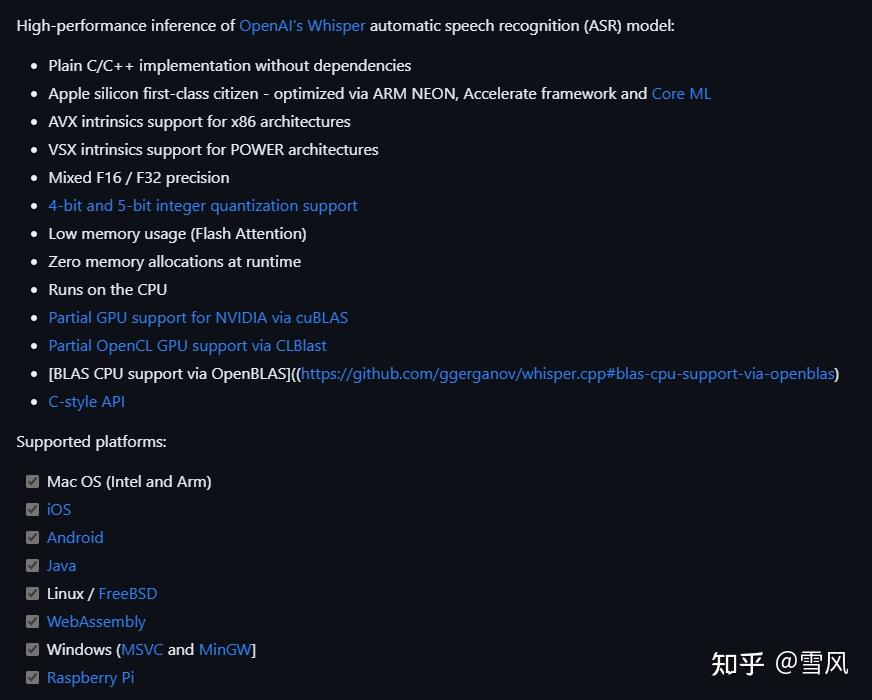
如果你是在显卡比较好的电脑上跑还是用官方的,否则可以用这个whisper.cpp,项目地址:
https://github.com/ggerganov/whisper.cpp |