做一名调包侠,根本不用先学机器学习,github上找个star多的repo,下载下来改一改跑起来完事了。
下面的回答我主要写段子(如有雷同,纯属巧合):
- 某位小朋友觉得学习率1e-3, 1e-4模型收敛太慢了,决定设成10;然后问我,为什么这个loss越来越大啊?
- 某位小朋友说我有一个绝妙的想法:把LSTM末层输出与词向量求差值平方和,然后互相更新,这样就可以得到词向量了!
如何在训练LSTM的同时训练词向量?3. 某位小朋友觉得自编码器怎么都是两边输入输出的维度高,中间的维度低;自己有一个图灵奖级别的idea,设计一个两边输入输出的维度低,中间的维度高的模型。
小朋友,你是不是有很多问号?
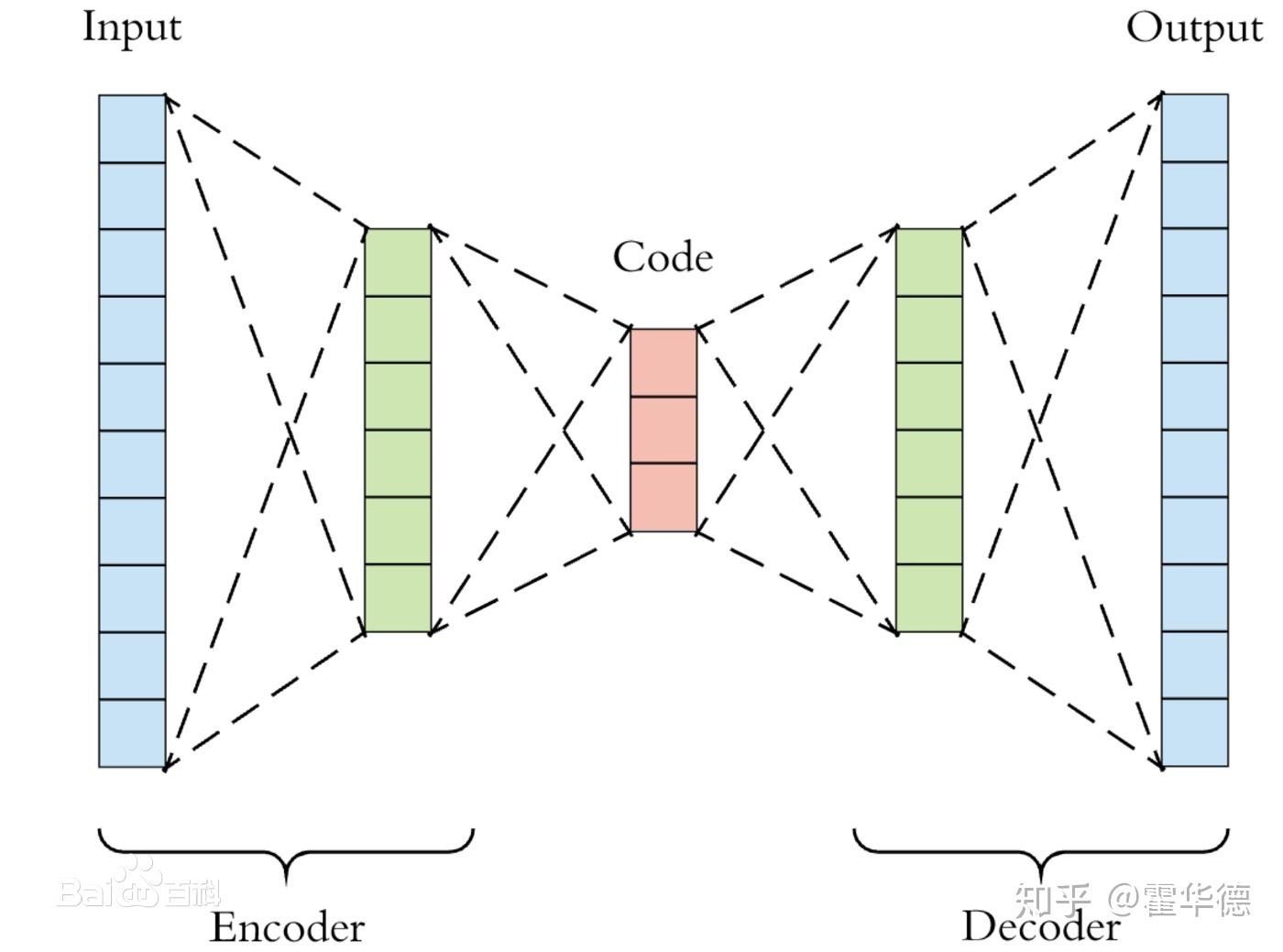
<hr/>万万没想到第3点,引发了巨大讨论。大家的建议和评论都非常有意思。我这里只是提供一下我的看法,在自编码器的框架下:
自编码器的隐藏层的维度 要小于输入层的维度 要小于输入层的维度 ,才有意义。 ,才有意义。
- 如果隐藏层的维度 和输入层的维度 相等的时候,只要令全连接层的权重为单位矩阵,偏置为0,就可以得到一个自编码器,这个自编码器没有提取任何特征。
- 当隐藏层的维度大于输入层的维度,存在无数个权重矩阵相乘可以得到单位矩阵,这就意味着提取不到信息。
- 只有隐藏层的维度要小于输入层的维度的时候,权重矩阵相乘无法可以得到单位矩阵,此时学习到的权重才是非平凡的。
|



