Hadoop是一个由Apache基金会所开发的分布式系统基础架构,早期它的核心设计就两块,分别是HDFS(Hadoop Distributed File System)和MapReduce;HDFS是一个分布式文件系统,便于日志文件的存储和读写;MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
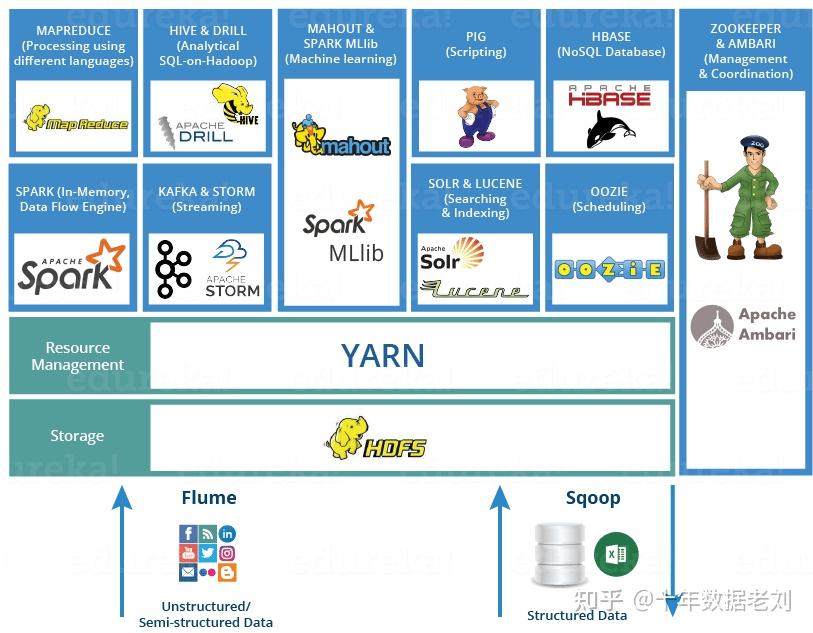
Spark也属于Hadoop生态下的一种编程模型,但数据处理采用的不再是mapreduce那一套,而是利用其内存计算的特性,将数据加载到内存中进行处理,大大减少了磁盘读写的开销,提高了处理速度;
从上述比较中其实可以看出,mapreduce分别有其优缺点,spark对内存的依赖较高,在需要高性能处理的场景,可优先使用spark,例如实时处理;Mapreduce的数据存储依赖磁盘,成本较低,离线大量数据计算而对性能要求不高的场景,优先使用Mapreduce。
如今Spark的工具会更加丰富,提供了例如机器学习(machine learning,ML),图计算等计算架构,因此在涉及这些场景时,应用会更加广泛。 |



