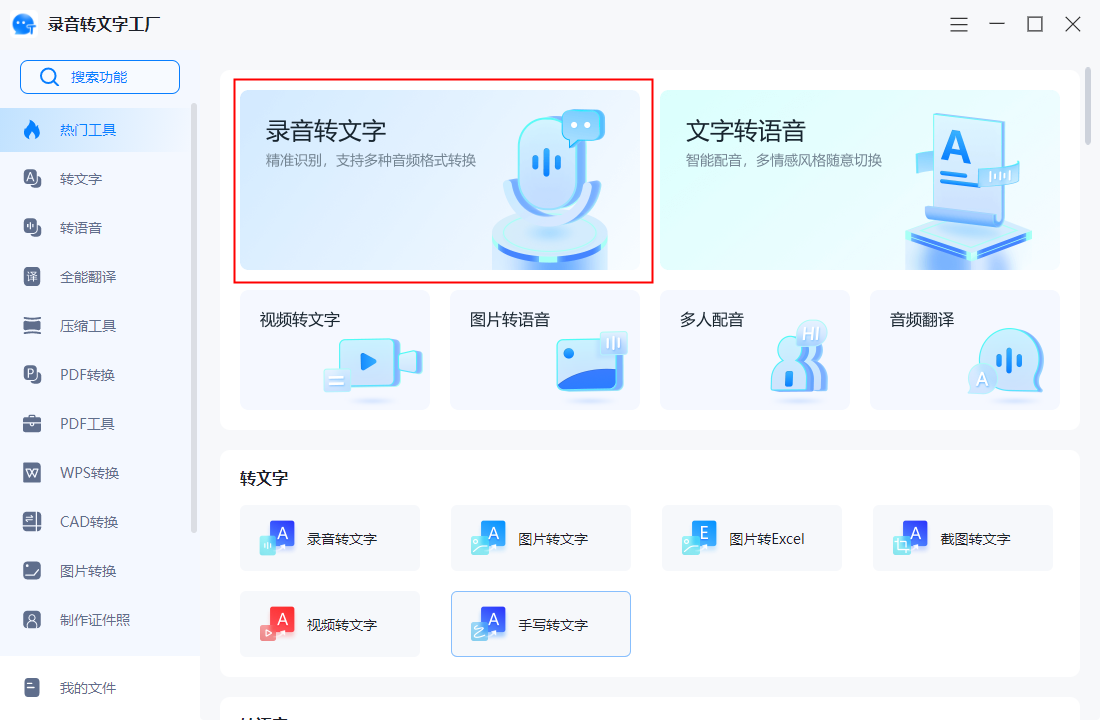
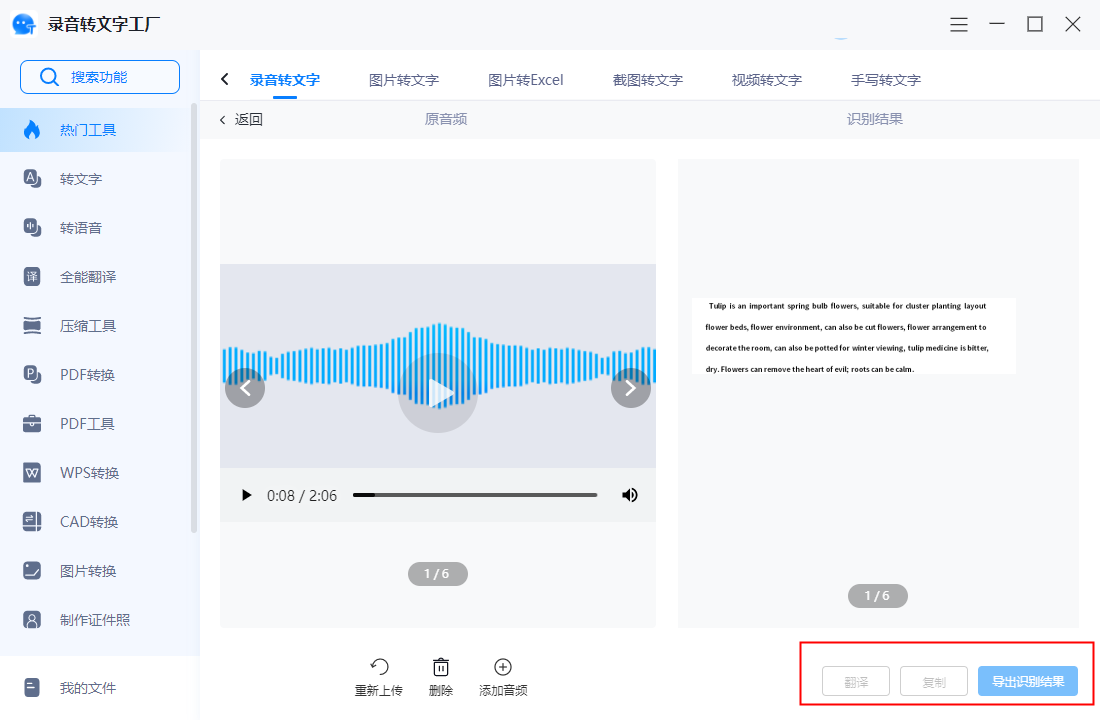
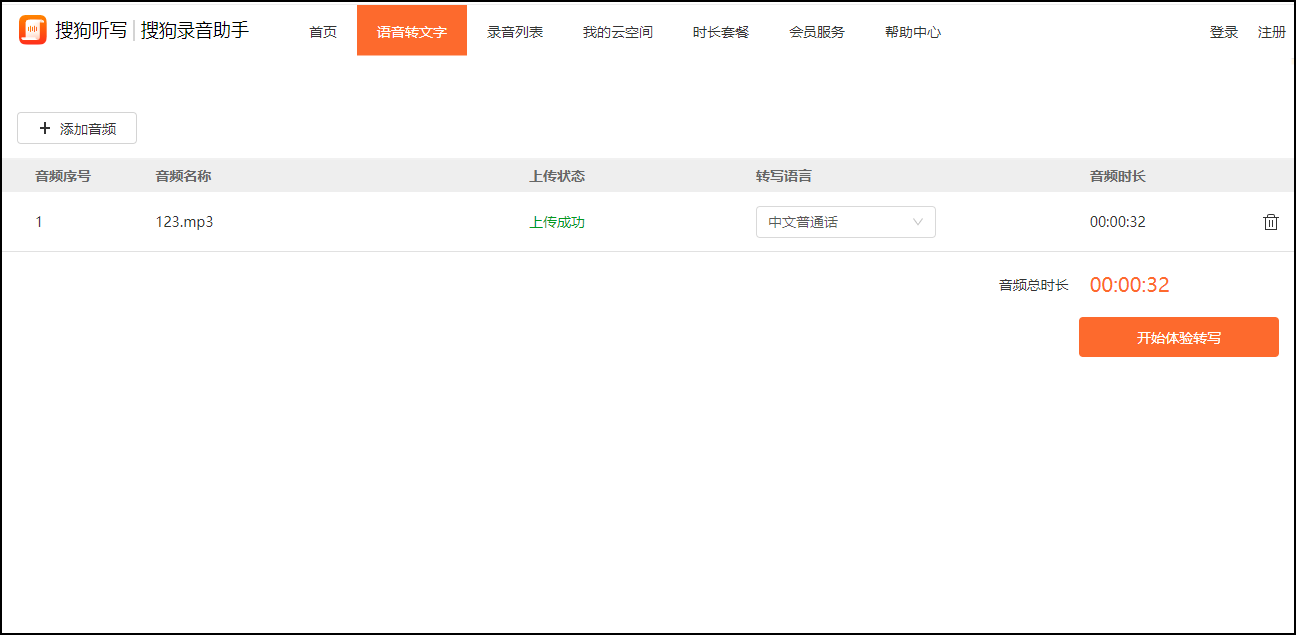
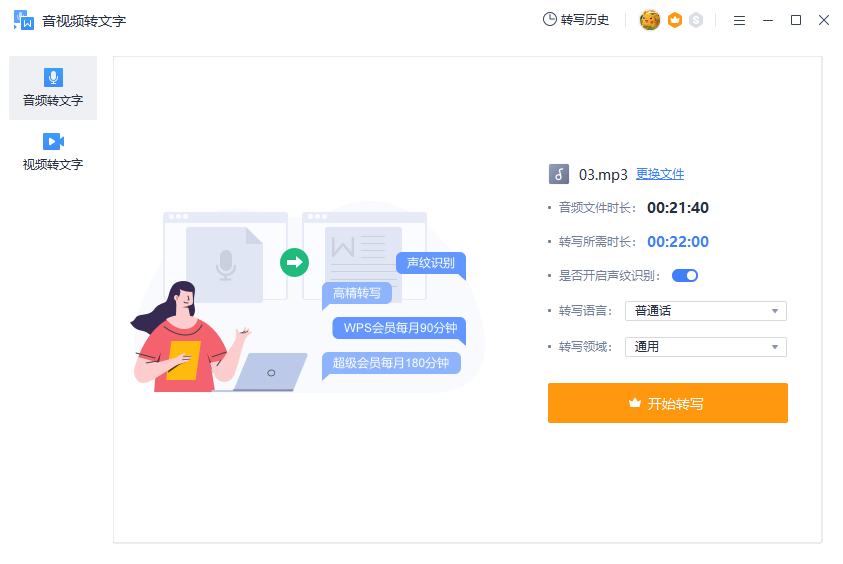
不请自来,最近刚好因为筹备JDD语音识别大赛在做这方面的研究。
语音识别,顾名思义,是利用机器将语音信号转换成文本信息。比如被我们玩坏的Siri,京东的叮咚音箱,小米的小爱同学,亚马逊的Echo等。

想要从零开始搭建一个语音识别系统,首先遇到的一个问题就是使用什么数据用来上手。一个有效的语音识别模型,通常需要几百到几千小时包含文本标注的音频文件作为训练数据。
目前在学术论文中比较常见的语音识别数据集,比如Switchboard,TIMIT,WSJ这些,都并不免费且价格高昂。
公开数据集中最常用的英文语料是LibriSpeech,其中包含了1000小时的16kHz有声书录音,并且经过切割和整理成每条10秒左右的、经过文本标注的音频文件,非常适合入门使用。
中文语料方面,目前公开的大规模语音识别数据集比较少见。清华大学开源过30小时的连续普通话语音数据库THCHS-30,由大学生参与录音获得。
以上介绍的两个公开语音数据集,都可在http://www.openslr.org免费下载。
另外,参加一些开放语音数据的算法比赛,也是中文语音识别项目入门的好途径。比如我们今年主办的京东金融对话语音识别大赛,首次开放了上千小时的中文客服对话语音数据,并提供强大的GPU资源保障运算能力。比赛面向广大的语音技术爱好者,高校学生,企业开发者,希望通过开放客服对话语音标注数据(经严格脱敏),专注于寻找最新、最强的语音识别算法,促进语音技术的普及和发展,同时加强语音识别技术爱好者之间的交流与分享。
JDD空间站和语音识别大赛具体信息可查看文章:
JDD空间站首场邀请赛开赛,开放数千小时真实客服对话语音数据

最简单的语音识别例如yes/no,整个识别的词典范围只有yes和no两个单词。

如果词典范围在扩大一些,例如数字识别,识别连续的阿拉伯数字。这两种语音识别的任务都是相对简单的。
而在对于电话录音转译则要复杂得多,中文的语音识别词典范围可以达到6000多个汉字,而英语单词则有64000个单词之多。
另外语音识别还可以从场景角度去分类,分为孤立词识别(Isolated Word),连续语音识别(continuous speech),而连续语音识别又可以分为人机录音和对话语音识别,人机对话是人对机器发声,例如语音输入法,而对话语音识别,例如会议,客服电话等
而本次JDD举行的对话语音识别大赛,从热身的数字语音识别到客服语音识别,都提供了一个入门语音识别的绝好机会。
报名参赛可戳:https://jdder.jd.com/index/jddDetail
虽然数字语音识别能给我们提供一个入门,但是通常我们所指的语音识别都是指大规模词汇连续语音识别(Large-Vocabulary Continuous Speech Recognition--LVCSR),英语词汇在20000-60000的范围,而中文汉字的范围是2500-6000的范围。

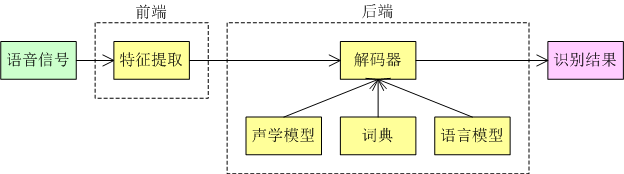
传统语音识别的框架如下:
- 语音信号特征提取:常见的语音信号特征有MFCC,Filterbank,Spectrogram等
- 声学模型:传统的语音识别基于HMM、GMM进行声学模型建模
- 语言模型:一般采用N-gram的语言模型,目前基于RNN的语言模型也逐步发展起来
- 解码:传统的解码一般是基于WFST,在HMM、字典和语言模型构成的动态网络中搜寻最优的输出字符序列
而端对端的语音识别框架,很适合初学者入门,大大降低了语音识别技术的门槛。端到端的语音识别系统一般采用CTC或者Attention两种机制。随着神经网络技术以及硬件计算能力的不断发展,采用上万小时语料训练得到的端到端语音识别结果较传统方法取得了明显的进步,其中一个例子为百度的Deepspeech框架。下面为一些经典的端到端语音识别方面的论文。
1. D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” CoRR arXiv:1512.02595, 2015.
2. A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In ICML, pages 369–376. ACM, 2006.
3. W. Chan, N. Jaitly, Q. Le, and O. Vinyals. Listen, attend, and spell. abs/1508.01211, 2015. http://arxiv.org/abs/1508.01211.
语音识别开源项目汇总:
https://github.com/SeanNaren/deepspeech.pytorch基于Pytorch
https://github.com/pannous/tensorflow-speech-recognition 基于Tensorflow
https://github.com/facebookresearch/wav2letter 基于Torch
https://github.com/samsungsds-rnd/deepspeech.mxnet基于Mxnet
https://github.com/baidu-research/ba-dls-deepspeech基于Theano
https://github.com/PaddlePaddle/DeepSpeech 基于PaddlePaddle
https://github.com/mozilla/DeepSpeech基于Tensorflow
https://github.com/kaldi-asr
本文系京东金融技术研发部原创内容。
希望对你有用,不吝关注、点赞和分享,也欢迎联系我们参加语音识别大赛,期待切磋交流~ |