个人简介: 南方一所211的计算机专业硕士,大数据从入门学习,实习到今天刚好一年半的时间,刚在杭州某未上市的互联网大厂实习结束,实习岗位是数据研发工程师!
志同道合的小伙伴可以进入大数据交流群一起学习 :763068478
竞争的程度相对小
- 比普通后端开发和算法岗竞争小,目前大部分应届生首选的都是从事后端开发,所以每年春招和秋招的时候真的存在一些岗位神仙打架的情况,一些后端岗位的投录比高的吓人,而大数据开发岗位是15年左右才开始热门起来的岗位,相对来说竞争比较小,而且因为学校比较少有对应专业的应届生,所以缺口还是比较大的。(最明显的是目前XX跳动的秋招到今天后端基本都招满了,但是大数据的很多秋招岗位还有缺口)。
- 最重要的,也是一个最实际的问题:每一个行业当人很多的时候门槛就会越来越高,那在第一关筛选简历的时候很多时候都是简单粗暴直接从学历开始筛,所以今年有一些学校还不错的同学卷后端出现简历练初筛都没有通过,反而比他学校略差的同学投递非后端岗位都过了初筛。
- 其次大数据开发的收入待遇也处于普通后端开发和算法岗之间,或者最低保证也是和后端待遇持平;
就业方向选择多
大数据专业未来就业有几个方向,看你是往工程方向走还是往数据分析方向走。 工程方面会有数据仓库开发和数据平台开发两类。
- 数据仓库处于技术与业务之间。
- 数据平台开发会处于技术底层。
- 数据分析会离业务最近。
---------------------------------------分割线---------------------------------------
下面主要是针对有意入门大数据行业的应届生,提出一些个人的经验以及建议,避免像我一路摸爬滚打过来走了不少的弯路。 现在很多人都会在互联网上寻找一些学习的资料,但是很多资料的质量其实远没有达到我们的预期,尤其主次不分明,讲得不够精华,这对于我们刚要入门的小白来说非常不利。这么多资料一下子全学基本都只能懂得一些皮毛,而且还比较浪费时间。那时候刚入门的时候,我相信很多人都有这样的想法,如果有一个人给我画个重点那是多么好啊。 所以今天我希望我可以成为一个去年自己期待的那个指路人,能为正在迷茫的你们带来一点帮助。
学习和面试时间线
学习时间线
其实整个学校时间线可以分为两部分学习和实习:
- 大概花3-6个月的时间进行学习大数据的相关知识点,并且中间要多刷算法题和顺带刷一点SQL题;
- 如果在有时间的基础上,可以考虑两段实习;如果时间不允许的话,其实一段实习也足够了;
第一段实习的时间:对于三年制的研究生,最好在研二第1学期,对于本科生来说,最好是 在大三的第1学期(对于本科生可能有点难度)。主要原因,这段时间的实习比较好找,因为大部分实习生都返校,大厂这时候空出来比较多的岗位,需求量也有,竞争也会比较小;可以比较低的成本进入公司,而且这一段实习主要是为了积累项目经验,为春招拿到更好的offer做铺垫;
第二段实习的时间:最好在研二第2学期到暑假这段时间,对于本科生来说,最好是在大三的第2学期到暑假,(能早点去实习就早点去,因为早点去实习后,有时间准备提前批)春招一般都是过完年之后大概半个月就会拉开帷幕,所以也就是金三银四,所以三月和四月就是我们真正检验学习成果的时候了。有一份好的春招实习对于你后面拿正式offer会有很大的帮助,比如:
- 直接在实习公司秋招答辩转正
- 拿到春招offer,假如没有去实习,部分公司可以在提前批的时候直通终面
- 大厂背景会在秋招面试的时候发挥出比较大的作用,尤其筛选简历
3.秋招提前批今年从6月下旬就开始一直到8月左右,一定要抓住提前批去面一面,提前批其实和常规批的面试难度差不多,不过竞争小很多,因为这时候很多人才刚开始实习,还在适应实习的工作环境。而且提前批的投递不影响正式批,也就是你会多了一次投递或者面试的机会
4. 秋招正式批,一般是从8月上旬左右开始,这时候就要开始各种笔试和面试了,在这里提醒能在提前批面试尽量在提前批面试,因为正式批投递的人数远远大于提前批,竞争人数应该会上升一个倍数,因为这时候所有实习和非实习的都全身心投入到正式批中去了;
面试大体内容
因为面试过去的时间比较久了,有一些问题忘了,只记录了一些自己记得的大体部分,大体都是2-3轮技术面+1轮HR面,其中一面和二面会问一些基础和项目,第三面一般都是比较偏项目和思维的考察;可能也是比较幸运,自己在春招和秋招面过的岗位基本都能挺好最后一轮,也基本都拿到意向(包括蚂蚁,腾讯,京东,快手,网易,科大讯飞等等),秋招因为实习完感觉还不错直接转正了并且也拿了鹅厂的提前批意向书,也就没有投递了,直接躺平。所以面试基本都是春招的时候为主。
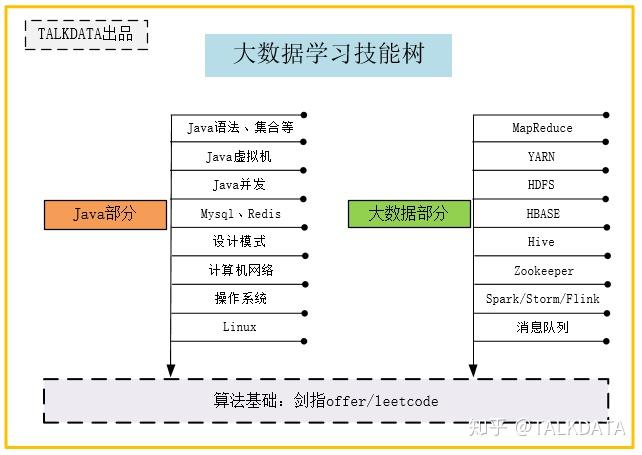
大数据的学习路线
基础篇
- (★★★★)作为一个计算机从业者,首先必须具备相应的计算机基础知识,包括
- 操作系统知识
- 计算机网络知识
- 数据结构及算法
- 数据库基本知识
- Linux常用命令
- (★★★★)语言基础,必须要熟练一门语言,大数据主要使用的编程语言是Java,Scala以及SQL,不仅要会用,而且要知其所以然:
- Java语言,JVM虚拟机, 线程,集合等
- Scala语言
- SQL语言以及基本调优,主要是Hive SQL
大数据篇
- (★★★★★) 大数据入门Hadoop生态体系,主要掌握分布式数据处理,存储的思想,以及会写一些简单的MR任务:
- Hadoop生态圈的全貌
- MR,Yarn,HDFS的工作过程
- Zookeeper架构以及原理
- 数据采集的对应框架Sqoop,Flume;
- 任务平台Oozie和Azkaban,主要是了解工作原理;
- (★★★★★)数据仓库建模方法理论,以及OneData方法论:
- E-R建模理论
- 维度建模理论
- DataVault建模理论
- (★★★★★)离线数据处理,主要围绕Hive,Spark的学习
- Hive的基本架构以及工作流程
- Hive的基本调优
- Spark的基本架构以及工作流程
- Spark的基本调优
- 数据倾斜的处理
- (★★★★) 实时数据处理,主要围绕Spark Streaming和Flink进行学习
- Spark streaming的基本架构以及工作流程
- Spark streaming的基本调优
- Flink的基本架构以及工作流程
- Flink的基本调优
- Hbase的基本架构
- Kafka消息队列
- (★★★) 数据治理
- 元数据管理
- 数据质量监控
- 数据存储治理
- 数据计算治理
- (★★★★★)算法与SQL:
- Leetcode热门100题
- 牛客在线编程热门100题(基本覆盖了面试的时候遇到的70%-80%的题目)
- 剑指offer的67题
- leetcode的SQL练习
资料推荐
1.视频资料
推荐B站最新的尚硅谷大数据视频,但是不需要全看,可以根据上面的学习框架进行筛选的看
然后跟着做一些项目,个人比较推荐做一个数据仓库的项目和一个实时的项目,这样简历的丰富度比较好,如果还不清楚,需要进一步细化,可以加群交流 :763068478, 因为每个人的背景和情况都不一样,没办法做一个通用的推荐;
2.面试资料
因为学完上面的知识之后,想要拿到好的实习或者秋招offer还是离不开面试的,并且面试其实是有一些前人的知识可以总结和沉淀的。在这一路学习以来以及大半年的实习过程中,我也不断做一些大数据的笔记以及在总结每一场面试的共同点以及常出现的知识点,包括我们到职场之后,在大数据这个领域摸爬滚打需要的基础知识,我都做了总结,基本这份资料从入门到现在一共花了一年半的时间整理出来的,包括实习期间学习到的一些建模理论。基本能涵盖绝大部分的大数据面试问题,同时也依靠这个过程整理出来的这份资料在春招和秋招中拿到了不错的offer。

最后放一张卑微打工人的身份照 |