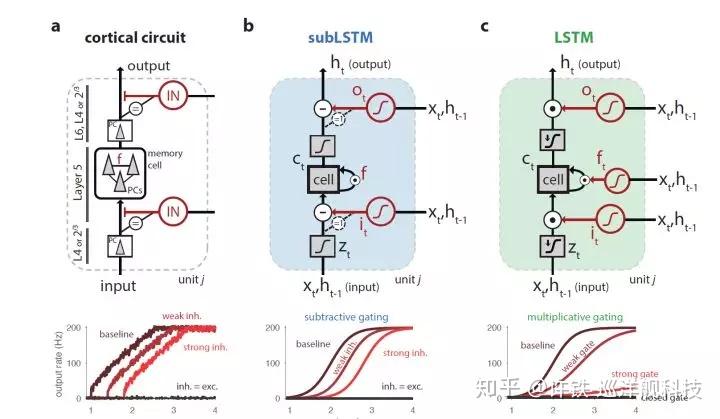
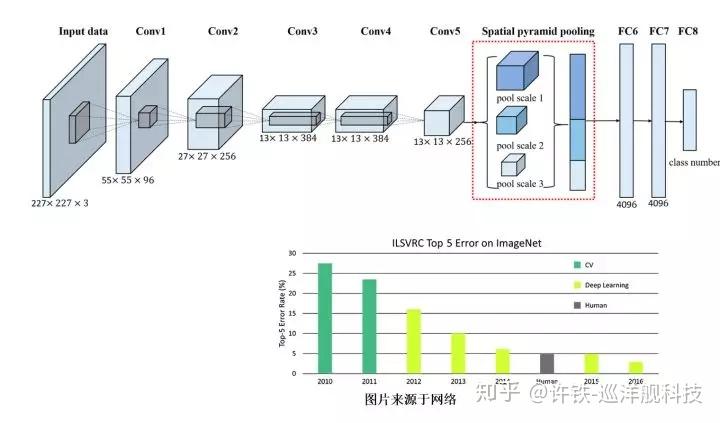
19-9-5更新:没想到这个回答收获了这么多赞,在前文基础上再补充一些内容。见文末。
19-9-24更新:后文补充了最新版本Gartner技术曲线。
20-3-15更新:后文补充了一些感知智能和认知智能的资料。
20-7-30更新:文末补充了Gartner Hyper Cycle for Artificial Intelligence 2019,及其他一些内容。
----------------------------------------
作为一名AI的从业者,应该可以回答这个问题。
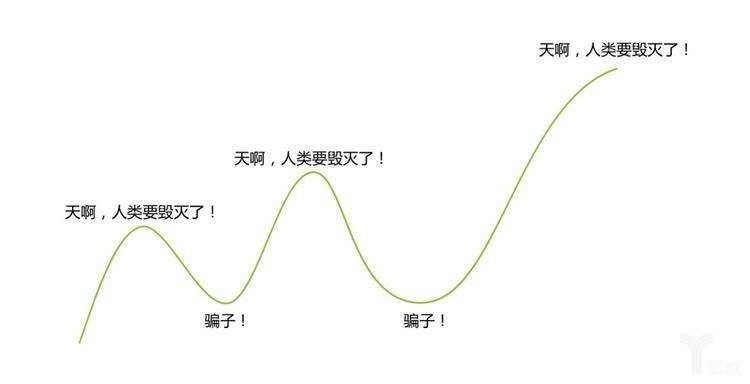
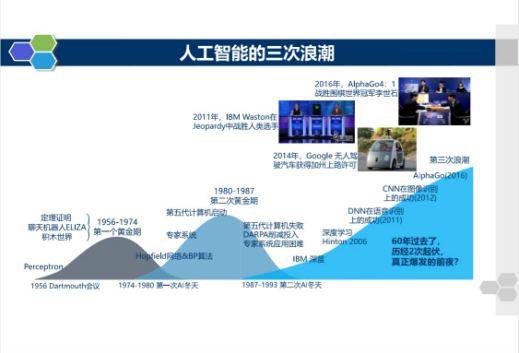
为什么大家对这类问题如此感兴趣? 这可能要追溯到2016年,AI真正进入到大众视野并引爆媒体的标志性事件,也就是 AlphaGo战胜围棋的世界冠军-李世石。在之后,我们看到一个又一个AI技术的突破,以及不断被刷新的媒体头条,好像AI取代人类是完全可能而且理所应当的事情。我们看到波士顿动力的机器人行云流水般的后空翻,看到索菲亚在各大场合欺骗人类感情,看到Dota2、星际争霸等游戏被AI攻破,也看到IBM的辩论机器人和人类旗鼓相当的交锋,在2019年7月份《Science》发表的研究成果中,一个名为Pluribus的算法仅仅通过自我博弈,就在多人无限注德州扑克中战胜了人类专业选手。人工智能在这第三轮的热潮中(人工智能从1956年被提出至今,经历了三次大的热潮。20 世纪50 年代中期到80 年代初期的感知器,20 世纪80 年代初期至21 世纪初期的专家系统,以及最近十年的深度学习技术,分别是三次热潮的代表性产物),通过大数据和深度学习,创造了一项又一项历史,也吊足了普罗大众的胃口。
以大数据为基础的深度学习,其实在理论上并未有突破,而是随着软件硬件的进步,达到了以往不可能企及的效果。因此,随着数据红利的消失,深度学习的天花板也逐渐显现。
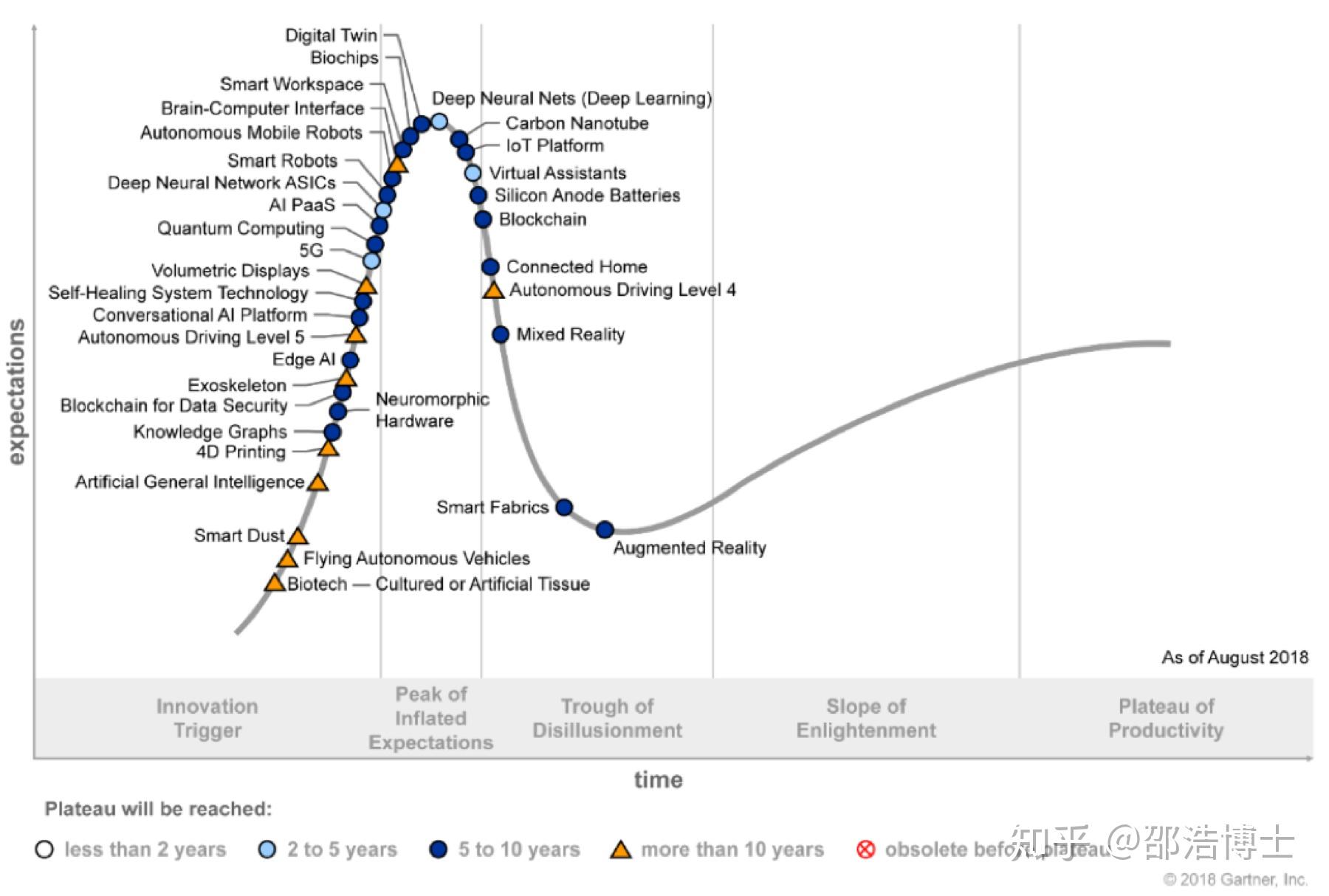
Gartner每年发布的技术趋势曲线,会聚焦在未来5到10年间,可能产生巨大竞争力的新兴技术。在图中我们可以看到,深度学习(Deep Learning)已经走到高原期(Peak of Inflated Expectations),而知识图谱(Knowledge Graph)还是在起步阶段(Innovation Trigger),更不用说脑机接口(Brain-Computer Interface)、通用人工智能(Artificial General Intelligence)这些技术,在图中的标记还是黄色三角,也就是起码10年会后才能到达高原期。
一个说法是,某一技术的代表性人物拿到图灵奖,就证明了这个技术已经不会再有突破性进展。而今年,深度学习的三位创造者Yoshua Bengio, Yann LeCun, 以及Geoffrey Hinton获得了2019年的图灵奖。所以深度学习的天花板也就到了。

人工智能技术远未达到媒体中所宣传的神通广大,无所不能,从技术发展现状也可一窥端倪。AlphaGo可以战胜最好的人类棋手,但却不可能为你端一杯水。著名机器人学者Hans Moravec早前说过:机器人觉得容易的,对于人类来讲将是非常难的;反之亦然。人可以轻松做到听说读写,但对于复杂计算很吃力;而机器人很难轻松做到用手抓取物体、以及走上坡路,但可以轻而易举地算出空间火箭的运行轨道。人类可以通过日积月累的学习,轻松完成各种动作,但对于机器人来讲完成这些简单的动作难如登天。专家们称此理论为“莫拉维克悖论”(Moravec's Paradox)。机器学习专家、著名的计算机科学和统计学家Michael I. Jordan近日在《哈佛数据科学评论》上发表文章,也认为现在被称为AI 的许多领域,实际上是机器学习,而真正的AI 革命尚未到来。
在目前,即使是最先进的AI智能体,在适应环境变化的能力方面,也无法与动物相提并论。近期,英国帝国理工学院和剑桥大学研究人员共同组织了一场特别的AI竞赛(http://www.animalaiolympics.com/),希望把动物能够完成的“觅食任务”交给AI智能体来完成,让AI和动物世界来一场虚拟比赛。我们也期待着这项比赛的结果。
另外,从商业角度上来看,AI企业拿到A轮之前的融资都还算是容易的。但所有的技术都需要经历市场的考验,到了A轮和B轮,AI企业的落地和盈利能力更被投资人所看重,但目前的事实是,AI技术落地仍然相当困难。即便落地为产品,其成本也极其高昂。所以,2018和2019年,有一大批的初创AI企业死于寒冬。
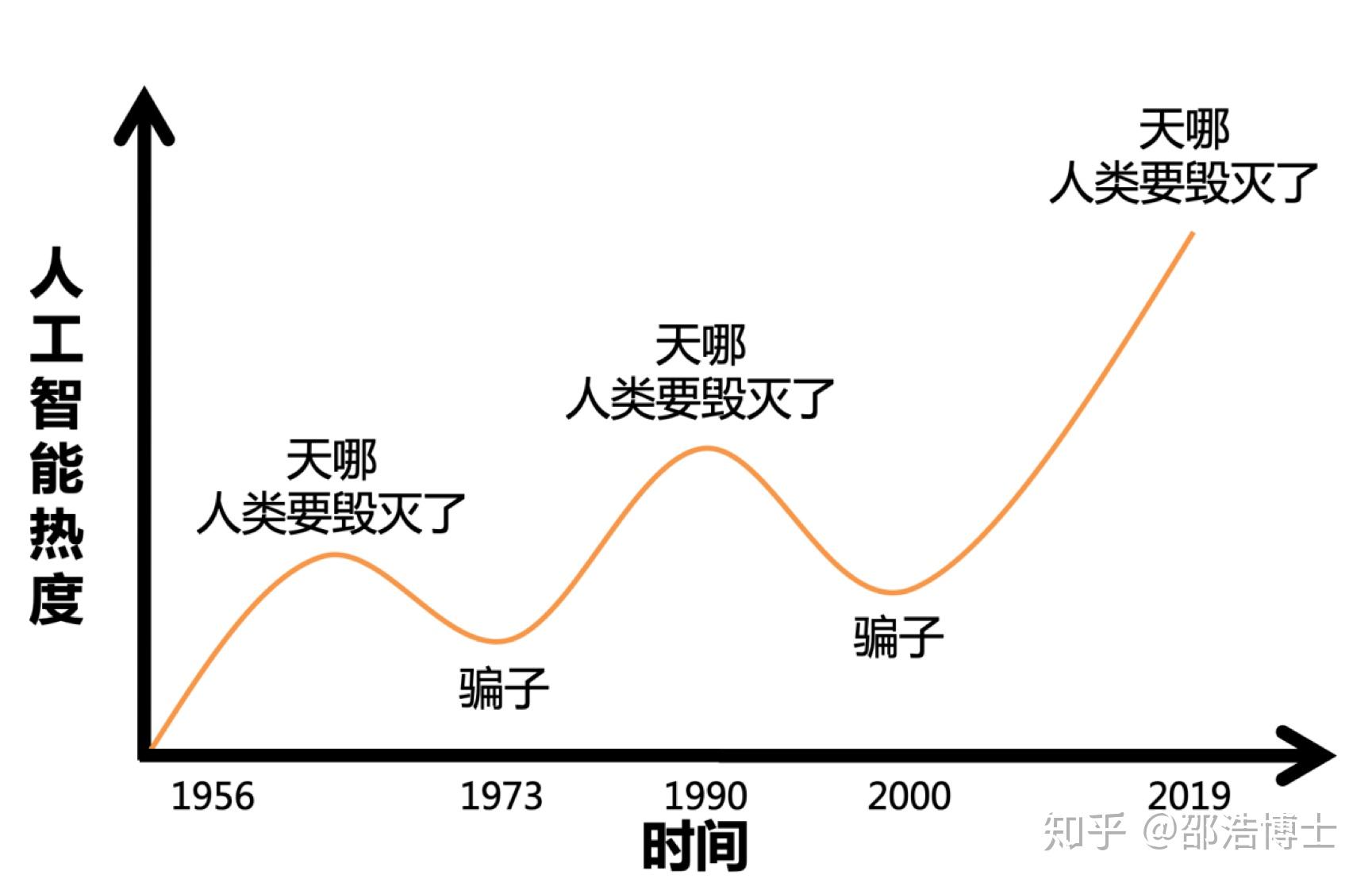
鲍捷老师曾经给出上面这幅图,体现了人工智能至今所经历的三次大的热潮。这次热潮过后,是衰落还是稳定发展,我们也拭目以待。
-------------------------------
19-9-5更新:
前面那个图提到的AI的三次热潮,在这里啰嗦解释一下:
第一阶段(20 世纪50 年代中期到80 年代初期):深耕细作,30 年技术发展为人工智能产业化奠定基础。在1956 年之前,人工智能就已经开始孕育。神经元模型、图灵测试的提出以及SNARC 神经网络计算机的发明,为人工智能的诞生奠定了基础。1956 年的达特茅斯会议代表人工智能正式诞生和兴起。此后人工智能快速发展,深度学习模型以及AlphaGo 增强学习的雏形——感知器均在这个阶段得以发明。随后由于早期的系统适用于更宽的问题选择和更难的问题时效果均不理想,因此美国、英国相继缩减经费支持,人工智能进入低谷。
第二阶段(20 世纪80 年代初期至21 世纪初期):急功近利,人工智能成功商用但跨越式发展失败。80 年代初期,人工智能逐渐成为产业,第一个成功的商用专家系统R1 为DEC 公司每年节约4000 万美元左右的费用。截止到20 世纪80 年代末,几乎一半的“财富500 强”都在开发或使用“专家系统”。受此鼓励,日本、美国等国家投入巨资开发第5 代计算机——人工智能计算机。在90 年代初,IBM、苹果推出的台式机进入普通百姓家庭中,奠定了计算机工业的发展方向。第5 代计算机由于技术路线明显背离计算机工业的发展方向,项目宣告失败,人工智能再一次进入低谷。尽管如此,浅层学习如支持向量机、Boosting 和最大熵方法等在90 年代得到了广泛应用。
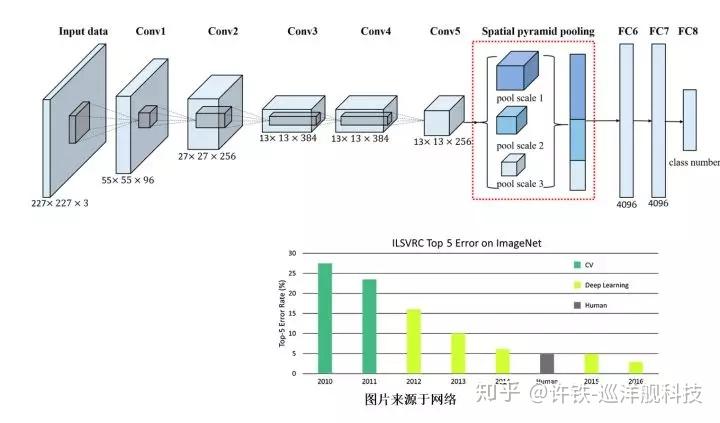
第三阶段(21世纪初期至今):量变产生质变,人工智能有望实现规模化应用。摩尔定律和云计算带来的计算能力的提升,以及互联网和大数据广泛应用带来的海量数据量的积累,使得深度学习算法在各行业得到快速应用,并推动语音识别、图像识别等技术快速发展并迅速产业化。2006年,Geoffrey Hinton和他的学生在《Science》上提出基于深度信念网络(Deep Belief Networks,DBN)可使用非监督学习的训练算法,使得深度学习在学术界持续升温。2012年,DNN技术在图像识别领域的应用使得Hinton的学生在ImageNet评测中取得了非常好的成绩。深度学习算法的应用使得语音识别、图像识别技术取得了突破性进展,围绕语音、图像、机器人、自动驾驶等人工智能技术的创新创业大量涌现,人工智能迅速进入发展热潮。
然后,人工智能的发展,有人给出了这样一张路线图:
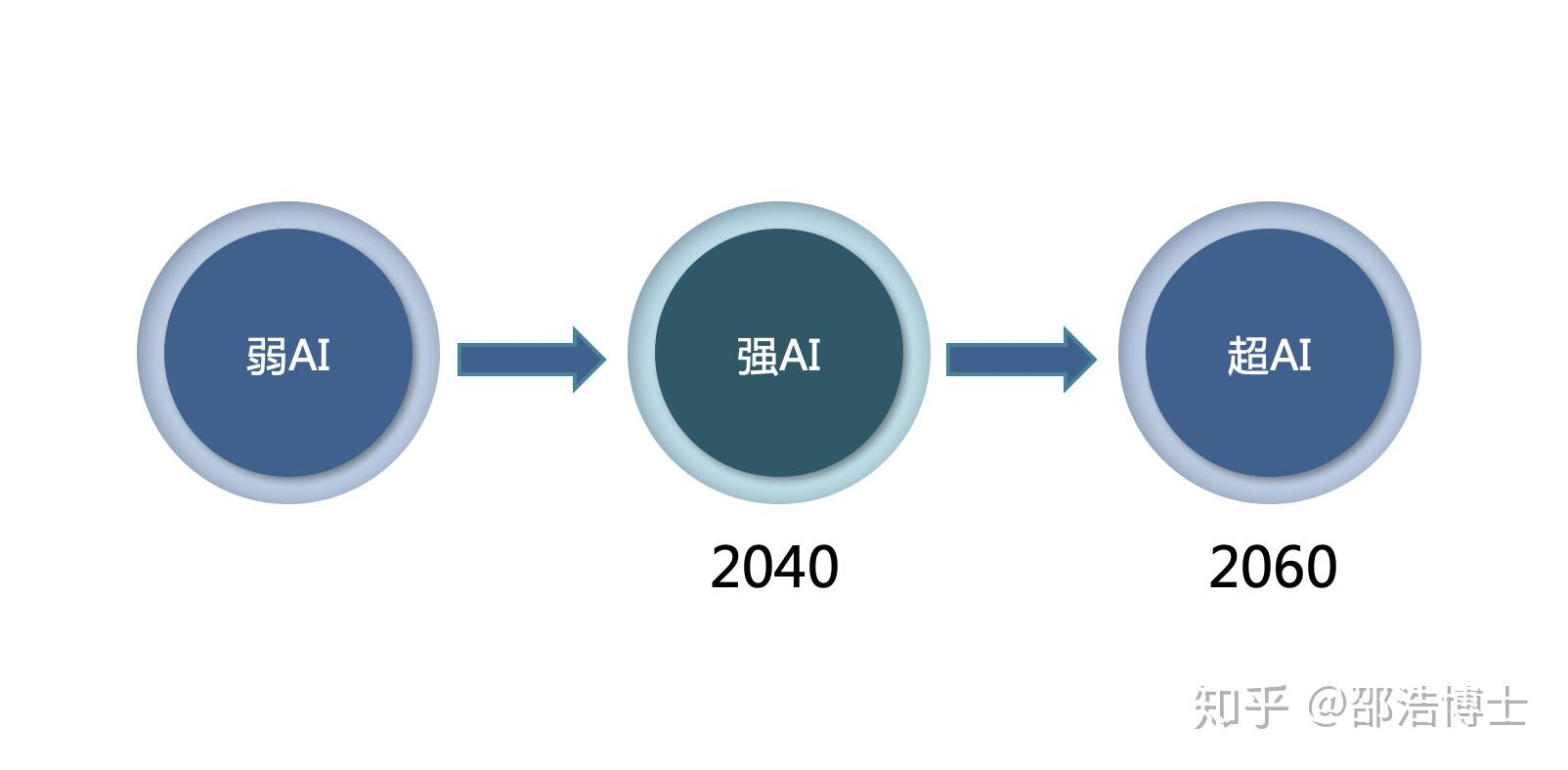
1. 弱人工智能Artificial Narrow Intelligence (ANI): 弱人工智能是擅长于单个方面的人工智能。比如有能战胜象棋世界冠军的人工智能,但是它只会下象棋,你要问它怎样更好地在硬盘上储存数据,它就不知道怎么回答你了。
2. 强人工智能Artificial General Intelligence (AGI): 人类级别的人工智能。强人工智能是指在各方面都能和人类比肩的人工智能,人类能干的脑力活它都能干。创造强人工智能比创造弱人工智能难得多,我们现在还做不到。Linda Gottfredson教授把智能定义为“一种宽泛的心理能力,能够进行思考、计划、解决问题、抽象思维、理解复杂理念、快速学习和从经验中学习等操作。”强人工智能在进行这些操作时应该和人类一样得心应手。
3. 超人工智能Artificial Superintelligence (ASI): 牛津哲学家,知名人工智能思想家Nick Bostrom把超级智能定义为“在几乎所有领域都比最聪明的人类大脑都聪明很多,包括科学创新、通识和社交技能。”超人工智能可以是各方面都比人类强一点,也可以是各方面都比人类强万亿倍的。超人工智能也正是为什么人工智能这个话题这么火热的缘故。
-------------------------------
19-9-24更新:
Gartner官网更新了2019年技术曲线。
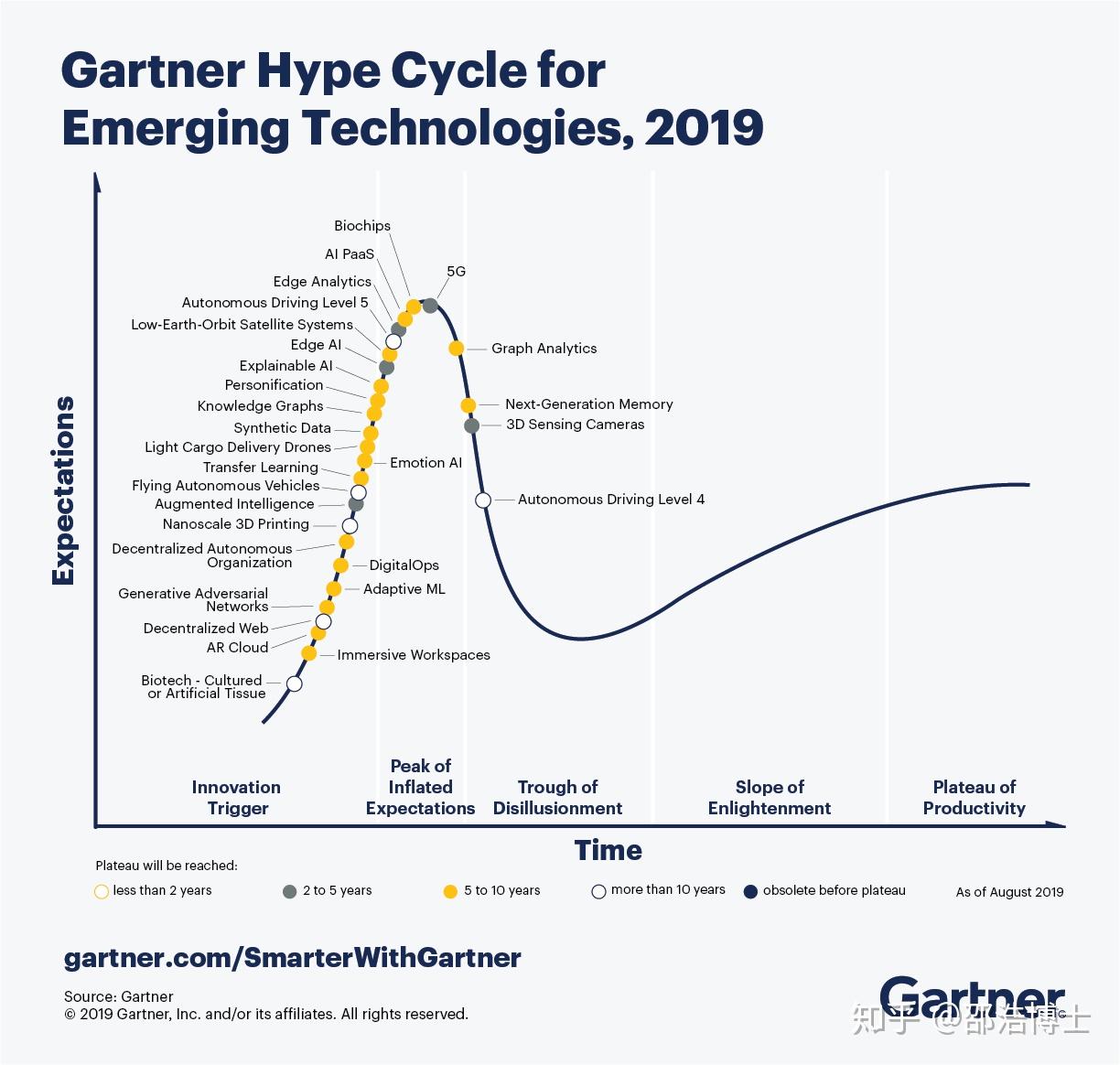
跟2018年的曲线相比,我们可以发现哪些有趣的点?首先,深度学习没有在图上显示了。然后,即便是L4的自动驾驶,也是标记为“超过十年”。知识图谱、AI PAAS等依然是5-10年,但比2018进展了不少。同时,AI生物材料等开始涌现。
不过这个图是截止时间是8月份,显然没有考虑到Google最近发布的量子计算。美国谷歌公司研究人员在美国国家航空航天局(NASA)官网上发表论文,称其所研究的量子计算机仅需3分20秒就可完成目前全球最快超级计算机(“超算”)Summit需一万年才能完成的计算。
这说明了什么?在目前AI没有实质突破的情况下,即便是Google的这个量子技术无法快速落地,也让我们看到了下一代的新技术的曙光。
-------------------------------
20-3-15更新:
什么是感知智能?什么是认知智能?
业界一致认为,AI的三要素是算法,算力和数据。近十年来,人工智能的技术突破,很大程度上是得益于大数据以及大规模运算能力的提升,真正让深度学习这项“老”技术焕发了新生,突破了一项又一项感知能力。追溯到2006年,Geoffrey Hinton和他的学生在《Science》上提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督学习的训练算法,随后2012年深度神经网络技术在ImageNet评测[1]中取得了突破性进展,人工智能进入到新的热潮,围绕语音、图像、机器人、自动驾驶的技术大量涌现,也出现了很多里程碑水平的技术。
2017年8月20日,微软语音和对话研究团队负责人黄学东宣布微软语音识别系统取得重大突破,错误率由之前的5.9%降低到5.1%,可与专业速记员比肩[2];Google在2015年提出的深度学习算法,已经在ImageNet2012分类数据集中将错误率降低到4.94%,首次超越了人眼识别的错误率(约5.1%)[3];DeepMind公司在2017年6月发布了当时世界上文本到语音环节最好的生成模型WaveNet语音合成系统[2];由斯坦福大学发起的SQuAD[3](Stanford Question Answering Dataset)阅读理解竞赛,截至2019年7月,使用BERT的集成系统暂列第一,其F1分值达到89.474,超越了人类水平。
从计算,到感知,再到认知,是大多数人都认同的人工智能技术发展路径。那么认知智能的发展现状如何呢?
首先,让我们看一下什么是认知智能。复旦大学肖仰华教授曾经提到,所谓让机器具备认知智能是指让机器能够像人一样思考,而这种思考能力具体体现在机器能够理解数据、理解语言进而理解现实世界的能力,体现在机器能够解释数据、解释过程进而解释现象的能力,体现在推理、规划等等一系列人类所独有的认知能力上。
也就是说,认知智能需要去解决推理、规划、联想、创作等复杂任务。我们可以大胆想象,如果机器人具备了认知智能,那么我们周围就会出现很多电影里才能看到的智能机器,比如说《银翼杀手2049》里的乔伊,《她》中的萨曼莎,以及《超能查派》里的机器人查派,这些智能机器会有意识,有情感,并且有自己的善恶观。
人类总是想当造物主,让机器拥有认知智能,其实在一定程度上是希望模仿生命本身,尤其是人类的各种能力。在维基百科给出的定义中,生命泛指一类具有稳定的物质和能量代谢现象并且能回应刺激、能进行自我复制(繁殖)的半开放物质系统。简单来说,也就是有生命机制的物体,是存在一定的自我生长、繁衍、感觉、意识、意志、进化、互动等丰富可能的一类现象。科学家从来没有停止对生命的再造和探索,也就自然而然产生了“人工生命”(Artificial Life)的概念。人工生命可以分为两个方面,一是人造生命,特指利用基因工程技术创造的人工改造生物。另一方面则是虚拟生命(Virtual Life),特指利用人工智能创造的虚拟生命系统。
而我们知道,从感知到认知智能的鸿沟非常之大,至少从目前的技术程度上来讲,我们离认知智能还有非常远的距离。
比如说我们都觉得聊天机器人应该是一个人工智能的认知智能的代表。现在市面上这么多智能音箱,对话机器人,AI电话,是不是已经实现了认知智能呢?答案是否定的。
微软亚洲研究院宋睿华老师(微软小冰首席科学家)曾经说过一个故事,她在和母亲聊天的时候,问“如果机器人可以打败人类最顶尖的棋手,厉不厉害?”,母亲回答说“很厉害“。她再问母亲”如果我们做出一个机器人,可以和人聊天,厉不厉害?“,母亲回答说”不厉害“。宋老师就问为什么,母亲的回复是”因为不是每个人都会下棋,但每个人都会说话啊“。这个故事其实告诉我们,让机器人说话,虽然技术上非常复杂,但离人类的期望值还相差甚远。
即便是机器人可以聊天,那是不是就可以说其拥有了认知智能?答案仍然是否定的。会说话的机器很多,不仅仅是聊天机器人,智能客服,甚至是推销电话都可以做到以假乱真的程度。谷歌在2018年开发者大会上演示了一个预约理发店的聊天机器人,语气惟妙惟肖,表现相当令人惊艳。相信很多读者都接到过人工智能的推销电话,不去仔细分辨的话,根本不知道电话那头只是个AI程序。破解方法其实也很简单,问机器人一句“今天天气挺好的,你觉得呢”,相信很多推销电话就无法回答了。这是因为,在特定场景下,对话可以跳转的状态一般都是有限的,可能产生的话题分支,比起围棋的可能性要少很多,因此,即便是穷举所有的可能性,也不是不可做到的事情。如果提前设置好对话策略,加上语音合成技术,完全可以以假乱真,但一旦在开放域进行闲聊,对话的可能性几乎是无限的,场景对话技术也就无能为力了。
-------------------------------
20-7-30更新:
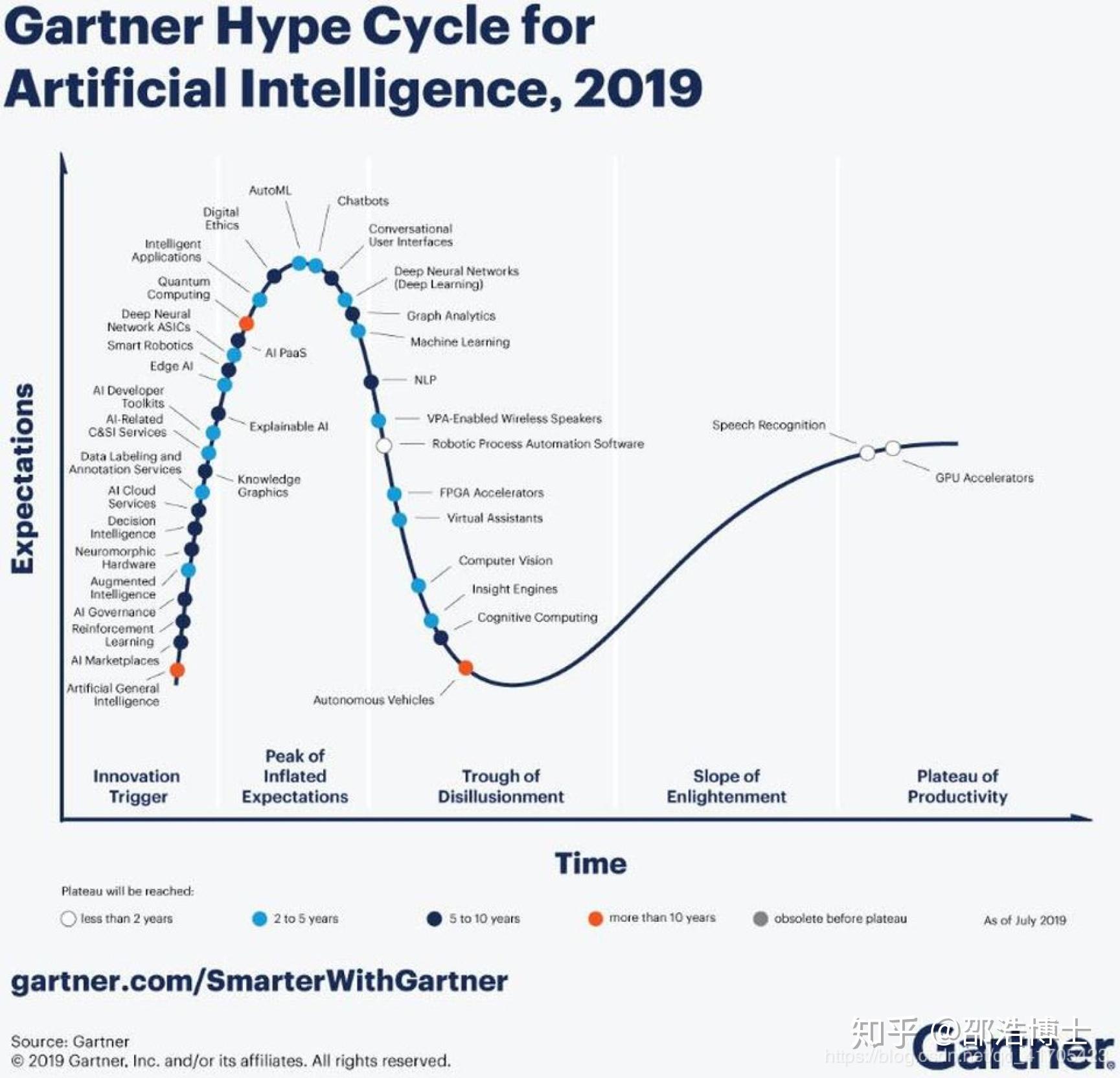
这一张图和上面的图不一样,上面的是Gartner Hyper Cycle for Emerging Technologies,而这张图是Gartner Hyper Cycle for Artificial Intelligence 2019
2019的技术曲线图里,语音技术和GPU加速技术已经趋向成熟,基于深度学习的计算机视觉技术也即将走向成熟。而认知相关的自然语言处理、知识图谱仍然需要较长的时间发展。和手机相关的其他技术例如端侧AI,也需要长时间的沉淀。而通用人工智能技术、自动驾驶、量子计算还遥遥无期(红点所示)。按照中国工程院院士李德毅的说法,无人驾驶在2025年之前都将处于产品孵化期,大规模量产预计要到2060年。也在另一层面印证了只有认知智能真正的实现,无人驾驶才能真正达到L5级别。
在这里再补充阐述一下语音助手,或者聊天机器人的尴尬处境。聊天机器人曾经被认为是AI时代的入口级产品,但现在回头来看,聊天机器人还远未达到入口的级别。而且离人类的期望值也有很大差距。
在人类的聊天中,一句话所包含的文字,所反应的内容仅仅是冰山一角。比如说“今天天气不错”,在早晨拥挤的电梯中和同事说,在秋游的过程中和驴友说,走在大街上的男女朋友之间说,在倾盆大雨中对同伴说,很可能代表完全不同的意思。在人类对话中需要考虑到的因素包括:说话者和听者的静态世界观、动态情绪、两者的关系,以及上下文和所处环境等,如下图所示。
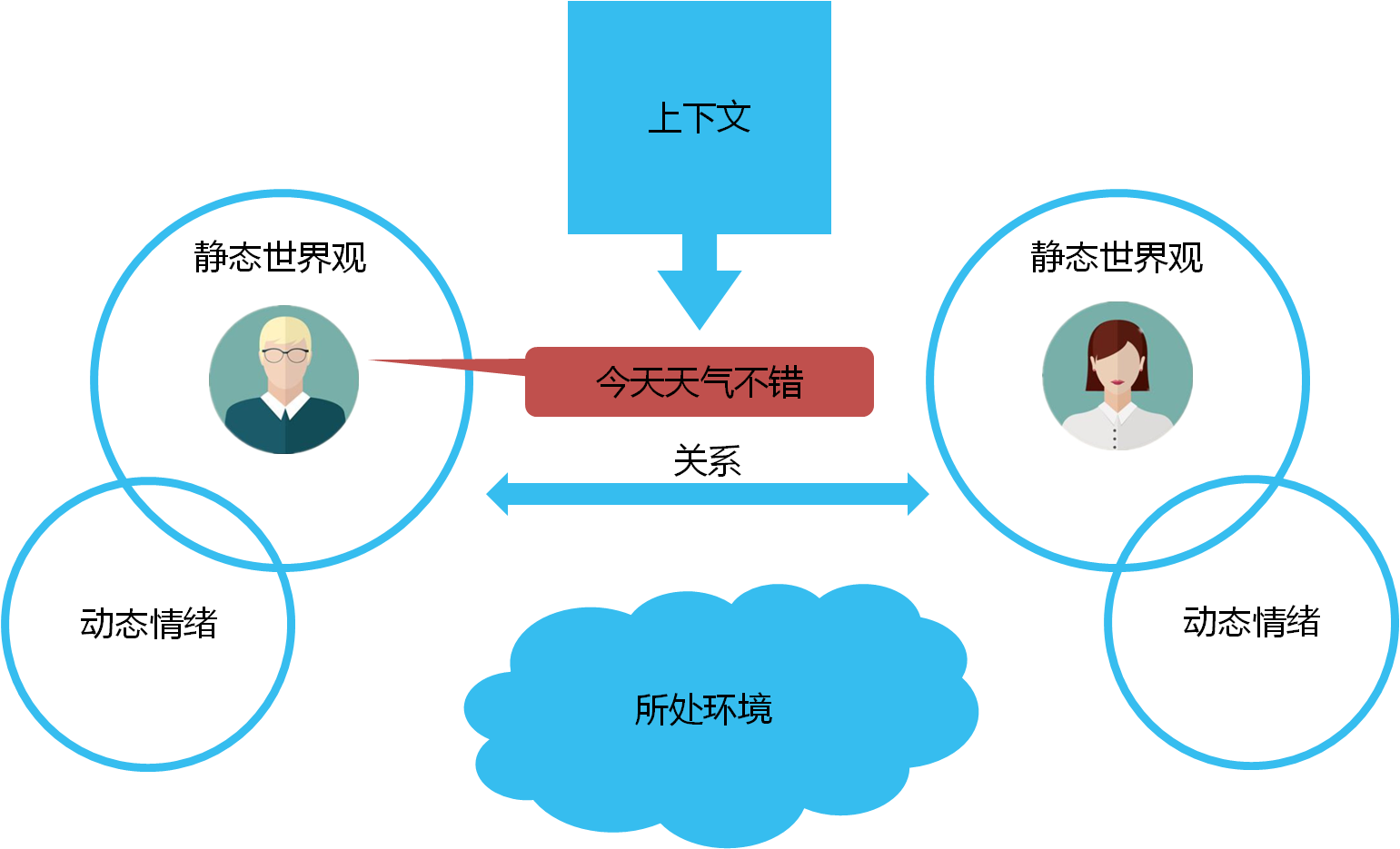
静态世界观:人类在成长过程中会建立起自己的世界观,一般跟跟经历和记忆有关。比如说一个素食主义者可能会非常厌恶谈及红烧肉的话题,又比如提及粉笔划玻璃,会让一部分人很不舒服,但对另一部分人却没任何影响。同时,对话的过程中也会触发一些相关联想,比如提到情人节,会想到玫瑰花和巧克力,提到下雨天就会想到雨伞等。鲁迅在《而已集·小杂感》也曾写道“一见到短袖子,立刻想到白臂膊,立刻想到全裸体,(略),中国人的想像惟在这一层能够如此飞跃”。
动态情绪:表现在交互过程中的表情、动作、语气等。因为人类的交互过程通常需要接收多方面信息源,在不同语气、不同表情,所表达的含义有可能完全不同。比如说“我恨你”,在恋人间轻柔的对话中很可能代表“我真的很喜欢你”。
说话者和听者的关系:对话双方是敌人、家人、朋友还是恋人,话语中所表达的意思就会有所区别。就比如刚刚的例子“今天天气不错”,在分手多年的恋人见面时说,很可能就代表“你现在过得好么”。
上下文:相同的词语和句子,在不同的上下文中也会有不同的含义。“我洗头去了”用于微信和QQ聊天中,很可能就代表“我不想聊了,再见”的意思。
所处环境:在不同场景下,相同话语会触发不同的反馈。如果在厕所和人打招呼用“吃过了么”就会显得非常尴尬了。
而且,以上这些都不是独立因素,整合起来,才能真正反映一句话或者一个词所蕴含的意思。这就是人类语言的奇妙之处。同时,人类在交互过程中,并不是等对方说完一句话才进行信息处理,而是随着说出的每一个字,不断的进行脑补,在对方说完之前就很可能了解到其所有的信息。再进一步,人类有很强的纠错功能,在进行多轮交互的时候,能够根据对方的反馈,修正自己的理解,达到双方的信息同步。在回过头看开放域的聊天机器人,寄希望于从一句话的文本理解其含义,这本身就是很不靠谱的一件事情。
目前市场上大部分的聊天机器人,还仅是单通道的交互(语音或文本),离人类多模态交互的能力还相差甚远。哪怕仅仅是语音识别,在不同的噪音条件下也会产生不同的错误率,对于文本的理解就更加雪上加霜了。
最近有个新闻,是说马维英从字节跳动回归学术圈。这也在另一方面印证着这一波人工智能退潮期的到来。

马维英,AI学术大牛、前MSRA常务副院长、字节跳动副总裁、AI实验室负责人……
距离加盟字节跳动3年之后,又辞职挂印而去,重返学术界。字节跳动官方证实,马维英的离任,「因为个人兴趣」。
但原因仅仅如此么?还是说,AI在落地的过程中存在着种种困难?
无论是苹果、三星,还是华为,vivo,oppo,小米,手机厂商在今年的发布会上也不怎么提AI了,大家会发现,很多旗舰机悄悄的把前两年大力推广的“AI按键”也给取消了。这也是人工智能难以落地的又一印证吧。
[1] https://www.kaggle.com/c/imagenet-object-localization-challenge
[2] https://deepmind.com/blog/wavenet-generative-model-raw-audio/
[3] http://stanford-qa.com |