作为数据科学的新手,你是否因为没有实践经验,在面试中屡屡被diss?如果是的话,你可以从《A Collection of Data Science Take-Home Challenges》“借”一个项目经验,让面试官对你刮目相看。
前言
有很多同学私信我,反映我发表的内容有点“硬核”,询问有没有适合算法新手的内容?或者数据科学的知识需要掌握到什么程度才能在互联网行业找到一份入门级别的算法工作?
对于第一点,我是同意的。我发表的关于推荐算法的很多内容,都需要读者有推荐、广告、搜索的实际工作经验,才能理解。否则,你未必能够意识到在小数据集下常规操作,却在“推广搜”海量数据、高维稀疏、在线持续更新的环境下根本不可能完成。意识不到问题的存在,无法对要解决的痛点感同身受,自然也就无法理解算法的精髓。
至于第二点,互联网算法工程师的入门级基本技能有哪些?倒让我想起了我在美国准备进入这个行业时所准备的TakeHome Challenge。
TakeHome Challenge是硅谷大厂考察数据科学人才的基本形式,一般用于一面。
- 筛选简历后,大厂会给候选人发一道考题。
- 题目包含一份数据,一般是该公司真实数据的脱敏版本。数据量不大,一般也就几万条,保证单机能够跑得通。
- 所问的问题,也来自该公司业务的真实场景。
- 要求候选人在规定时间内(不同公司有不同规定,一般1~3天),利用所提供的数据建立模型,回答所提问题,帮助公司改善产品。
- 提交作业的形式,要包含你的代码和你的分析过程。
- 也算是开卷考试,也不怕你请枪手,反正后面还有其他面试环节。
其实这种考察形式还挺重要的,可惜国内用得不多。和面试时让你白板写程序一样,考察的都是候选人的实际动手能力,毕竟talk is cheap, show me your codes。候选人提交的作业能够很大程度上反映他的解决数据问题的真实水平,包括:代码能力、建模能力、产品意识、沟通表达能力等。特别是针对校招生,因为没啥项目经验可聊(如果有的话,这样的校招生就太受欢迎了),如果只考察机器学习算法理论,很难保证招来的人能够干活(编程题考察的是写程序的水平,未必是解决算法实际项目的水平)。其实对于社招也应该适用,毕竟P7跳槽时要被要求白板编程也不算新闻了,再多做一个takehome challenge也不算太过分,毕竟考察的都是基本功,免得招来一个只知道写ppt和周报的“邵式兄弟”。
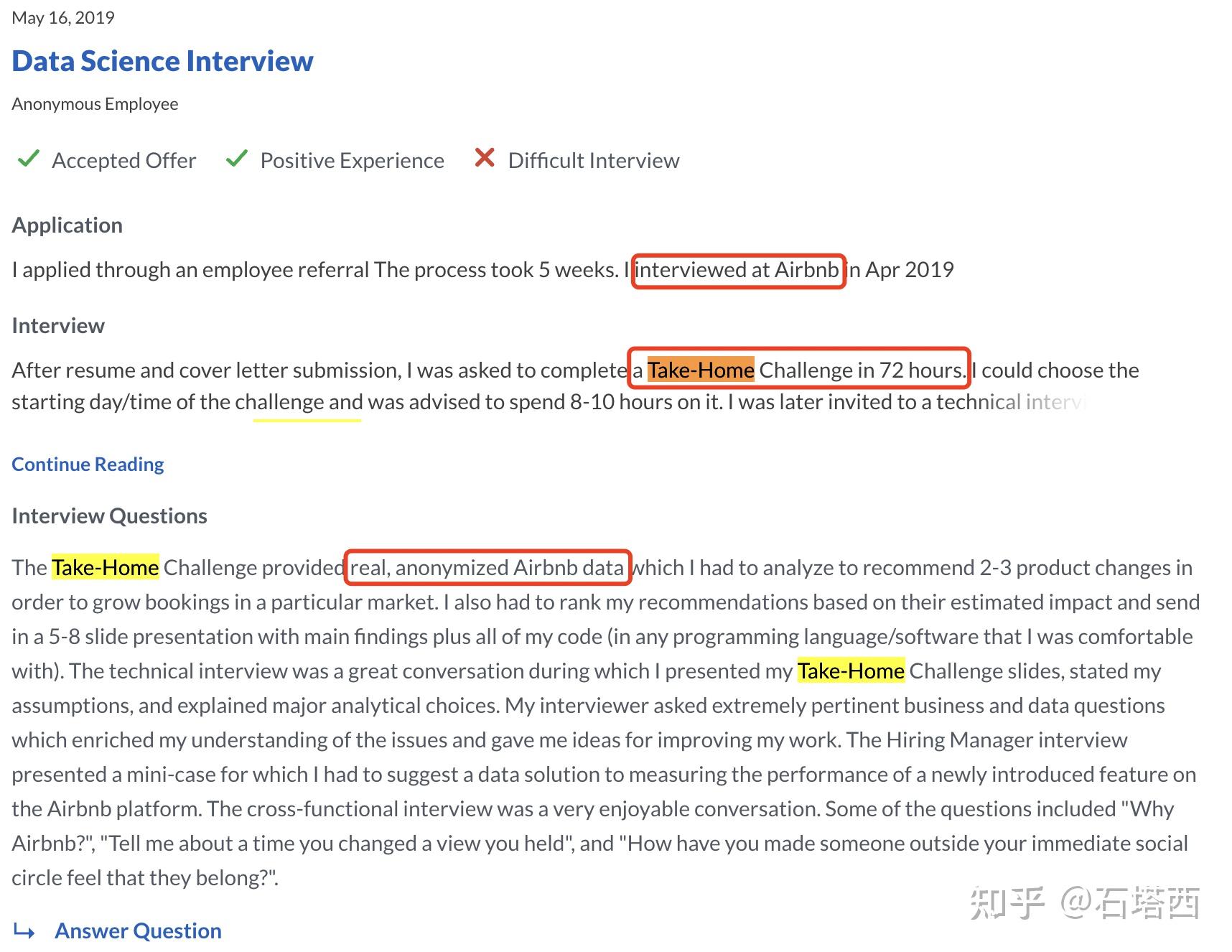
我亲身经历过Airbnb的takehome challenge,和下图的差不多。因为我对这种考察形式有所准备,也顺利通过了。不过后来就covid-19了,airbnb就开始裁员了,晕:-c。不过说回来了,虽然takehome challenge国内大厂用得不多,但是面试官要考察的点总是相通的,无非就是代码能力、数据处理能力、建模能力、评估能力、表达沟通能力等那几样。知道了考点,候选人可以在面试中主动体现自己在相关能力上的优势,比如“我做过一个项目,提取过几个有意思的特征,......”。我是非常欣赏这种候选人的,说明他是内行人,也是个聪明人。
怎么准备TakeHome Challenge?
综上所述,准备takehome chanllenge对于数据科学的工作面试还是大有帮助的,特别是对项目经验不足的校招生。那该如何准备呢?
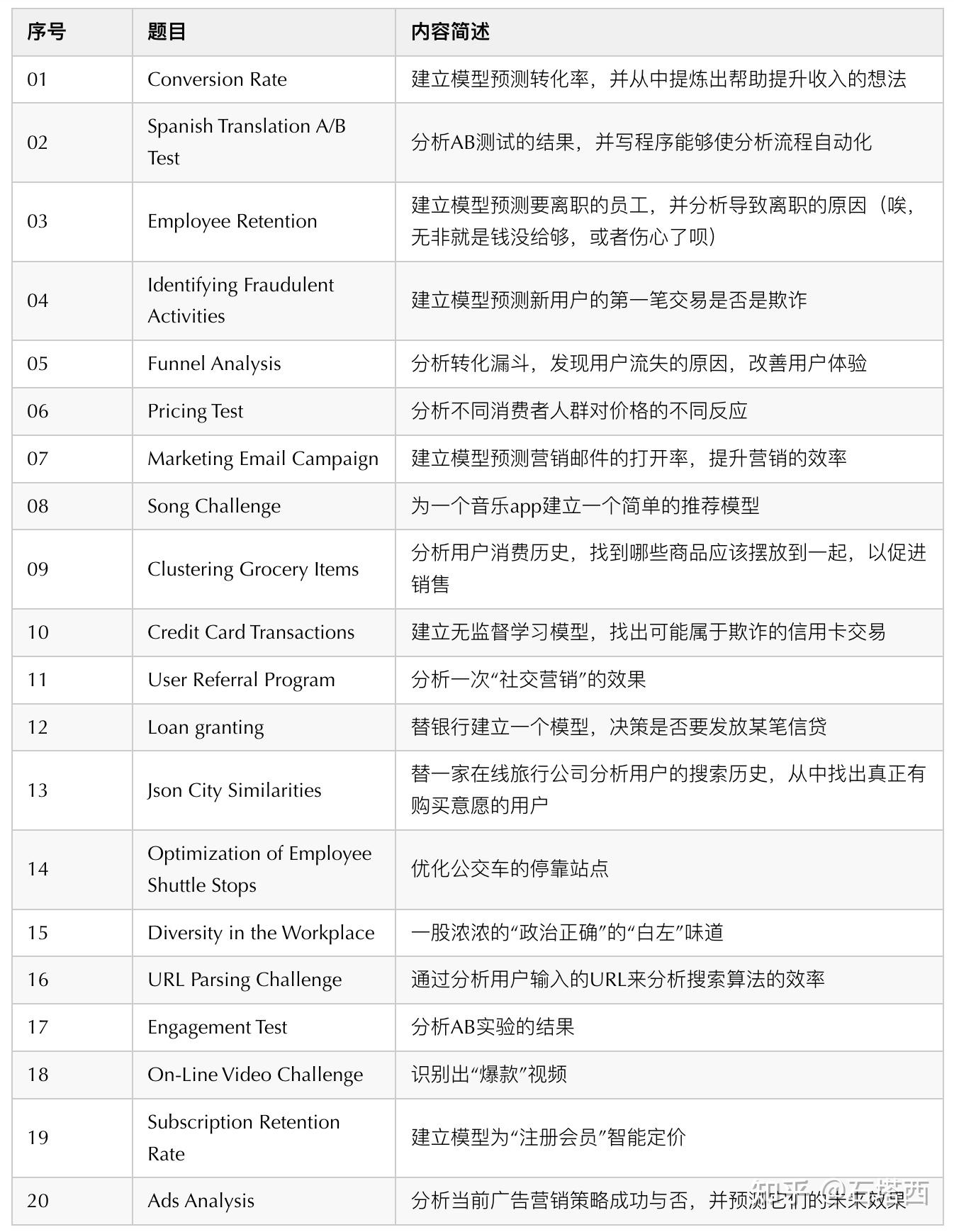
这里我推荐一本书《A Collection of Data Science Take-Home Challenges》。这本书是我当初跨行进入数据科学领域,准备第一场面试时的复习资料,当初也花了我大几十刀(这还只包括题目和数据集,不包括答案)。这本书出了20道题目,类似高考前的模拟卷,“黄冈真题”。
目前来看,这几十刀还是值得的。
- 一来,从以上内容可以看出,
- 这本书涵盖了多种类型的互联网业务,比如:电商、内容媒体、银行、在线旅游、......等。
- 另外也涵盖几乎所有的数据应用场景,比如:推荐、广告、搜索、风控、运营、数据分析、......等。
- 二来,所提的问题都来源于真实的业务场景,题目中的数据集也能够反映出真实的数据环境,从而帮你加深对某一具体业务的理解,使你在面试中看起来像是个“内行”。
如果你是一个想进入互联网行业从事数据工作的有志打工好青年,看了N本书,上了N门网课,感觉理论知识也学得差不多了,苦于没有项目实战经验,不妨从这本书中“借”一个项目经验。
- 比如,你想面银行或互联网金融的风控岗,仔细看看第10、12题。
- 如果你想面试携程或飞猪,好好看看题目13。
- 如果你想从事电商的数据分析,题目5的漏斗分析简直就是必修课。
- 如果你想进滴滴或高德从事地图业务,认真准备一下题目14。
把对口的“借来”的项目经历写入简历,能帮助你的简历在一大堆没有实战经验的竞争者中脱颖而出;到了面试环节,这份“借来”的项目经历也帮你提升了对面试岗位的业务、数据特点的理解,从而给面试官留下深刻的印象,觉得招来的不是小白,而是“来之能战”。
我把这本书、书中题目所使用的数据、我对各题目的解答,打包放到百度网盘上。想获取这份资源的同学,关注我的公众号“推荐道”,回复takehome,限时一个月,免费领取。
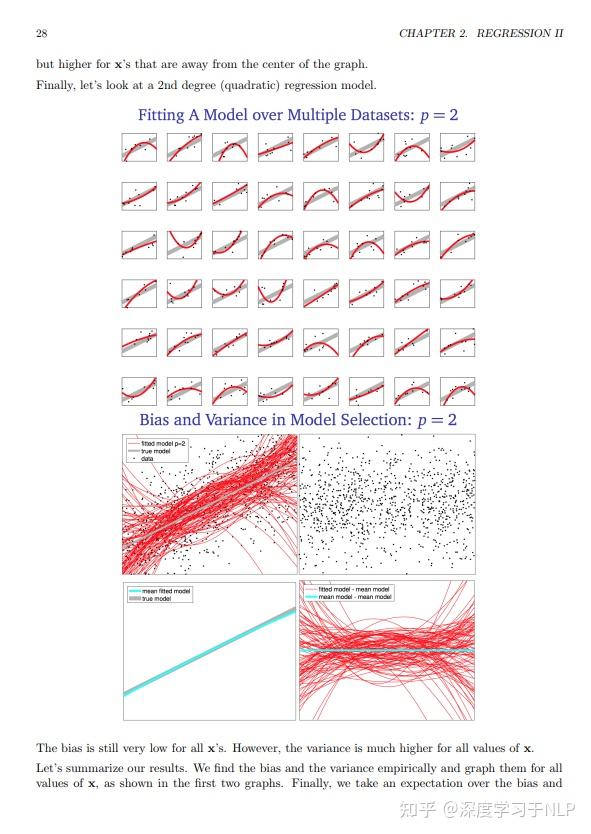
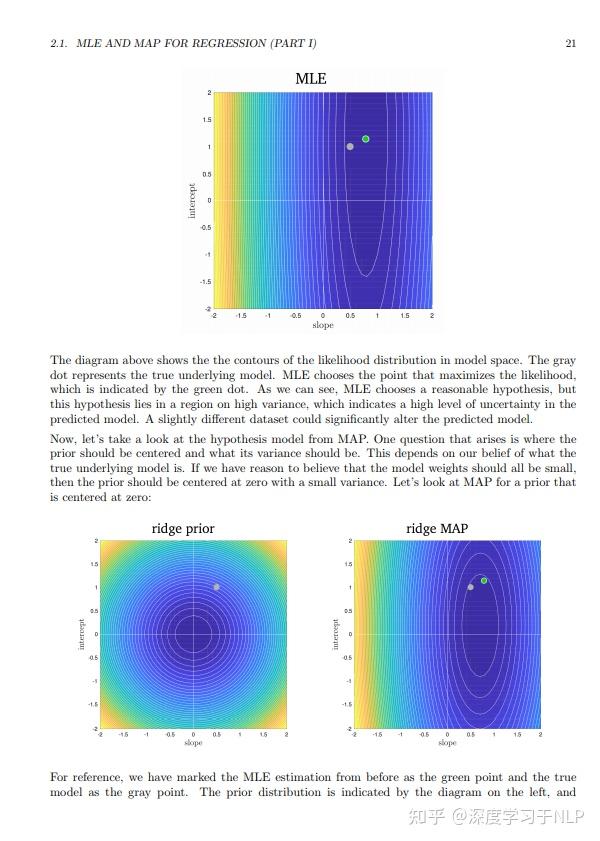
成功的TakeHome Challenge长什么样?
一份帮你求职成功的takehome chanllenge长什么样?面试官希望从中发现候选人的哪些素质?
代码风格
好的代码风格非常重要,在我看来,比多刷几道leetcode还重要,毕竟未来在实际工作中遇到leetcode hard-level的机率是不高的。而目前最现实的需求时,你提交的code是要被面试官review的。如果你写的程序他都看不懂,你的面试结果也就可想而知了。
其实保持一个好的代码风格并不难,能做到如下几点就算不错了:
- 给你的变量、函数、类起一个见名知意的好名字
- 代码模块化。不要一个功能几百行写到底,而是要拆分成函数或类。
- 恰当的注释,帮你的面试官理解你的代码。
另外,一般我们都是用Juypter Notebook来把代码、报告一起提交。你需要熟练掌握Markdown语法,并把你报告中的重要结论用加粗、高亮、放大字体、不同颜色等方式凸显出来,引起面试官的注意。
操作数据的能力
这必须是每个数据打工的人基础功。多表关联、排序、分组、聚合都是常见考点。
如果你使用Python,面试官希望看到,你是能够熟练使用NumPy/Pandas的,包括能提升效率的一些高级技巧。比如你能熟练调用Panads API完成批量操作,而不是自己写了一个for循环。
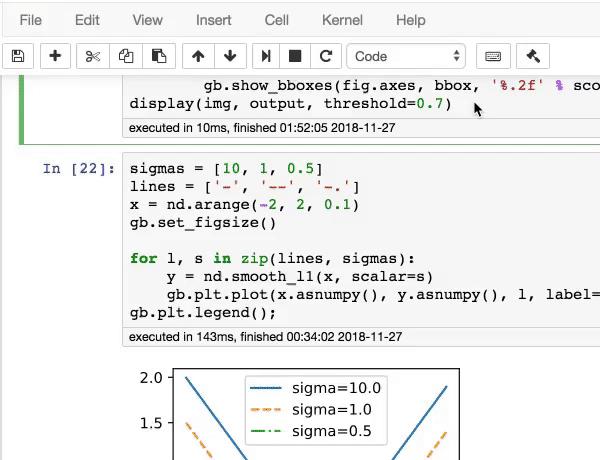
另外,面试官也希望你能够熟练调用matplotlib/seaborn/plotly等库将复杂的数据可视化。正所谓“一图胜千言”,清晰的图表、曲线反映了候选人的表达能力,特别是在面对非技术背景的合作伙伴的时候。
可惜,takehome chanllenge的数据量都比较小,无法反映候选人面对大数据的处理能力。但是也不排除假想一个Hive场景,让候选人写一个比较复杂的SQL出来。
特征预处理的基本功
我在之前的文章中曾经多次强调特征工程的重要性,正所谓Garbage in, Garbage out。所以特征处理能力,也是takehome chanllenge的关键考点。
第一条就是,不要一上来就把数据往模型里扔,那将是一个大大的减分项。正确的姿势是先做一些explorary data analysis,检查是否存在脏数据。现实场景中的数据没那么干净,你会见到各种奇形怪状的脏数据。对脏数据的警惕程度,能够反映出候选人的专业性。
第二,面试官希望能够看到你在构建特征时的创意。能够提取出好的特征,反映出候选人对这个业务的深入理解。
第三,就是考察候选人的特征处理技巧了。
- 对数值特征:离群点、缺失值、标准化、数据平滑、......
- 对类别特征:如何编码、过滤停用词、......。一般takehome challenge数据不多,用不上hashtrick。但是如果你提到了,比如“如果id类特征太多,可以考虑使用hashtrick”,反映出你对推广搜不陌生,面试官倒是应该高看你一眼。
建模基本功
考察候选人对常用的模型框架,比如xgboost/lightgbm/tensorflow/pytorch的熟练掌握程度。
虽然说,一般takehome challenge给候选人答题的时间是以天计,但是如果你真的花了3天时间,给几万条数据建个模型,说实在的,基本上这面试也就到此为止了,后面没啥机会了。我当初做Airbnb的takehome challenge,从拿到考题到交卷,也就半天的时间。
在有限的时间内完成建模,就要求候选人必须有一件称手的兵器(xgboost/lightgbm/tensorflow/pytorch,sklearn有点小儿科了),并且“招之即来,来之能战”。拿到考题,才想起google某个api的具体用法,就有点拉胯了。
评估模型的基本功
不能正确的评估模型,也就无法对模型做出改进。
划分train/validation/test三个数据集,是最基本的常识。如果你把全部数据都投入训练,并基于训练指标形成结论,那就趁早洗洗睡吧。
遇到label不均衡的数据集是常态,
- 用AUC评价也算是常识。如果新手候选人提到GAUC,我要是面试官,就再高看他一眼。
- 模型一般只能给出概率,而实际业务需要一个确定的结论,做出决策所依赖的threshold到底应该划在哪里?
- 现实场景中几乎看不到正负样本5/5开的数据集,基于threshold=0.5来做出结论的,也趁早洗洗睡吧。
- 采用不同的threshold,precision是多少?recall是多少?结合具体业务,我到底是应该“错杀三千”,还是考虑“放走一个”?
如果候选人除了给出在整个test集上的指标,还知道划分子集并给出每个子集上的指标(比如:新老用户上的不同指标、不同分类的商品上的指标),听我的,千万不要放过他。(说真的,能想到这一层的候选人,也用不着从我这里“借”项目经验。)
以上说的还都是离线评测,有的题目要求候选人设计线上AB实验方案。如何分桶(按人分桶,还是按流量分桶)、如何设计指标反映对业务的提升、......,都是常规考点。
分析并改进的能力
如前所述,一般takehome challenge给你1~3天的时间,但是你千万不要卡着3天的上限交卷。毕竟我们不是在打kaggle比赛,没必要为了auc千分位上的提升,又是建多模型boosting & stacking,又是grid search把整个超参空间搜个遍。
面试官从不期待候选人给出一个完美模型,因为这个东西本来就不存在。takehome challenge有两个考察目的:
- 首先,候选人能够在有限的时间里面(一般就半天),给出一个还不错的模型。这考察的是候选人对知识、技能、工具的熟练掌握程度。
- 然后,候选人能够分析初版模型的问题,并给出改进意见。因为完美模型虽然不存在,但是老板们鞭策我们追求完美的声音却始终萦绕在每个打工人的耳边。
面试官希望看到:
- 第一步分析出,初版模型到底是underfitting还是overfitting?(当然,如果候选人对overfitting有非常规的看法的话,嗯,肯定会有下次面试,咱俩好好唠唠。)然后,根据underfitting还是overfitting,针对性地提出具体改进方案。
- 比如:哪个超参数还需要继续调整?
- 比如:哪些特征还需要加强?怎么加强?
- 比如:是否需要收集更多的数据?怎么收集?
要达到以上目的,候选人需要有能力打开模型的黑盒,比如掌握基本的特征重要性分析方法。
产品意识
毕竟我们不是在实验室从事理论研究,我们希望看到候选人能够从数据中提炼出想法,改善产品,带来切实的收益。
- 比如:发现某个用户分群特征(e.g., 性别、年龄)的重要性非常强,模型在不同人群上的表现差异很大。候选人提出使用运营等手段,加强劣势人群对产品的认知。
- 比如:模型认为某个特征的重要性非常低,但是这与常理不符。这时,候选人提出是不是产品设计有问题,导致这个重要特征发挥不了作用。
另外,如果候选人能够将自己使用app的亲身体验与数据中表现的模式结合起来就更好了,说明招来的是一个热爱这款产品的“同道中人”。
举例说明
刚才讲了这么多,也算是我当过候选人,也当过面试官的切身感受。还是那句话,即使不采用takehome challenge的考察形式,以上内容也算是数据从业者的基本素质,是面试中的常见考点,也希望候选人能够主动展示。
我拿我求解“07.Marketing Email Campaign”这道题的过程,演示一下如何在takehome challenge中向面试官展示自己的能力。
先提前声明:我的solution也是好多年前做的了。当时我也是新手,对第二章强调的几个考点感受也不深,所以我的solution也并非面面俱到,就算是给大家“抛砖引玉”了。
先看题目,这道题的场景是一个邮件营销的场景,业务方关心的是有多少人打开了邮件,又有多少人点击了其中的广告链接。
- What percentage of users opened the email and what percentage clicked on the link within the email? (考察数据处理能力)
- The VP of marketing thinks that it is stupid to send emails to a random subset and in a random way. Based on all the information you have about the emails that were sent, can you build a model to optimize in future email campaigns to maximize the probability of users clicking on the link inside the email? (建模能力)
- By how much do you think your model would improve click through rate ( defined as # of users who click on the link / total users who received the email). How would you test that? (评估模型的能力)
- Did you find any interesting pattern on how the email campaign performed for different segments of users? Explain (分析改进能力,还有产品意识)
我的答案在我的github上,获取方式见本文最后。
帮助面试官理解
我用jupyter notebook撰写代码与报告。报告一上来,我就将我的解题过程列出来,帮助面试官理解我的解题思路。

分析结果多用图表展示。重要结论字体加粗、放大、用醒目颜色,引起面试官的注意。
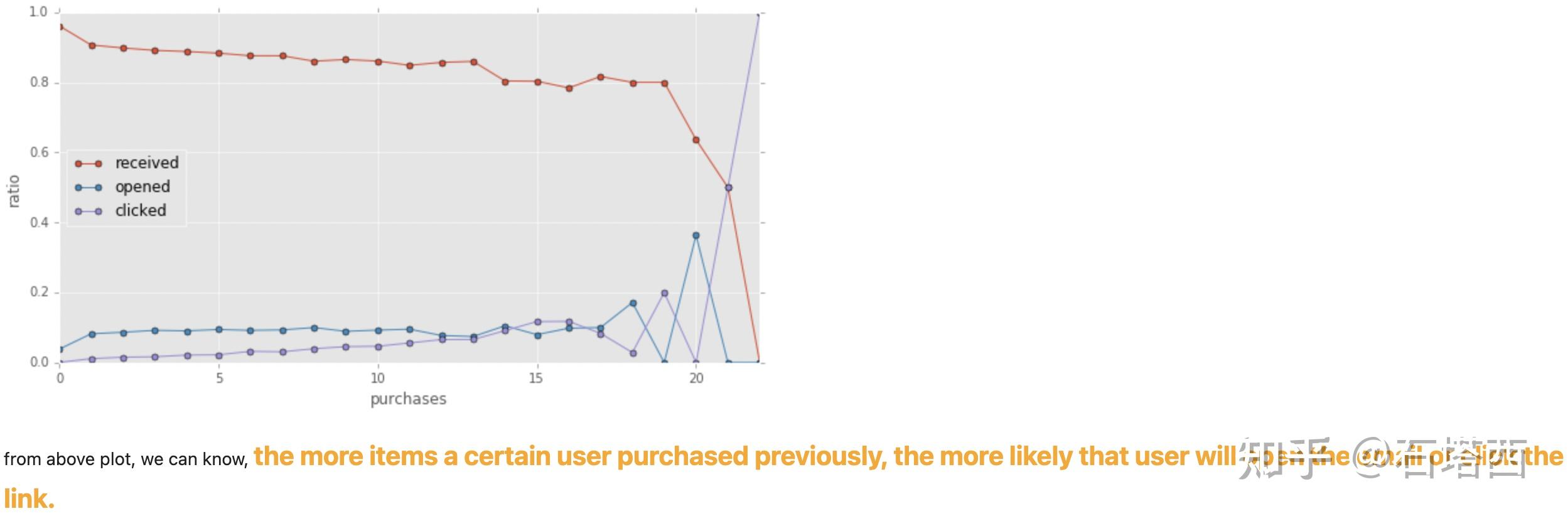
总之一句话,帮助面试官,就是帮助你自己。
改进模型
要让面试官知道,时间所限,这一版模型还凑合,但是我知道如何改进能让它更好。
产品意识
从数据中提取出能够改善产品的观点。

为了能够得出这些结论,我演示了如何从XGBoost获取特征重要性。
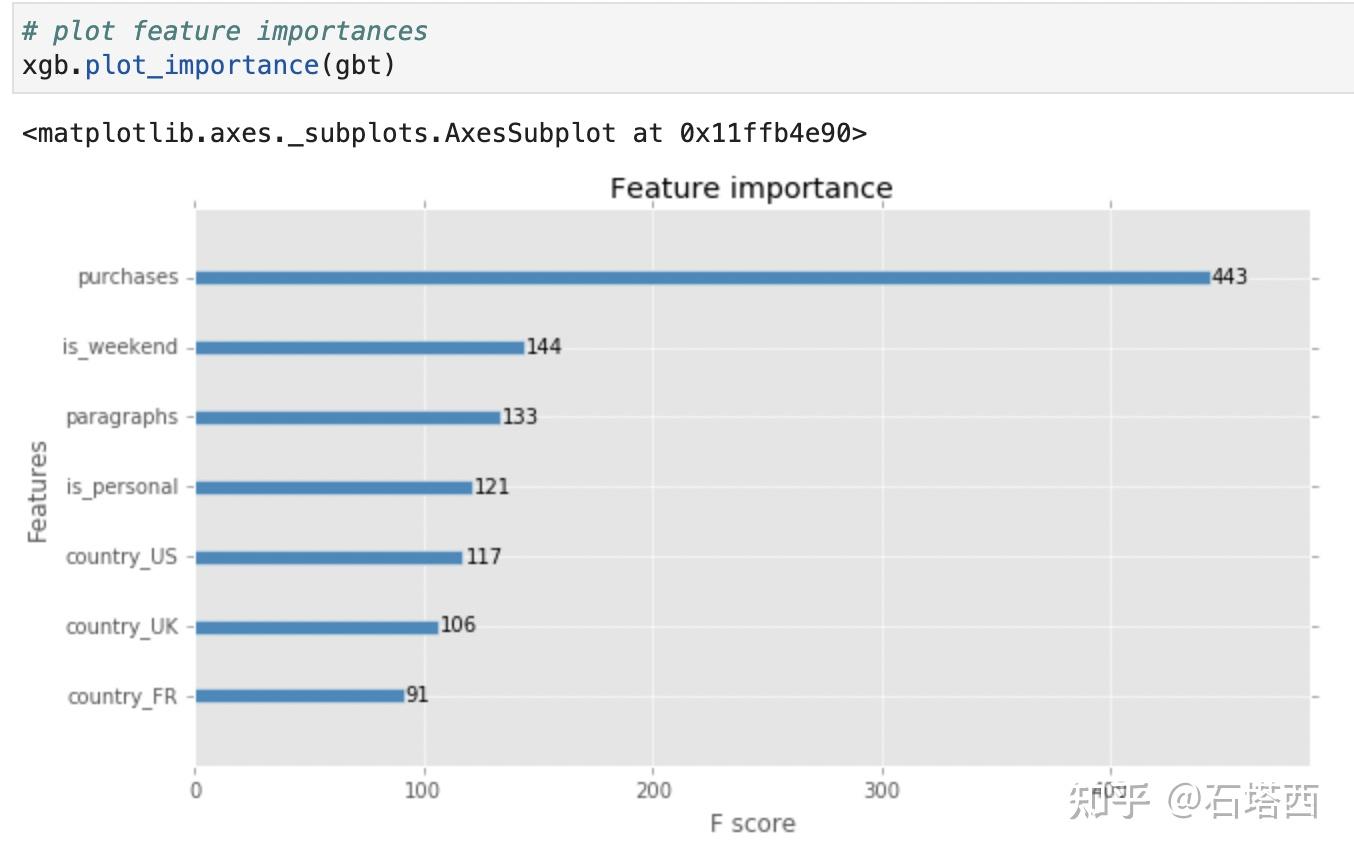
模型评估
给业务方讲AUC来评价你的模型是没有意义的,你必须将它翻译成“人话”。
首先,模型给出的是概率,但是业务方需要的是一个确切、可行动的结论。这里,我用TPR(true postive rate)和FPR(false positive rate)来量化我的不同决策的影响(点开概率超过多少,才发营销邮件)。


基于我的决策,我拿业务方关心的指标来证明模型的有效性,即节省了流量,有些潜在用户可能收不到邮件,但是广告打开率翻倍了,总之广告的效率更高了。

总结
本文介绍了takehome challenge这种硅谷常见的面试数据科学从业者的形式。借着takehome challenge这个话题,根据我做过候选人也当过面试官的亲身感受,我列举了数据科学面试中的常见考点,算是回答了“算法学到什么程度才能找到一份工作”、“怎么才能转行算法工程师”这类新手比较关心的问题。
准备takehome challenge对于已经掌握了数据科学的基本知识,但是苦于缺乏项目实战经验的新手是非常有帮助的。根据你要面试的行业、岗位,新手不妨从我提供的资源中“借”一个项目经验。把“借来”的、对口的项目经历写入简历,能帮助你的简历在一大堆没有实战经验的竞争者中脱颖而出;到了面试环节,这份“借来”的项目经历也帮你提升了对面试岗位的业务、数据特点的理解,从而给面试官留下“来之能战”的深刻印象。
还是那句话,虽然takehome challenge这种考察形式在国内大厂并不多见,但是考点总是相通的。熟练掌握后,候选人可以在面试中主动向面试官展现自己的相关能力。
本文也提供了准备takehome challenge的相关资源。花了我几十美刀的电子书、数据集,还有我对20道题目的答案,都放在百度网盘上,作为我回馈粉丝的福利。关注我的公众号“推荐道”,回复takehome,限时一个月,免费领取。
- END - |















 (1)每一小节都是可以运行的 Jupyter 记事本!
(1)每一小节都是可以运行的 Jupyter 记事本!