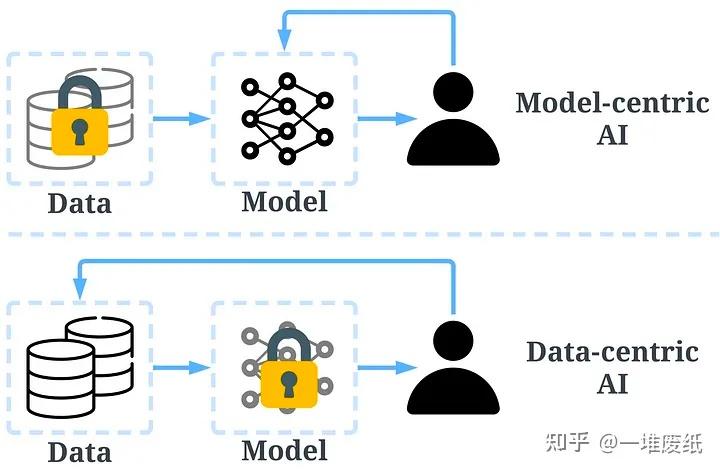
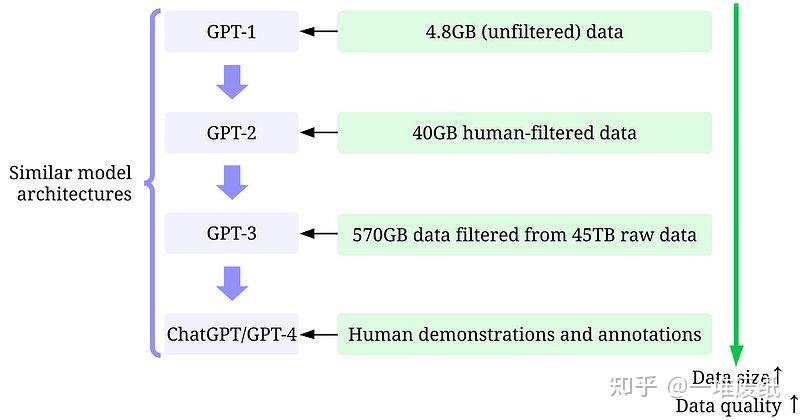
先说结论,nlp人才需求大概率不变,也就是说收人还是会收,但是方向会大大转变。
我做生成式模型有一段时间,也想分享我这段时间的看法:
第一,传统NLP需求大大减少,传统的分类,识别,抽取这种,如果还只会用bert或者类似小模型(1亿参数以下)来做,会一些领域微调,模型上线裁剪啊,这种人大概率找不到工作!
第二,对有大模型部署经验的需求大大提高,超大模型(GPT3,ChatGPT等千亿参数量模型)这些效果确实好,但是实际训练,没几家能训练出,所以怎么去应用超大模型到自己业务中,可以选择去调用APi,可以选择大模型(百亿,十亿)。如何依照业务场景做选择是非常考验人的问题。
第三,对语料数据收集能力,prompt构造能力要求大大提高,其实我在测试文心和GPT3,4发现,与其说是zero-shot,倒不如说是prompt 监督输出!能写代码,能写日记,新闻都是之前微调指令集有,如果没见过,模型只能乱说。所以就和第二结合,怎么将大模型应用到自己业务上,这就需要与业务结合的prompt了!
第四,大模型训练的需求,超大模型的训练国内没几家大厂可以做,但是百亿量级的大模型,我觉得会有井喷的现象,我在测试中发现,百亿模型是可以真正能应用大业务中,而且效果不是很大折扣。如果训练效果好,是可以做成业务上通用模型的。 |