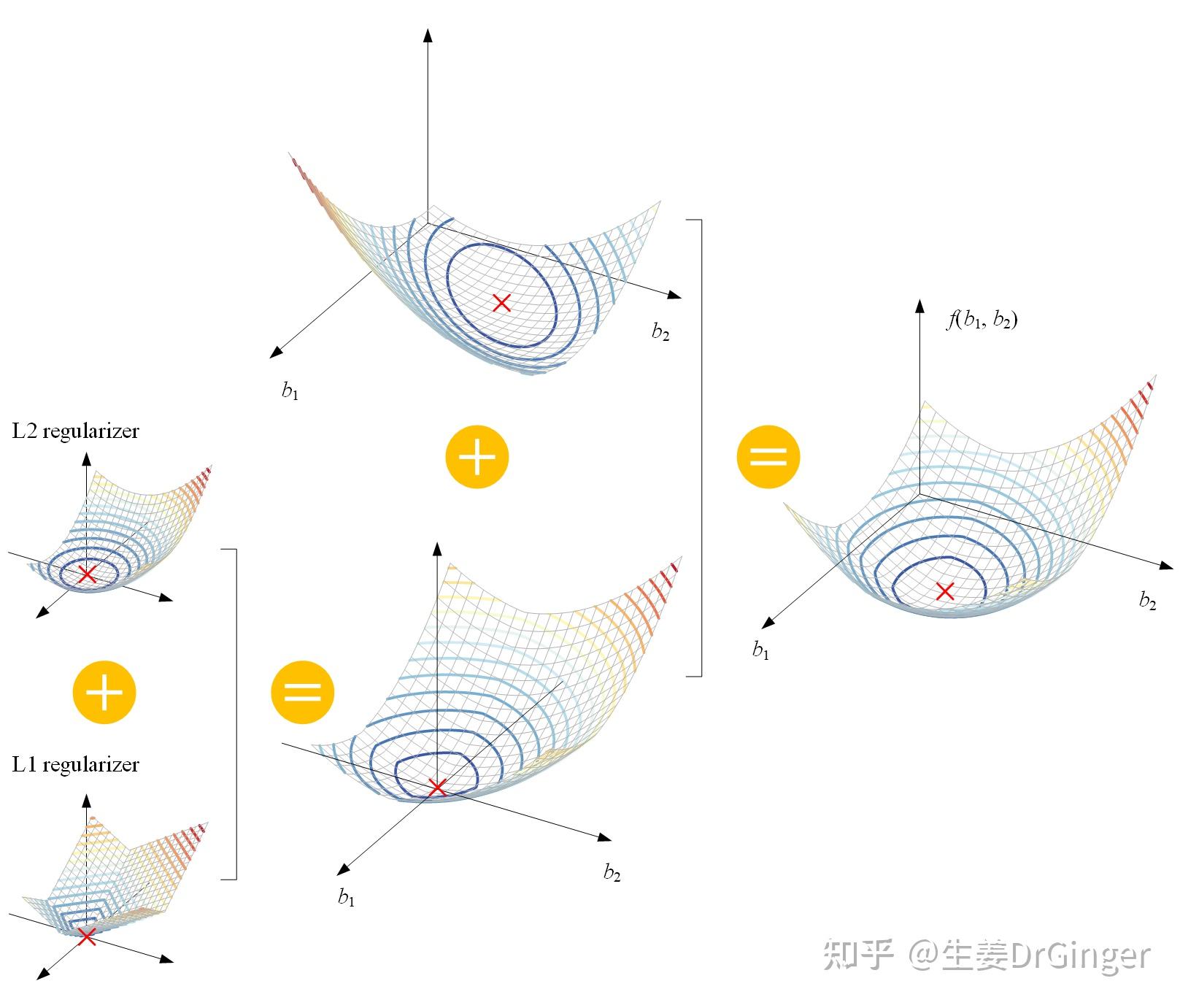
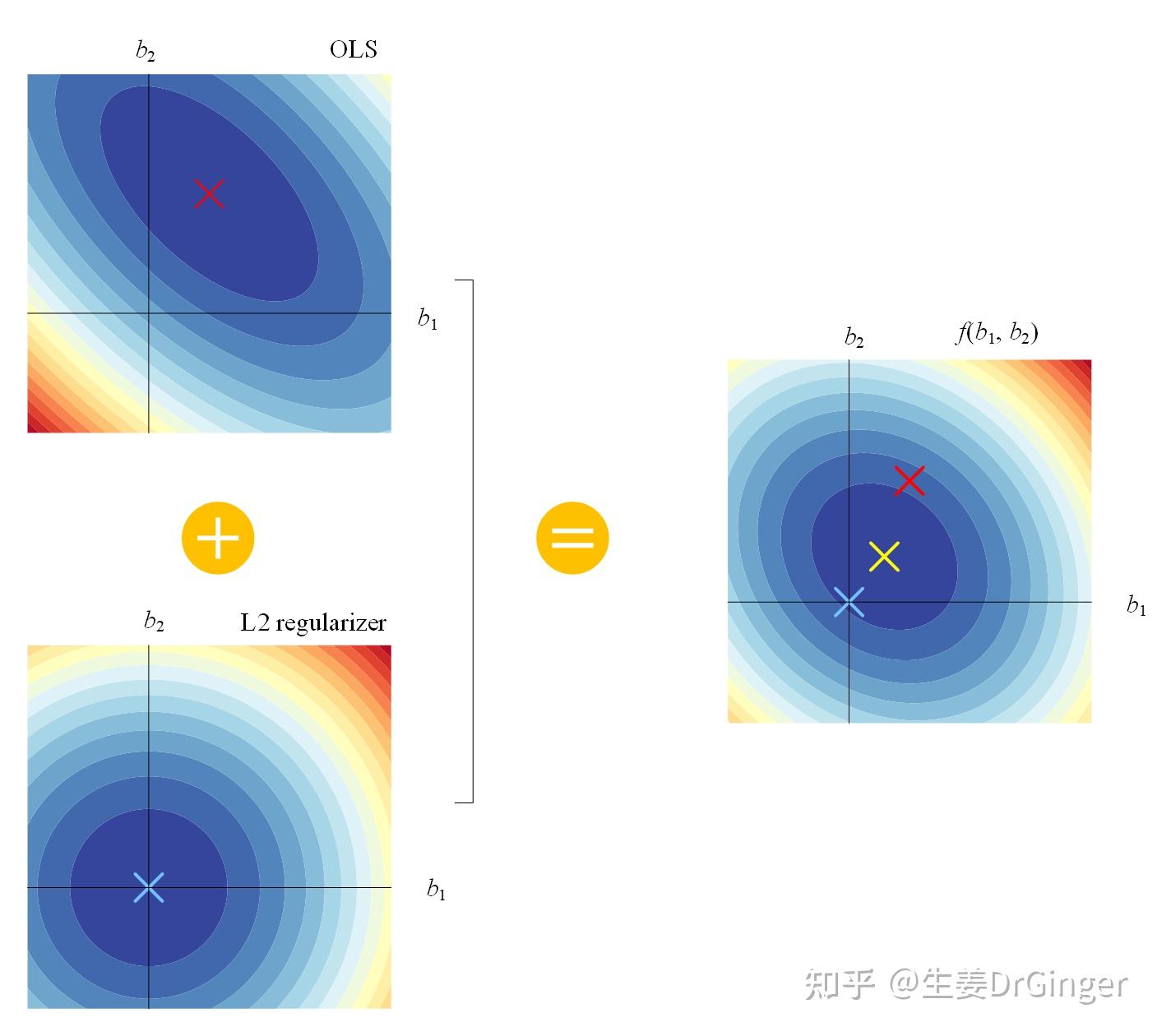
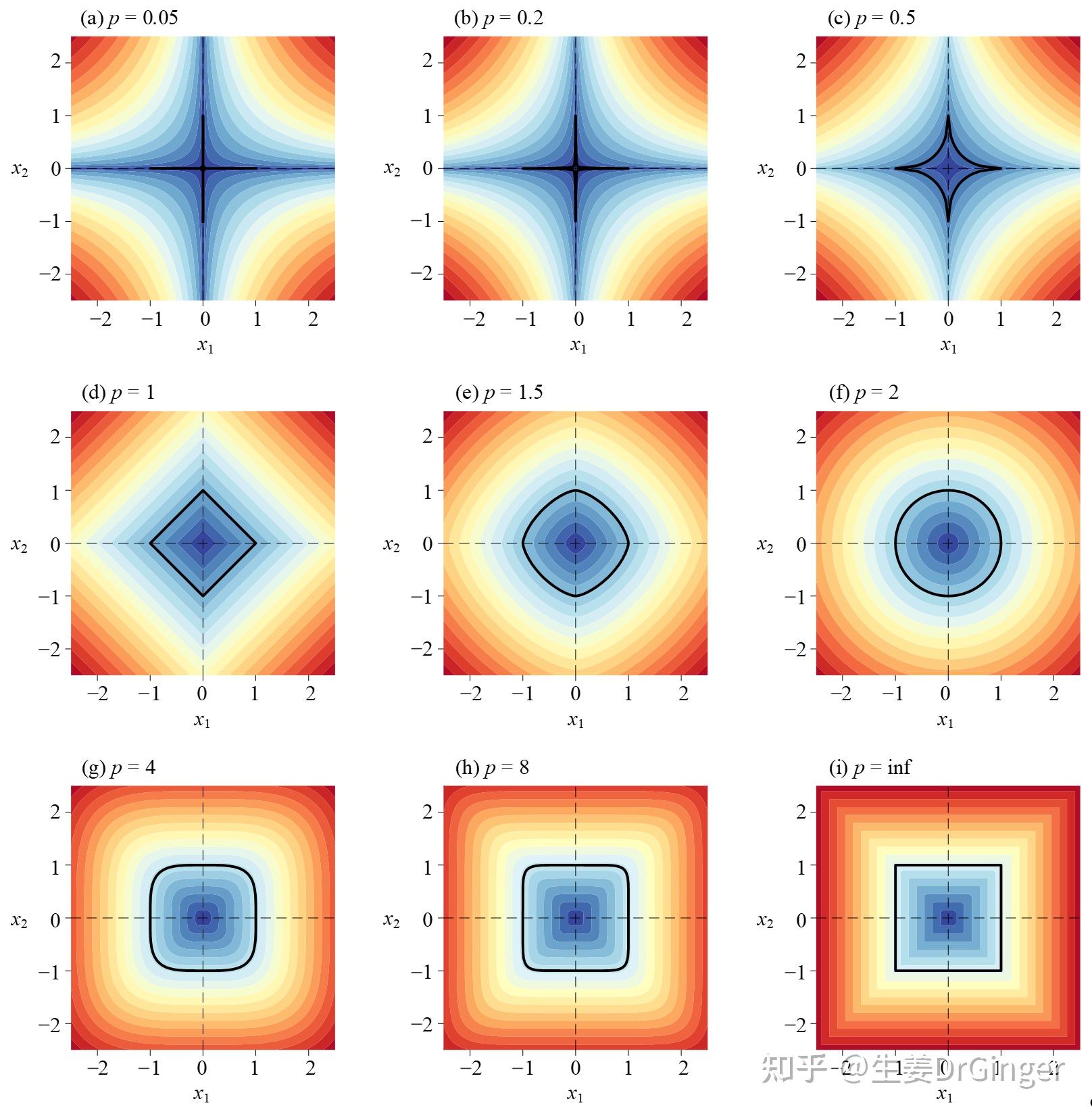
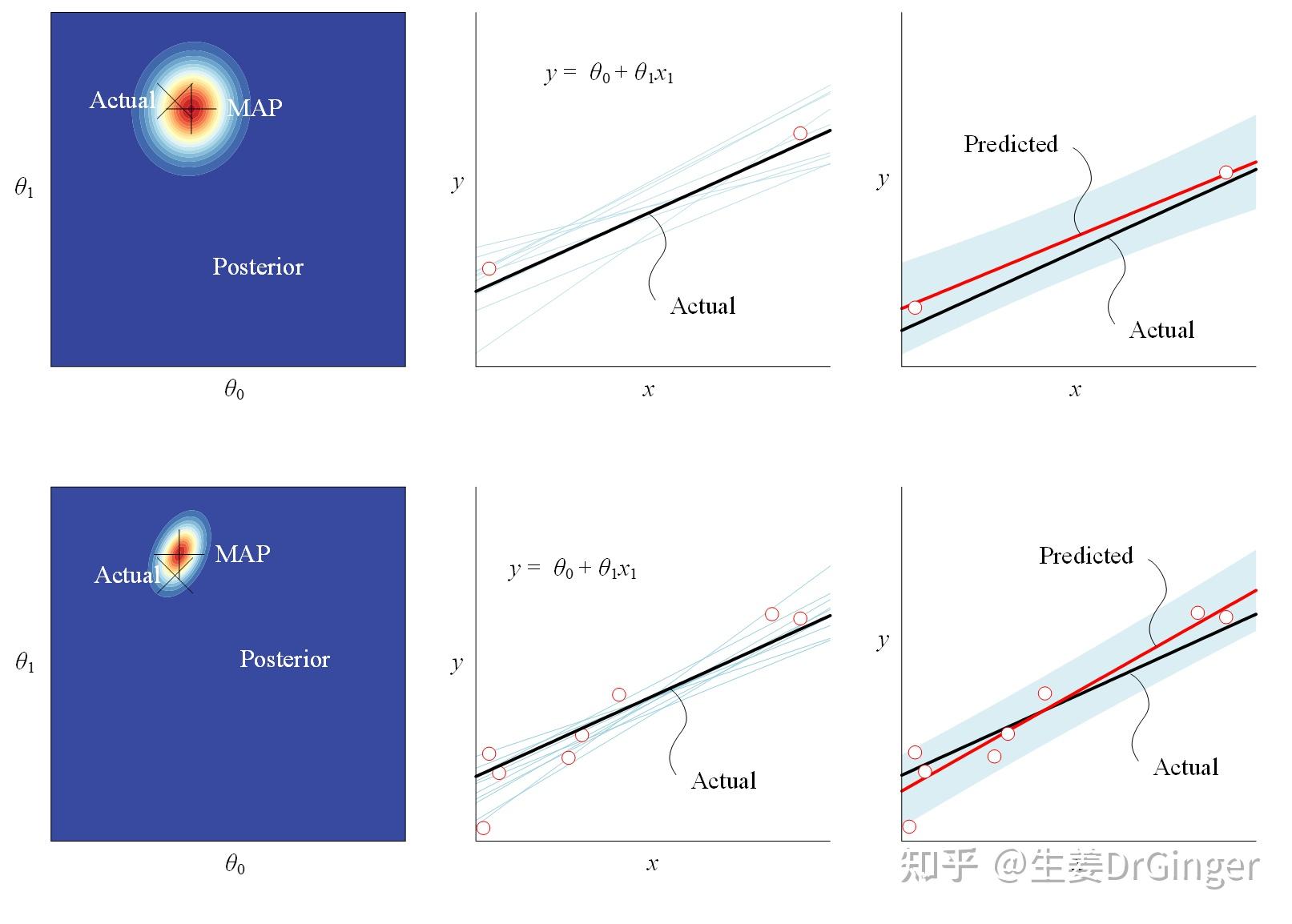
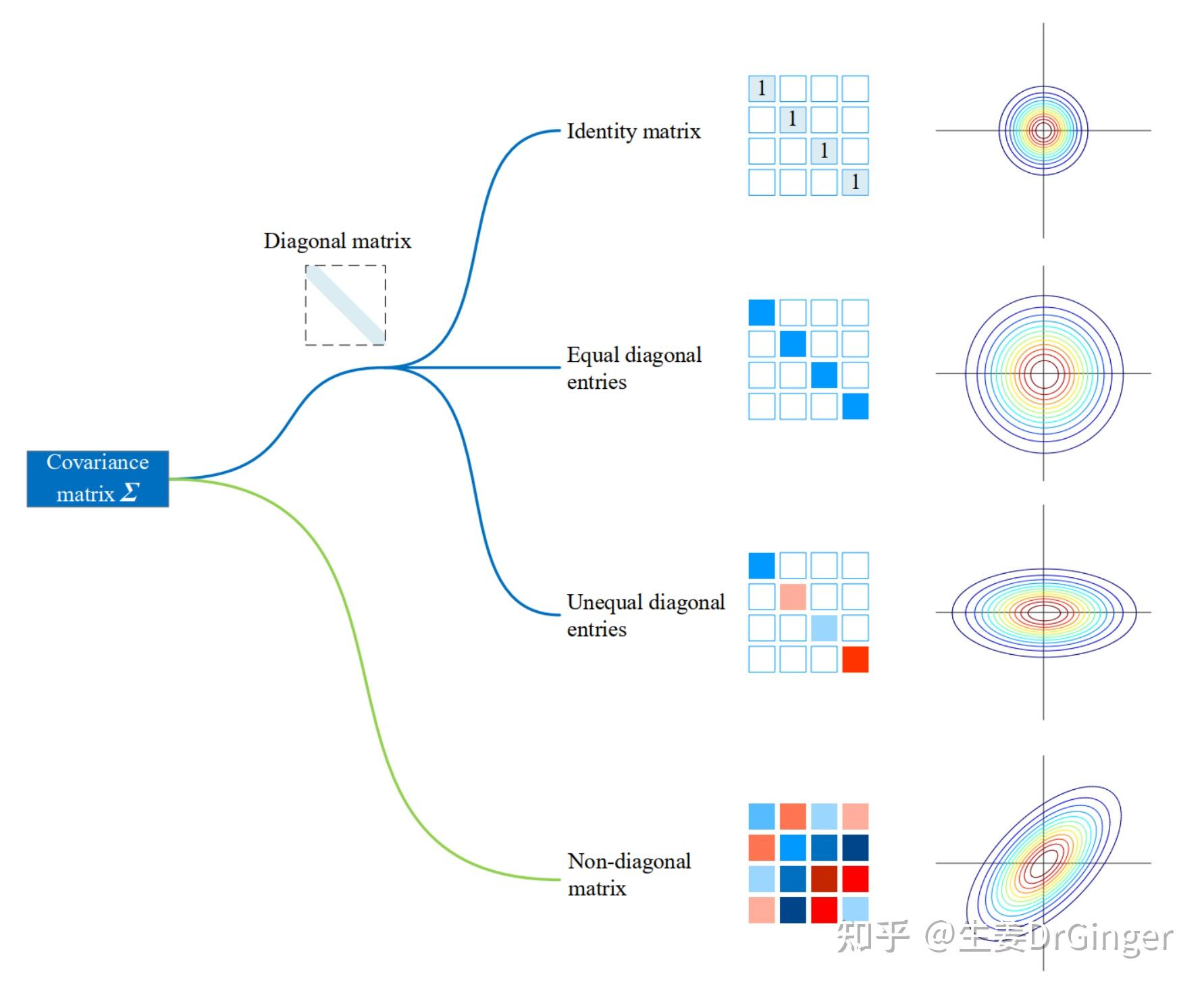
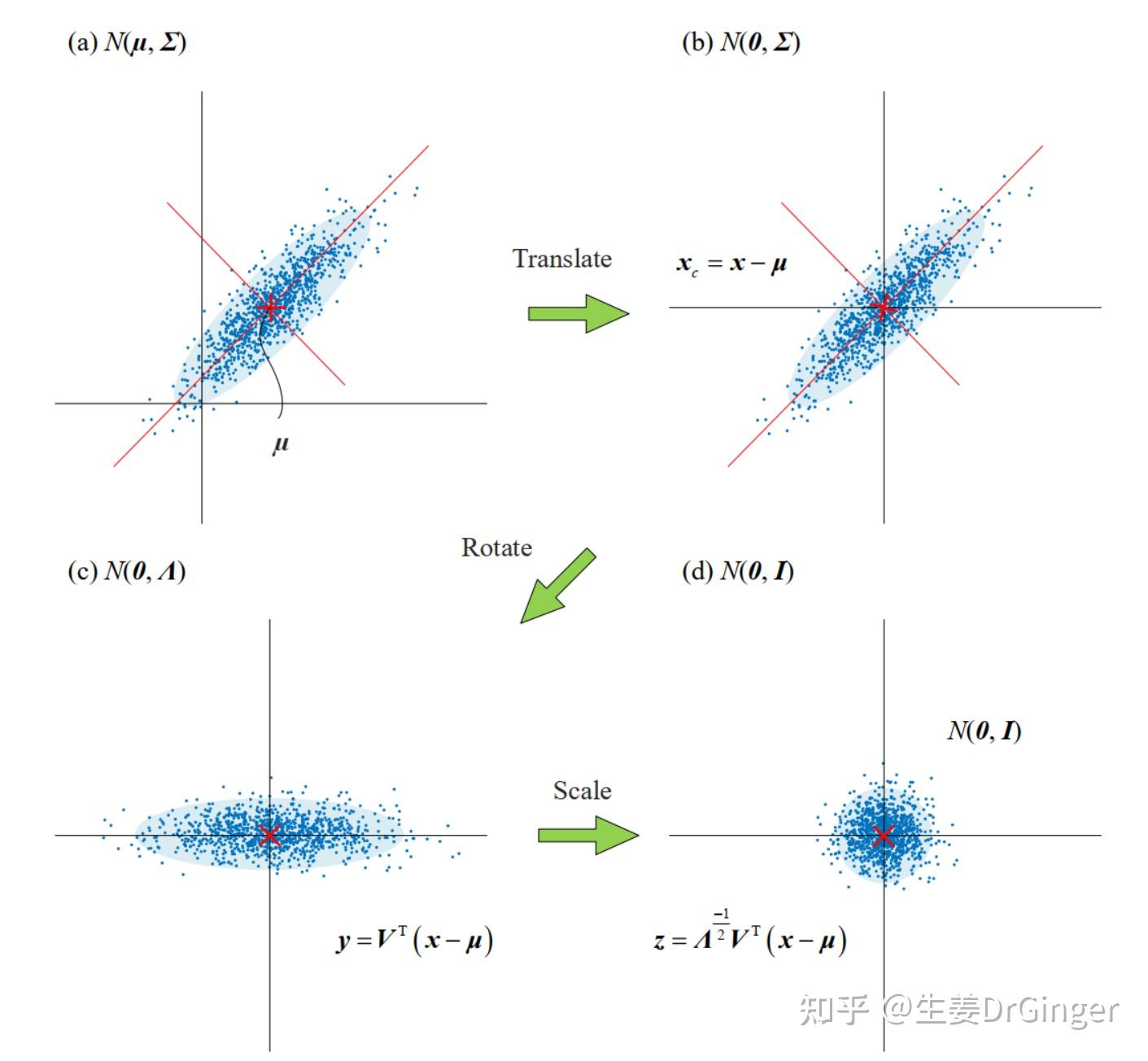
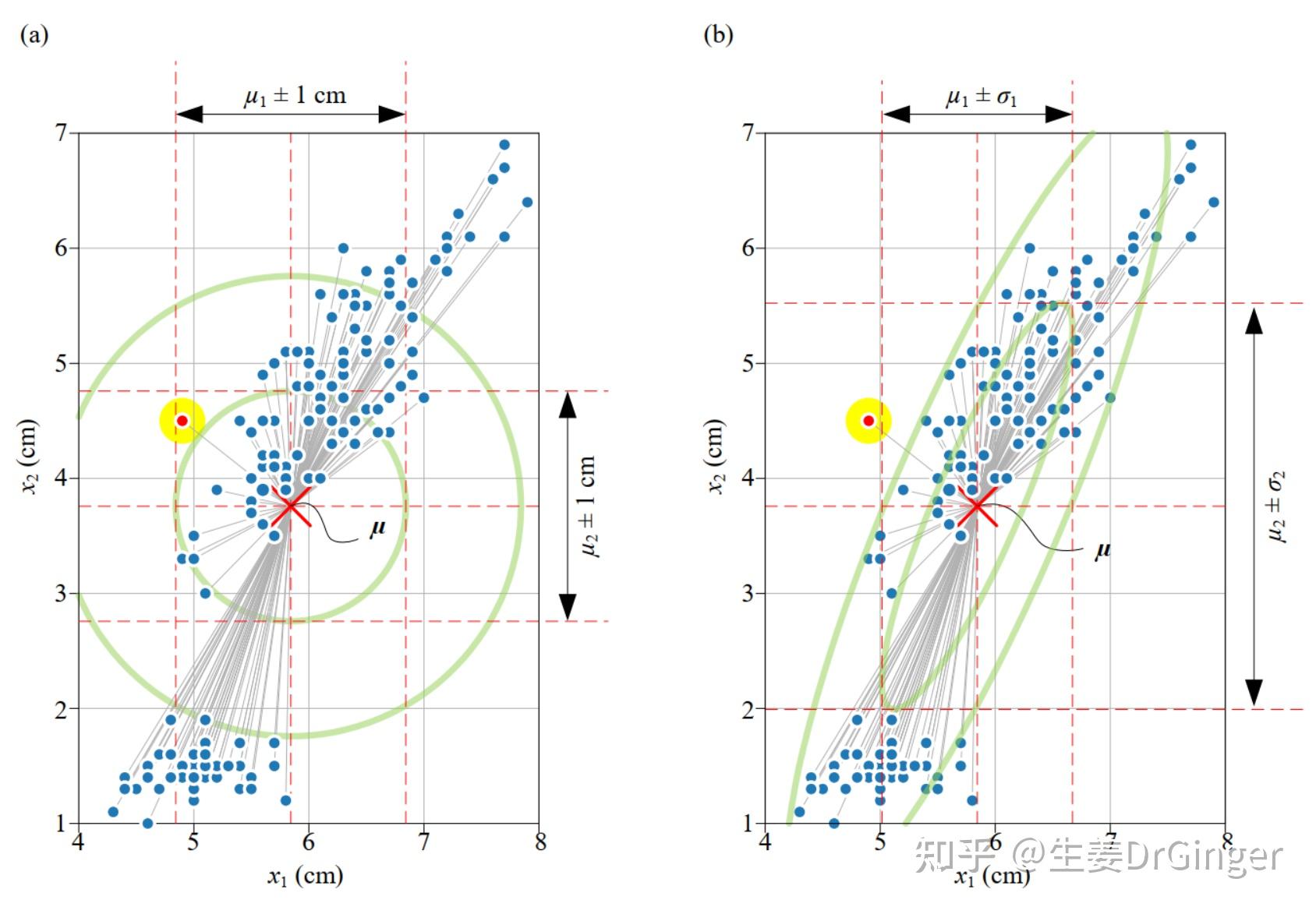
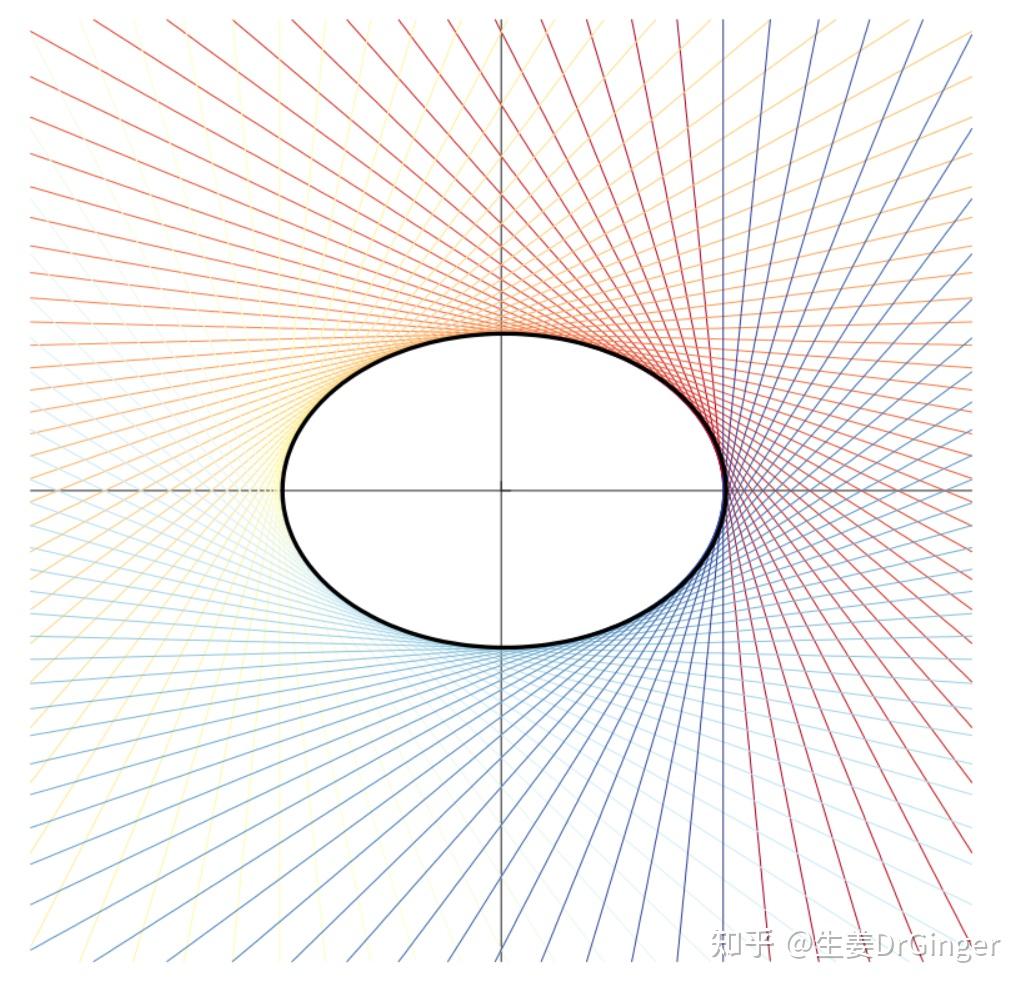
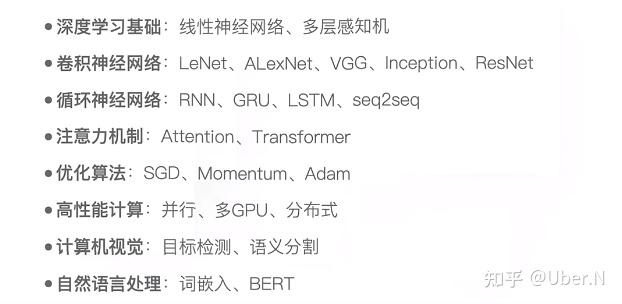
2021.05.10更新:
评论区有挺多人质疑半年能否完成这么多内容,我的观点是半年时间足够完成前两个步骤的学习,完成前两个步骤后就可以去参加互联网公司算法岗位的面试了,对于代码能力不错,Leetcode easy题目熟练的同学,已经有很大可能性拿到一份实习Offer,步骤三在实习过程中持续进行,那么秋招的时候就能拿到正式Offer了。
推荐一下自己在数据科学道路上的学习笔记,终生更新,终生开源,喜欢的同学可以点个star,repo下载到本地,阅读效果更佳
zhangjx831/Data-Science-Notes
原答案:
不请自来答一波,半年前入坑机器学习,如今已经拿到某互联网大厂算法岗实习offer,给大家推荐一下我的学习路线。
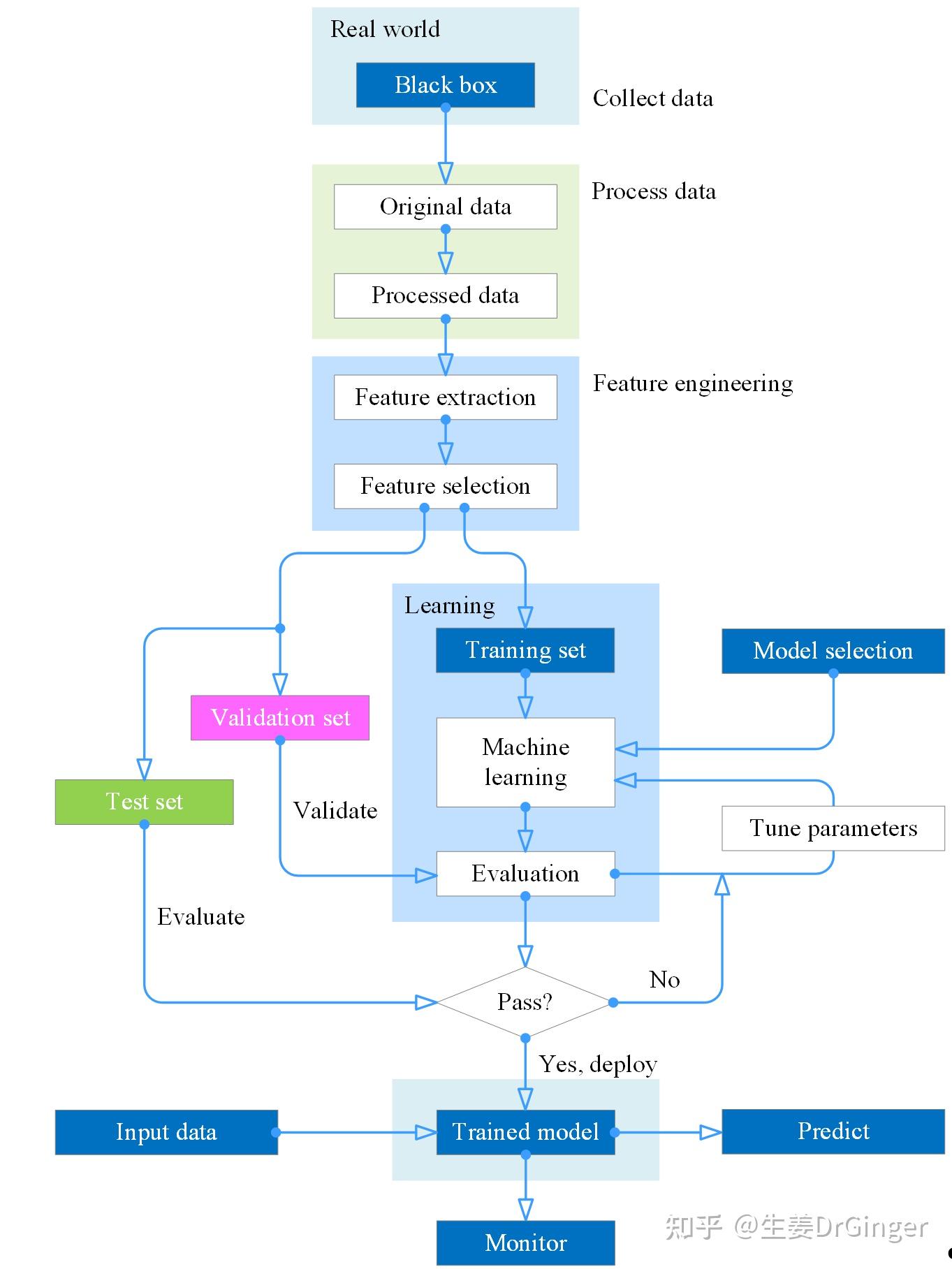
机器学习主要分为传统的统计学习和深度学习两个部分。统计机器学习在上个世纪就一直在用,只不过当初不叫机器学习这个名字,深度学习从2012年起掀起了一波AI热潮。想要学习机器学习,将来找算法岗工作可以分为三步。
步骤一:打好数学和代码基础
相信大部分想学习机器学习的都是一些理工科的同学,包括数学、物理、计算机、自动化等,这些同学本科期间数学和代码功底比较扎实,这个步骤可以选择性略过。对于一些数理基础不是特别扎实的同学,比如生化环材还有一些商科文科的同学,想学习机器学习,还需要先复习(预习)一些数学和代码知识。我就属于后面这一部分同学,下面来讲讲我当时怎么做的。
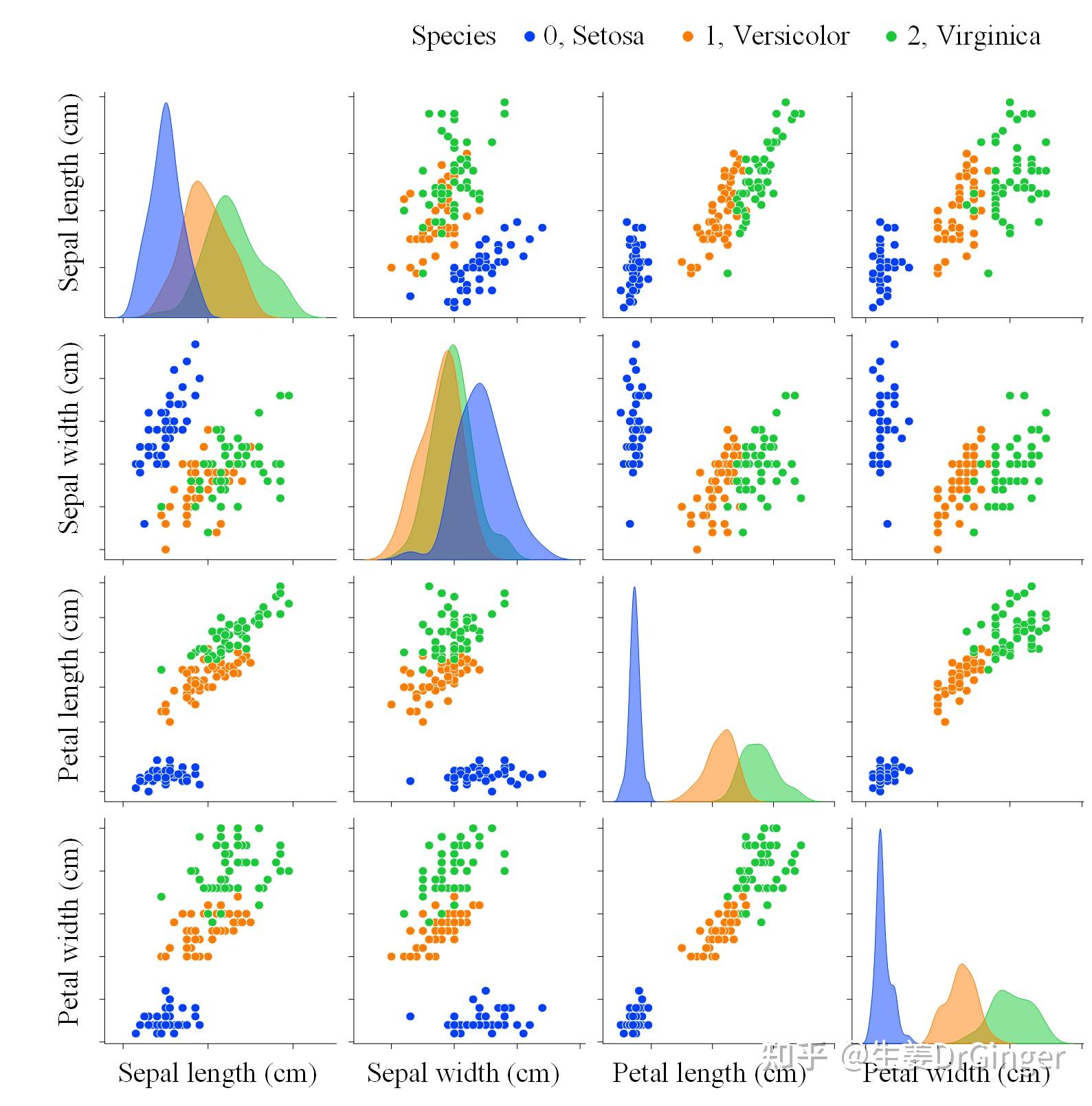
数学基础主要就是微积分、线性代数、概率论与统计这三个部分。对于微积分来说,至少要掌握多元微积分的知识,会求偏导,求积分。线性代数对机器学习比较重要,需要懂一些矩阵运算法则,求矩阵特征值,求方程组,矩阵的逆等等。概率论与统计是重中之重,要了解一些基本分布,条件分布、联合分布等等。数学基础这个部分如果不太懂的话,可以在mooc上搜一些考研数学的复习视频,短平快的复习好这三大部分的知识点。对于线性代数部分的学期,可以参考麻省理工学院MIT的公开课,知乎上已经有人做了课程笔记,可以搜索一下。而概率论统计也可以在coursera上搜索相应课程,推荐一门statistic with python的课程,既复习了统计学基础,又练习了python代码能力。
https://www.coursera.org/specializations/statistics-with-python对于代码基础部分,刚开始做机器学习一般都从比较简单的python入手,很多的软件包都是基于python而写的。对于python的学习,推荐coursera上的另一门网课,python for everybody,讲解深入浅出。除此之外,最好懂一些常用包的使用,numpy,pandas和matplotlib,这三个分别是python中进行科学计算、数据处理和数据可视化的包,我的学习建议是多写代码多练习,找一个数据集,进行数据导入、预处理、探索性分析、可视化,这些操作来一遍,python就学了个大概了。如果还想进一步深入,可以了解一些python面向对象编程的原理,不过这部分内容在机器学习中用到的不多。
https://www.coursera.org/learn/python/home/welcome步骤一我建议对于基础好的同学可以略过,对于基础稍弱的同学在一个月之内,每天学习2-4个小时就能基本上掌握大概,后面碰到不懂的,再去对应学习即可。
步骤二:机器学习入门
打好了数学基础和基本的python基础后,我们就可以正式开始机器学习的学习了。这部分就不得不提机器学习领域最著名的网课和书籍了。网课那就是斯坦福大学Andrew Ng吴恩达在coursera上的免费网课machine learning了。
https://www.coursera.org/learn/machine-learning/home/welcome这个网课一定要看,老师讲的浅显易懂,对小白来说很友好,课后编程作业是用Matlab写的,如果不懂Matlab的同学也可以用python做,在GitHub上有很多人把自己用python实现的算法po了上去,可以找对应的GitHub repo去看。
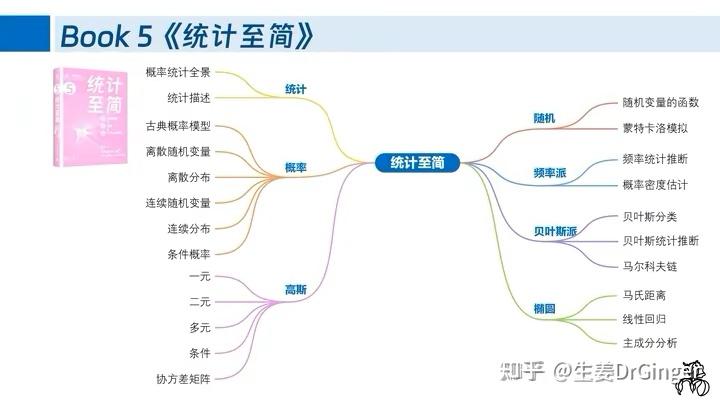
看完网课之后,就可以找对应的书籍加深对于机器学习基础的理解。网课的内容覆盖有限,起到一个启蒙的作用,对相应内容了解大概之后,可以读一读李航老师的《统计学习方法》和周志华老师的《机器学习》,又称西瓜书。这两本书我更建议先看《统计学习方法》,这个讲解更浅显一些。在这个部分,可以主要看一下《统计学习方法》前8章基本的监督学习内容和第13-16章基本的无监督学习内容。之后有时间可以看看其他章节的拓展内容,比如马尔可夫模型、EM算法等等。对于西瓜书可以先看看前10章的内容,之后再了解后续内容。
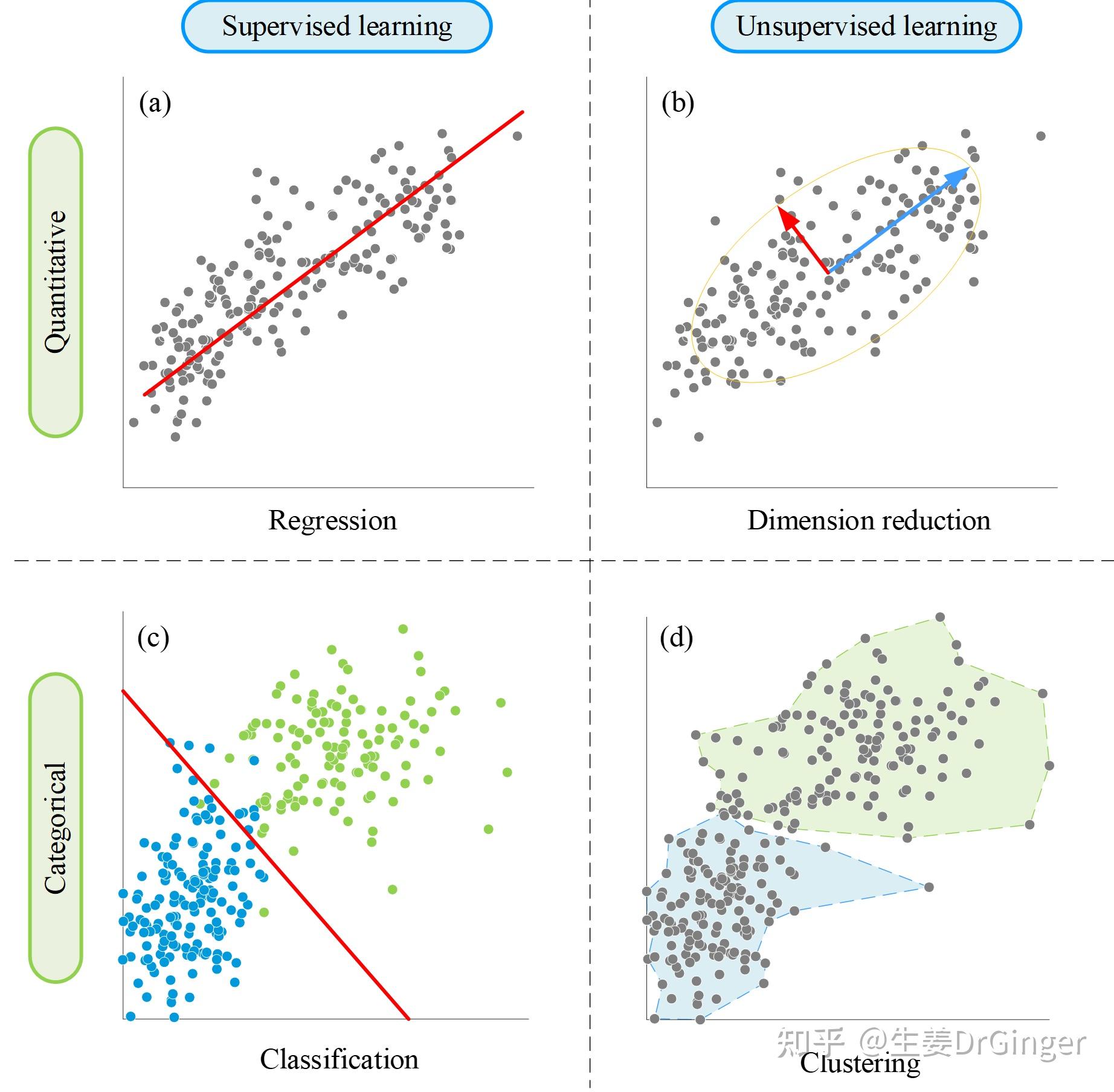
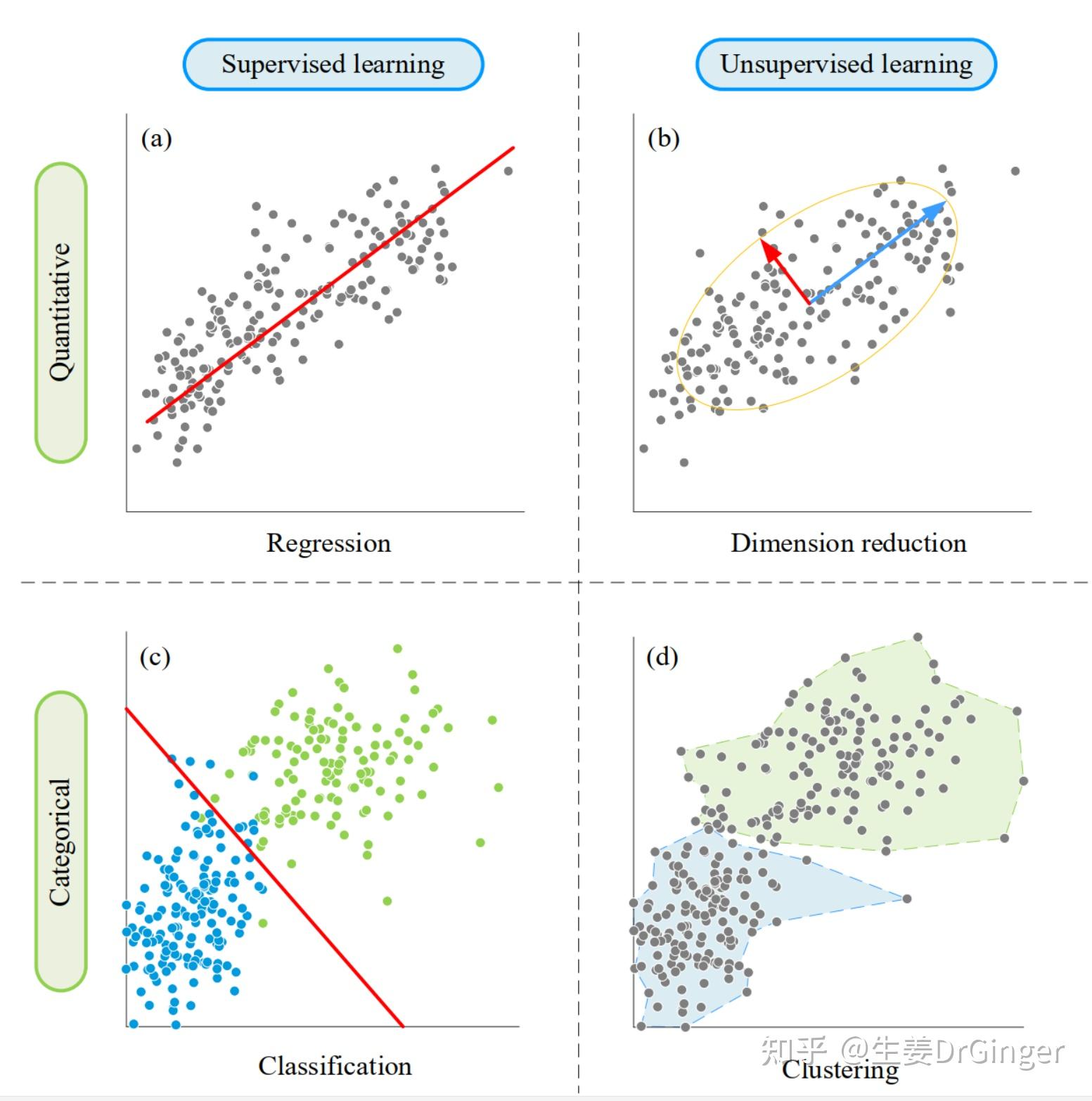
学到这里,我们就对机器学习有一个基本的了解,但是这些都是理论知识,缺少实战经验,为了提高机器学习的实战能力,我推荐《机器学习实战》这本书,教你怎么样用python实现之前所说的那些算法,基本的回归、分类、聚类、降维在那里都有。
下面就是一些近期大火的深度学习内容的学习,深度学习由于是近几年才兴盛起来,书籍没有很多,主要通过网课和论文学习。这里我推荐吴恩达的深度学习专项课程。老师的讲解同样深入浅出,能够快速了解深度学习在近些年的发展,包括基本的神经网络模型、卷积神经网络、循环神经网络以及深度学习领域的一些trick。作业是用python完成的。如果你能听完课,做完作业,那么python水平会得到很大提高,并且会使用一些keras、tensorflow的框架构建深度学习模型。
https://www.coursera.org/specializations/deep-learning至此,第二步骤告一段落,如果能做完上面的步骤,你已经成为机器学习领域半个专家,这个时候已经可以去互联网公司面试了,运气好的话,就可以找到一份算法岗位的实习机会,继续精进机器学习算法知识。这个步骤大概用时4-6个月,每天2-4小时
步骤三:持续提高工程能力和机器学习领域知识
下面这一步,本人也是正在进行中,来和大家讲讲我的计划。如果要成为一个出色的算法工程师,那么就要做到持续学习。如今算法工程师不仅需要懂机器学习,更要是一个合格的软件工程师,代码能力非常重要,要会复现paper,上线模型。这个部分可以通过打比赛来提高。著名的比赛有两个,一个是国外的Kaggle网站,另一个是国内阿里的天池竞赛,通过参加比赛,提升自己的代码能力和对机器学习领域的理解。
https://www.kaggle.com/天池大数据众智平台-阿里云天池这里可以选一个自己喜欢的方向进行深入钻研,目前业界比较火的三个方向是广告推荐、自然语言处理NLP和计算机视觉CV方向。同时也有一些相对小众比如异常检测、风控等方向等待大家去挖掘。学习这些知识需要通过阅读最新业界的论文。AI领域的顶级会议包括AAAI, SIGKDD, IJCAI, AISTATS等等,阅读这些论文可以了解业界最新进展,启发思路。
另外在这个阶段,可以继续夯实基础,我推荐几本书。首先还是之前的《统计学习方法》和西瓜书,可以将剩下的章节阅读完。另外就是两本机器学习领域的圣经《Pattern Recognition and Machine Learning》和《Element of Statistic Learning》,这两本书是机器学习领域不可不读的经典著作。另外深度学习领域的圣经则称为花书,也是可以拜读的经典著作。
步骤三更多的是在实践与工作中学习,计算机领域是个需要终身学习的地方,算法岗更是如此,每年深度学习算法都会有大的突破,需要不断阅读新论文,提高自己,如果大家希望入行机器学习算法,可以按照上面步骤做,虽然如今算法岗内卷严重,但如果努力,还是能在强手如林的算法领域找到一席之地,与君共勉!
下面是上述提到的几本书链接,大家有兴趣可以从我的链接点进去购买,都是京东自营的,良心推荐
<a data-draft-node="block" data-draft-type="mcn-link-card" data-mcn-id="1365382978651115520"> |