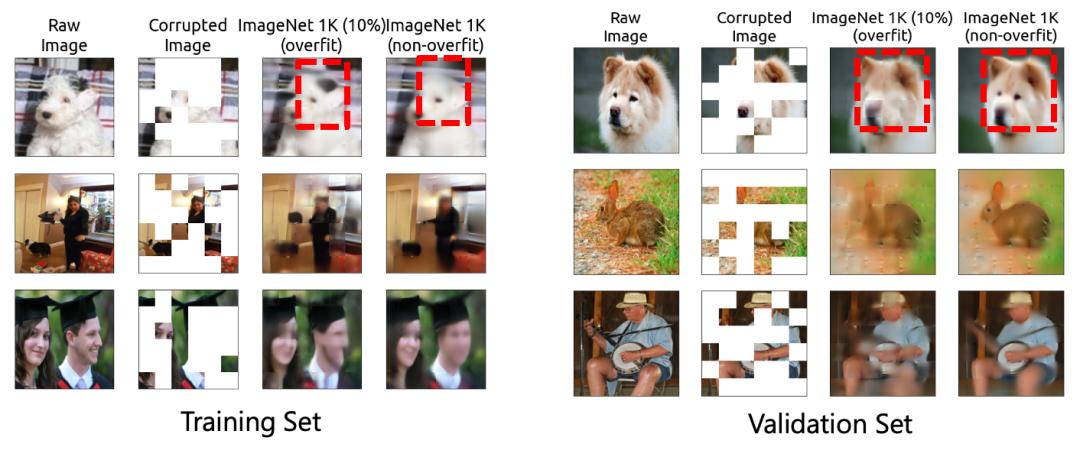
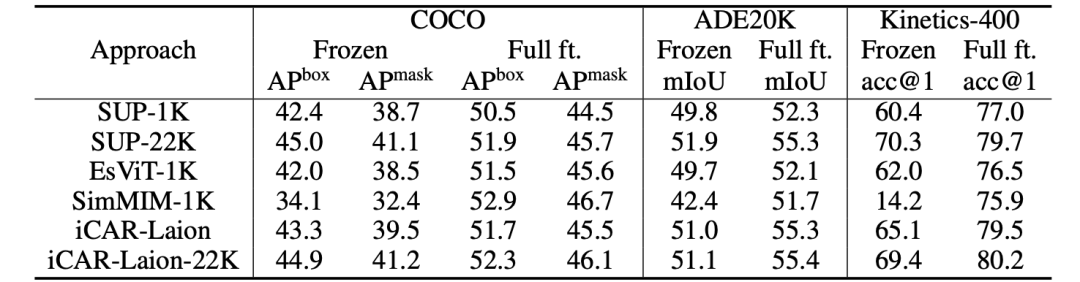
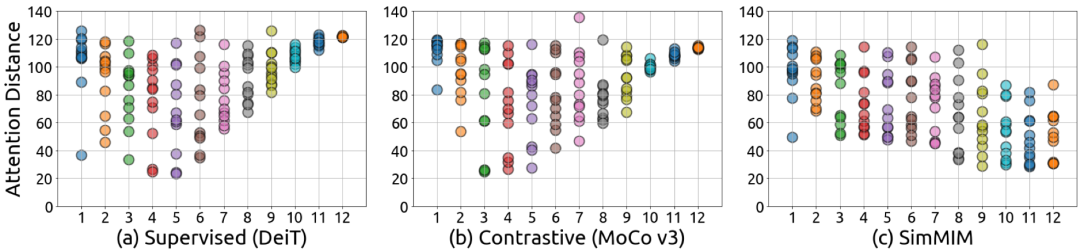
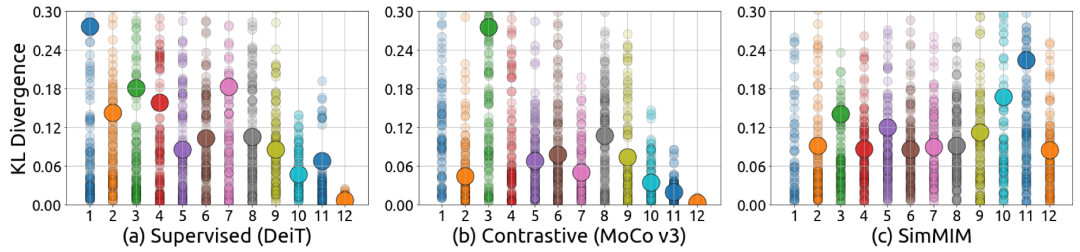
个人比较关注 生成式 这个方向,包括不限于扩散模型diffusion、GAN生成对抗网络等。
生成模型当然远不止于直接用于生成,它们在计算机视觉中各项任务(low-level、high-level、图像理解等等)有着诸多妙用。近段时间,看了一下CVPR 2023,这里列举汇总一下里采用 AIGC 的思路解决 CV任务 的论文吧!
先放个详细介绍的版本,每篇论文都附上了简介、以及代码(如果开源),后面再列个清单list。
AI生成创作:一口气读完 CVPR 2023 最全 AIGC 论文!6万字!30个方向130篇!
- 1、图像转换/翻译
- 2、GAN改进/可控
- 3、可控文生图/定制化文生图
- 4、图像恢复
- 5、布局可控生成
- 6、医学图像
- 7、人脸相关
- 8、3D相关
- 9、deepfake检测
- 10、图像超分
- 11、风格迁移
- 12、去雨去噪去模糊
- 13、图像分割
- 14、视频相关
- 15、对抗攻击
- 16、扩散模型改进
- 17、数据增广
- 18、说话人生成
- 19、视图合成
- 20、目标检测
- 21、人像生成/姿态迁移
- 22、发型迁移
- 23、图像修复
- 24、表征学习/表示学习
- 25、语音相关
- 26、域适应/迁移学习
- 27、知识蒸馏
- 28、字体生成
- 29、异常检测
- 30、数据集
一、图像转换/翻译
- 1、Masked and Adaptive Transformer for Exemplar Based Image Translation
- 2、LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
- 3、Interactive Cartoonization with Controllable Perceptual Factors
- 4、LightPainter: Interactive Portrait Relighting with Freehand Scribble
- 5、Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
- 6、Few-shot Semantic Image Synthesis with Class Affinity Transfer
二、GAN改进
- 7、CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
- 8、Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
- 9、Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
- 10、Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
- 11、Improving GAN Training via Feature Space Shrinkage
- 12、Look ATME: The Discriminator Mean Entropy Needs Attention
- 13、NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
- 14、DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
- 15、Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
- 16、SIEDOB: Semantic Image Editing by Disentangling Object and Background
三、可控文生图/定制化文生图
- 17、DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 18、Ablating Concepts in Text-to-Image Diffusion Models
- 19、Multi-Concept Customization of Text-to-Image Diffusion
- 20、Imagic: Text-Based Real Image Editing with Diffusion Models
- 21、Shifted Diffusion for Text-to-image Generation
- 22、SpaText: Spatio-Textual Representation for Controllable Image Generation
- 23、Scaling up GANs for Text-to-Image Synthesis
- 24、GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
- 25、Variational Distribution Learning for Unsupervised Text-to-Image Generation
四、图像恢复
- 26、Bitstream-Corrupted JPEG Images are Restorable: Two-stage Compensation and Alignment Framework for Image Restoration
- 27、Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
- 28、Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
- 29、Generating Aligned Pseudo-Supervision from Non-Aligned Data forImage Restoration in Under-Display Camera
- 30、 Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
- 31、Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Model
- 32、Robust Model-based Face Reconstruction through Weakly-Supervised Outlier Segmentation
- 33、Robust Unsupervised StyleGAN Image Restoration
五、布局可控生成
- 34、LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
- 35、LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
- 36、PosterLayout: A New Benchmark and Approach for Content-aware Visual-Textual Presentation Layout
- 37、Unifying Layout Generation with a Decoupled Diffusion Model
- 38、Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
六、医学图像
- 39、High-resolution image reconstruction with latent diffusion models from human brain activity
- 40、 Leveraging GANs for data scarcity of COVID-19: Beyond the hype
- 41、Why is the winner the best?
- 45、Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
七、人脸相关
- 46、A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
- 47、DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
- 48、DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
- 49、Fine-Grained Face Swapping via Regional GAN Inversion
- 50、SunStage: Portrait Reconstruction and Relighting using the Sun as a Light Stage
八、3D相关
- 51、3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
- 52、Controllable Mesh Generation Through Sparse Latent Point Diffusion Models
- 53、GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
- 54、GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
- 55、Graphics Capsule: Learning Hierarchical 3D Face Representations from 2D Images
- 56、HOLODIFFUSION: Training a 3D Diffusion Model using 2D Images
- 57、Learning 3D-aware Image Synthesis with Unknown Pose Distribution
- 58、Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
- 59、Magic3D: High-Resolution Text-to-3D Content Creation
- 60、NeuFace: Realistic 3D Neural Face Rendering from Multi-view Images
- 61、NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models
- 62、Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
- 63、SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
- 64、SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
- 65、Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
- 66、T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
- 67、TAPS3D: Text-Guided 3D Textured Shape Generation from Pseudo Supervision
九、deepfake检测
- 68、Detecting and Grounding Multi-Modal Media Manipulation
十、图像超分
- 69、Activating More Pixels in Image Super-Resolution Transformer
- 70、Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
- 71、Implicit Diffusion Models for Continuous Super-Resolution
- 72、Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
- 73、Structured Sparsity Learning for Efficient Video Super-Resolution
- 74、Super-Resolution Neural Operator
- 75、Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
十一、风格迁移
- 76、CAP-VSTNet: Content Affinity Preserved Versatile Style Transfer
- 77、Inversion-Based Style Transfer with Diffusion Models
- 78、Neural Preset for Color Style Transfer
十二、去雨去噪去模糊
- 79、Learning A Sparse Transformer Network for Effective Image Deraining
- 80、Masked Image Training for Generalizable Deep Image Denoising
- 81、Uncertainty-Aware Unsupervised Image Deblurring with Deep Residual Prior
十三、图像分割
- 82、DiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
- 83、Generative Semantic Segmentation
- 84、Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
- 85、Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
十四、视频相关
- 86、A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
- 87、A Unified Pyramid Recurrent Network for Video Frame Interpolation
- 88、Conditional Image-to-Video Generation with Latent Flow Diffusion Models
- 89、Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
- 90、Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
- 91、MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
- 92、MOSO: Decomposing MOtion, Scene and Object for Video Prediction
- 93、Text-Visual Prompting for Efficient 2D Temporal Video Grounding
- 94、Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
- 95、Video Probabilistic Diffusion Models in Projected Latent Space
- 96、VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
十五、对抗攻击
- 97、Adversarial Attack with Raindrops
- 98、TrojDiff: Trojan Attacks on Diffusion Models with Diverse Targets
十六、扩散模型改进
- 99、All are Worth Words: A ViT Backbone for Diffusion Models
- 100、Towards Practical Plug-and-Play Diffusion Models
- 101、Wavelet Diffusion Models are fast and scalable Image Generators
十七、数据增广
- 102、DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
- 103、Leveraging GANs for data scarcity of COVID-19: Beyond the hype
- 104、Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
十八、说话人生成
- 105、MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
- 106、Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
十九、视图合成
- 107、Consistent View Synthesis with Pose-Guided Diffusion Models
二十、目标检测
- 108、Multi-view Adversarial Discriminator: Mine the Non-causal Factors for Object Detection in Unseen Domains
二十一、人像生成-姿态迁移
- 109、Person Image Synthesis via Denoising Diffusion Model
- 110、VGFlow: Visibility guided Flow Network for Human Reposing
二十二、发型迁移
- 111、StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
二十三、图像修复
- 112、SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
二十四、表征学习
- 113、GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
二十五、语音相关
- 114、Conditional Generation of Audio from Video via Foley Analogies
- 115、Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos
- 116、Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
二十六、域适应-迁移学习
- 117、Back to the Source: Diffusion-Driven Test-Time Adaptation
- 118、Domain Expansion of Image Generators
- 119、Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
二十七、知识蒸馏
- 120、KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
二十八、字体生成
- 121、CF-Font: Content Fusion for Few-shot Font Generation
- 122、Handwritten Text Generation from Visual Archetypes
二十九、异常检测
- 123、SQUID: Deep Feature In-Painting for Unsupervised Anomaly Detection
三十、数据集
- 124、An Image Quality Assessment Dataset for Portraits
- 125、CelebV-Text: A Large-Scale Facial Text-Video Dataset
- 126、Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
- 127、Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
戳我,查看GAN的系列专辑~!深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种基于生成扩散模型Stable Diffusion、可控生成的AIGC绘画生成算法!
CVPR 2022 | 最全25+主题方向、最新50篇GAN论文汇总
超110篇!CVPR 2021最全GAN论文汇总梳理!
ECCV2022 | 生成对抗网络GAN论文汇总
经典GAN不得不读:StyleGAN
超100篇!CVPR 2020最全GAN论文梳理汇总!
- GAN整整6年了!是时候要来捋捋了!
- GAN公式简明原理之铁甲小宝篇
- 【实习面经】GAN生成式算法岗一面
- 语义金字塔式-图像生成:一种使用分类模型特征的方法
- 拆解组新的GAN:解耦表征MixNMatch
- 经典GAN不得不读:StyleGAN
- CVPR 2020 | StarGAN第2版:多域多样性图像生成
- CVPR 2020 | 11篇GAN图像转换img2img 的论文
- CVPR2020之MSG-GAN:简单有效的SOTA?
- CVPR2020之姿势变换GAN
- CVPR2020之多码先验GAN:预训练好的模型怎么使用?
- 两幅图像!这样能训练好 GAN 做图像转换吗?
|