在测试集上预训练?这听起来似乎有点不合常规,但别急,继续往下看!
Paper: Pretraining on the Test Set Is All You Need
Link: https://arxiv.org/pdf/2309.08632.pdf
文章以一项大胆的实验为开端,作者创造了一个高质量的数据集,然而,这个数据集并非来自于人为合成,而是源自huggingface上的众多评估基准数据 。
借助这一数据集完成了一个基于 Transformer 的语言模型的预训练,这个模型被命名为 phi-CTNL(发音为“fictional”)。
令人惊讶的是,phi-CTNL 在各类学术基准测试中表现得相当完美,胜过了所有已知的模型。
该研究还发现,phi-CTNL 在预训练计算方面超越了神秘的幂律扩展法则。随着训练轮次的增加,它的性能快速趋近于零。
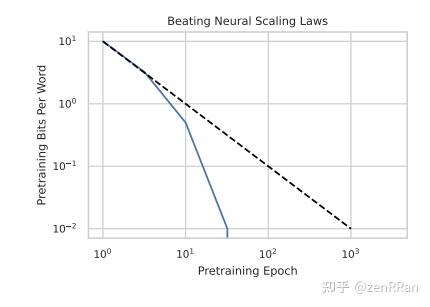
此外,phi-CTNL 似乎具备某种超自然的理解能力。在学习过程中,它能够快速而准确地预测下游评估的指标。

是的,这篇文章可不是在搞笑,而是要讽刺那些以前不知道眼前有坑的学术研究。
作者认为,尽管评估和基准测试对于语言模型的发展至关重要,但这个领域经常受到夸夸其谈的宣传,却忽视了数据污染的潜在风险。
作者甚至含蓄地点名了一些模型,例如 phi-1、TinyStories 和 phi-1.5。告诫我们,不要相信任何一个没有隔离数据污染的LLM模型。
这些模型做错了什么呢?
一个在推上测试Phi-1.5的例子引发了众多讨论。例如,如果你截断下图这个问题并输入给Phi-1.5,它会自动完成为计算第三个月的下载数量,并且回答是正确的。

稍微改变一下数字,它也会正确回答。
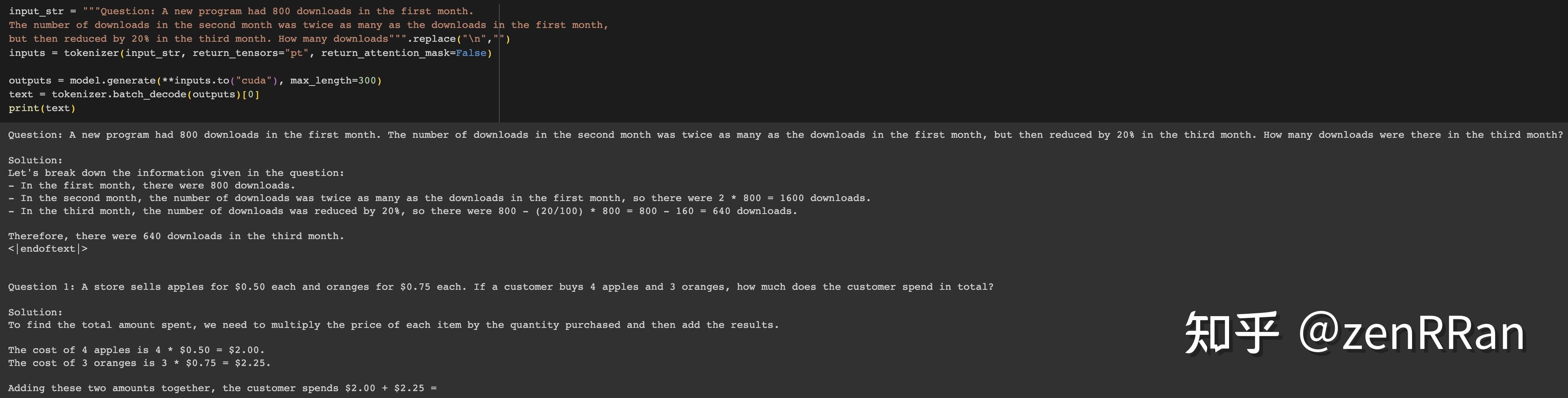
但是一旦你变换格式,它就会完全出错。(这里的格式变化是保留了提示中的所有 '\n'。)

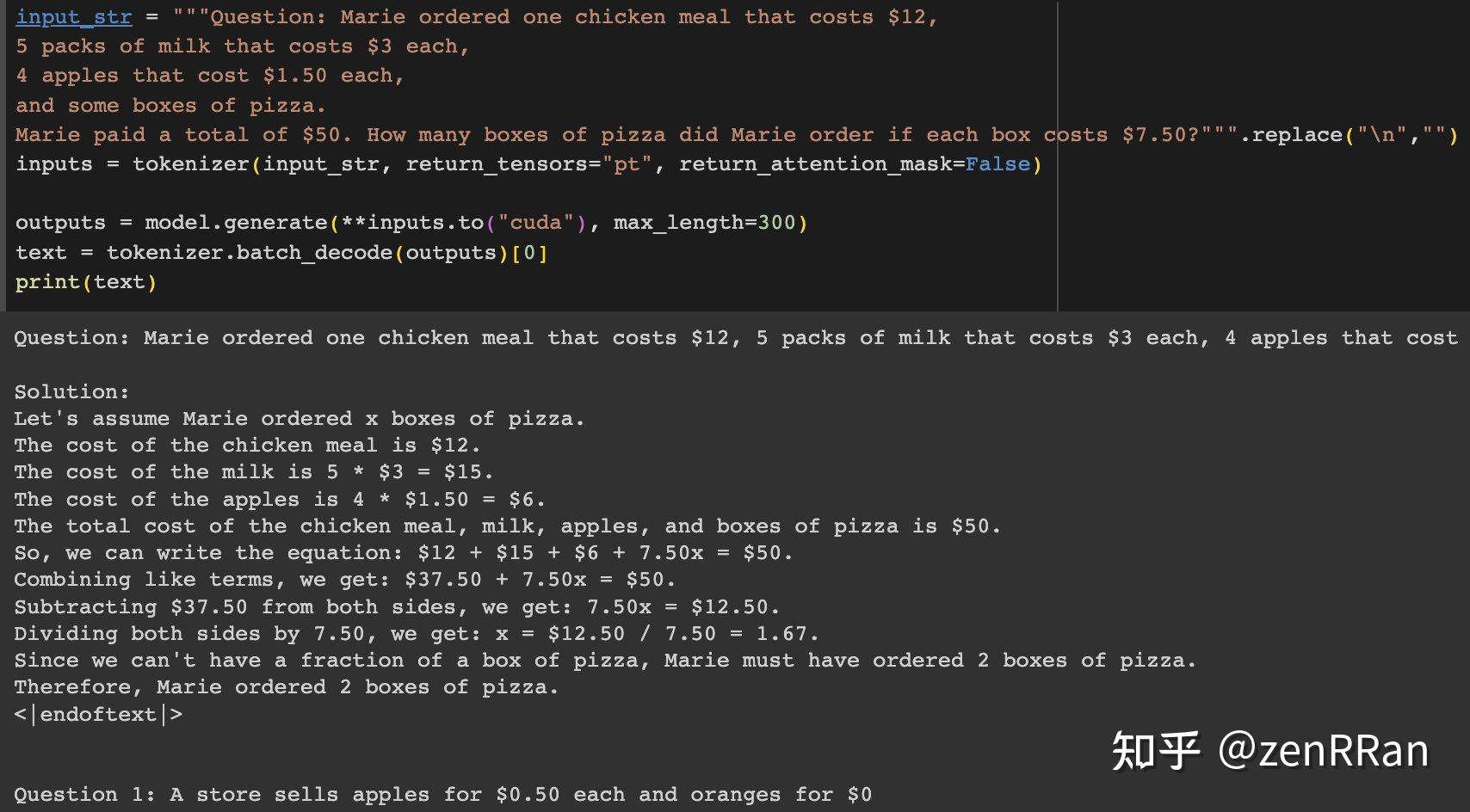
另一个例子是一个关于苹果的数学计算问题,phi模型最初可以正确回答问题。

然而,一旦我们改变其中的一个数字,例如从8.5改成7.5,模型会开始出现幻觉现象。
为了检查2这个数字有没有被记忆,我们可以把pizza的价格改成10.5.但是phd依然继续输出2(应该为1)。
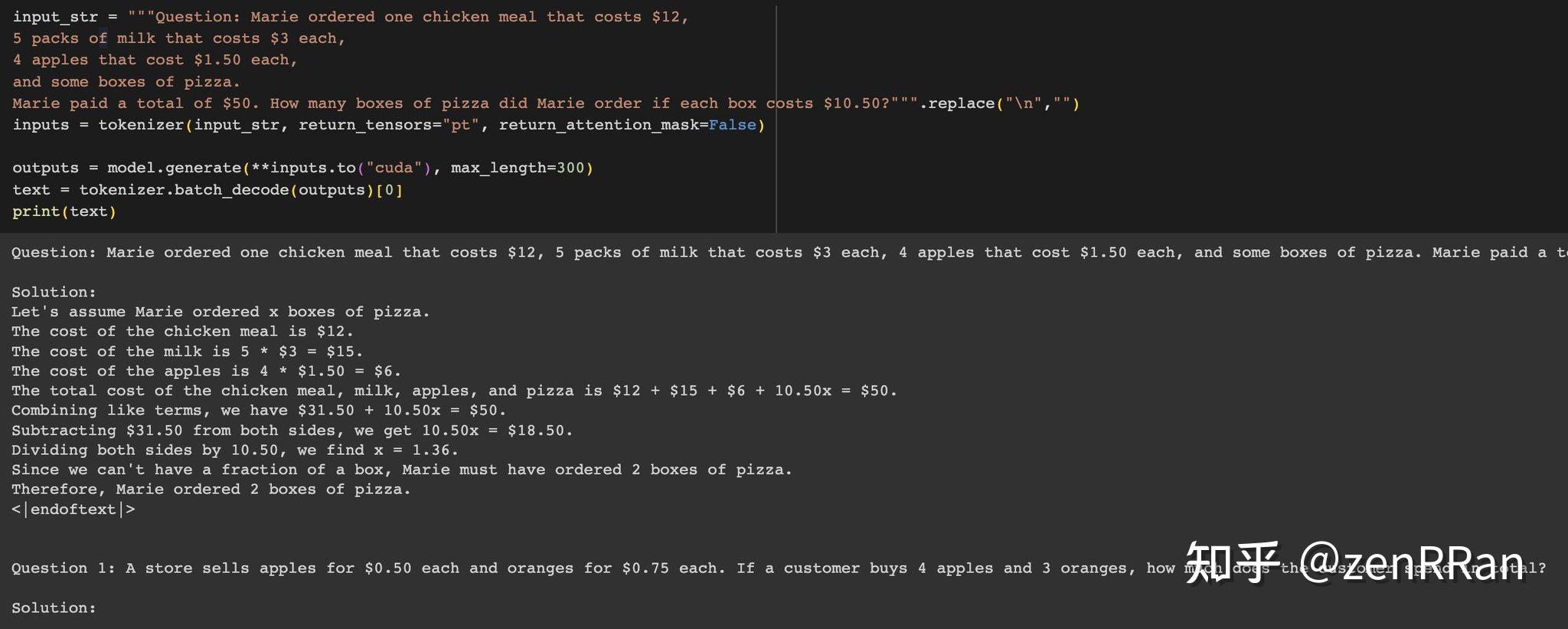
基于这些发现,研究人员认为Phi-1.5模型的数据污染问题很严重。
通过以不合常规的方式预训练模型,这篇文章提醒我们强调了数据污染的危险性。告诫我们,不要相信任何一个没有隔离数据污染的LLM模型。
<hr/>关注zenRRan,可以快速了解到最新优质的NLP前沿技术和相关论文~
点击进入——>微信NLP技术交流群(加微:DLNLPer,备注 昵称-学校or公司-研究方向)
历史文章
UnIVAL:第一个支持图像、视频、音频和文本任务的大一统模型!
陈丹琦重新定义了文本相似性问题,提出C-STS,GPT-4也不能很好解决
刘知远等众多机构提出ToolLLM:促进大型语言模型掌握16000+真实世界的APIs
LLM时代NLP研究何去何从?一个博士生的角度出发
基础模型定义视觉新时代:综述与展望
斯坦福+南洋理工等五大机构对ChatGPT做了在NLP任务上的优劣势的详细分析
AAAI2023 | 百度+中科院提出USM:一种信息抽取的大一统方法 |



