你叫杰杰马,你来到了青青草原,找了一块风水宝地插了个旗子,上面写着淘淘村,于是你成为了一个小村庄的村长。
(你创建了个互联网应用)
你还别说,这个小村庄还真有人来住,慢慢的有了几十号村民,还有过来吃住玩的旅人游客。
(你有了用户)
他们每天都会产生很多的生活垃圾,有残羹剩饭排泄物,有蛛丝马迹猫抓板,有记载着海贼王宝藏的藏宝图,有昨夜被谋杀的无名女尸,也有无人认领的大金链子……
(他们使用的同时产生各种各样的数据)
你暂时还没觉得这些垃圾有什么用,直接丢掉又有些可惜,你说我们建个大房子,把他们都装起来。
(你找了台服务器把数据(日志)存储起来)
第一章 HDFS
有一天,你的手下喜羊羊告诉你,这些垃圾对我们是有用的,残羹剩饭我们可以喂猪,无名女尸我们可以用来破案抓凶手,大金链子可以用来拴村口的大黄。
(你发现了数据的价值)
于是你又建立了个垃圾处理站,分类垃圾,处理垃圾。将处理好的垃圾变成资源,放到垃圾房的另一个角落摆的整整齐齐。
(你在这台服务器上写了几个数据(日志)处理程序,变成可用的数据)
生产大队、派出所、军需官都会不时过来取一些资源。
(各部门发现数据的价值)
日子一天天过去,你的小村庄慢慢发展成了小镇,之后又变成了一座城市。
(你的用户暴涨、飞速发展)
你的手下告诉你,垃圾生产的速度太快了,我们的垃圾房已经装不下垃圾了,垃圾处理站也处理不过来垃圾了!
(单机无法处理爆炸的数据)
“我们盖更大的垃圾房,找更能干的人来处理垃圾”
(你换更大硬盘更高处理器的服务器)
“不行啊城主,我们已经重建好几次垃圾站了,这个垃圾房是目前技术能盖的最大的房子了”
(除非你上超级计算机)
“那怎么办呢?”你着急的问道。
“”城主大人,你是沙雕吗?一座垃圾房放不下,我们多盖几座不就行了?”
“城主大人我当然不是沙雕,你呀,喜羊羊,你就是图样图森破,sometimes naive!我多盖几座,又没有钱每座都花大价格精装修消防,万一某一座失火了怎么办?”
(多台廉价商用机可能需要容错处理)
喜羊羊得意一笑:“城主大人,要解决这个问题其实一点都不难”喜羊羊吃了口羊肉串,喝了口扎啤接着说到:“城主大人,你忘了吗,我们只是把数据比喻成生活垃圾,数据有一点特别的地方,就是我可以拷贝复制,如果我进行多重备份,如此这般”
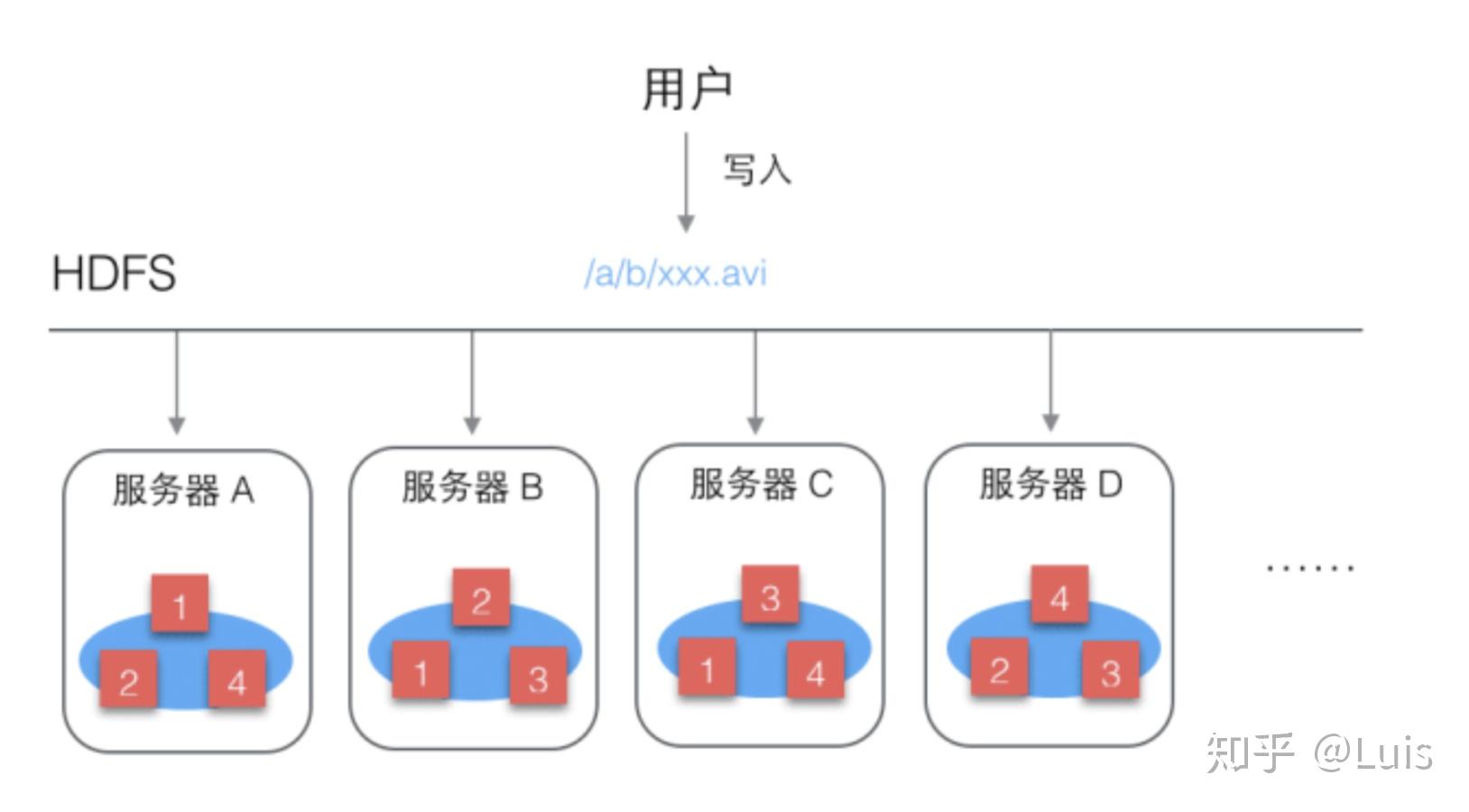
“这样,任意一台,啊不,一座垃圾房失火了,1234号垃圾箱都还在的,而且如果1号垃圾箱需要的人不较多,去abc三座垃圾房都可以取,也不会产生某一座垃圾房需要排队,其他垃圾房无人问津的问题。”
(HDFS即Hadoop Distribute File System,分布式文件储存系统,解决了数据分布式存储解决了多台存储单机热点、数据不安全、文件整理困难等问题,突破了存储限制)
喜洋洋看着一脸白痴的你,得意的接着说道:“我把这些存储垃圾与资源的垃圾房命名为垃圾仓库(datanode),在垃圾仓库ABCD之外,还有一个垃圾仓库管理中心(namenode)每次垃圾入库,需要管理中心安排垃圾自我复制多份放到不同的仓库,每次有人来取,需要去管理中心查询所需垃圾在哪些仓库并就近获取”
(namenode管理元数据,负责HDFS上数据的读写)
你觉得没有问题,得意的大笑:“有了这个套方案,不论再多的垃圾我都可以放的下,哈哈哈。喜羊羊,你不再是一只羊,以后你就叫做哑虎吧,你的部门就叫做Hadoop吧,这套方案就叫HDFS吧”
第二章 MapReduce
你以为有了这要垃圾存储方案,你就可以高枕无忧了,然后没几天就收到了很多问题。
(只解决海量数据存储是不行的)
你的各部门收下告诉你,虽然我们的垃圾都够放,并且井然有序,可以我们只有一个垃圾处理站,根本满足不了各个部门的需求,每天垃圾处理站门口排队的人比回龙观早高峰的地铁人还多。
(还需要解决海量数据计算)
于是,你又把哑虎叫了进来,“你们Hadoop部门顺便把海量计算也解决了吧”
喜羊羊早有准备,娓娓道来:“首先,我们肯定是要建很多的垃圾处理站,但是这些垃圾处理站是不能各干各的活的,因为垃圾直接是存在各种联系的”喜羊羊吃了口烤狼腰子,接着说道:“为了解决这个问题,我决定建一个叫做MapReduce的车队,Map阶段车队把垃圾分发给多个处理站,Reduce阶段车队把多个处理站处理的解决汇总给一个处理站再处理”
“你在说什么我完全听不懂”
“好的城主大人,举个例子。派出所的夏洛克同学想要知道昨天我们城死了多少男人和多少女人。第一步Map,把昨天五百吨的垃圾交给五个垃圾站,每个垃圾站统计分到的100吨垃圾中有多少男人尸体和多少女人尸体。第二步Reduce,把五个处理站的结果汇总到一起加起来,得到昨天我们城一共死了多少男人、多少女人。”
“等等,我大概理解了,你能不能换个例子”
“好的,请看下图”
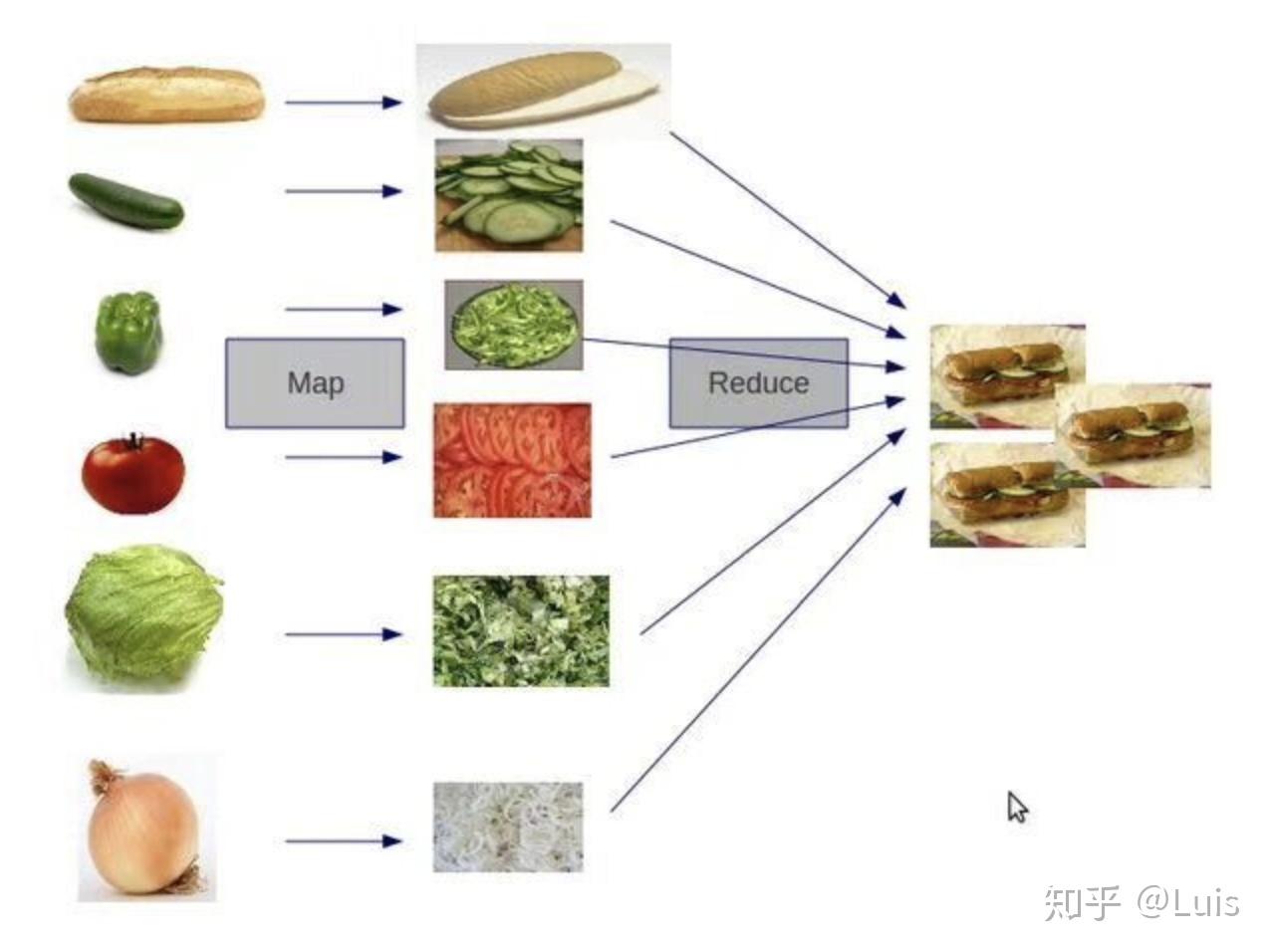
“我们在垃圾中发现了面包和蔬菜,交给各个处理站处理切碎,然后Reduce给一个处理站就得到了面包,然后放到HDFS就是资源啦”
“好的,我明白了,你不用再举这些恶心的例子了。以后HDFS、MapReduce都是你们垃圾部,不对,Hadoop部门管辖,希望你们把大垃圾处理事业发扬光大。啊,我仿佛看到了大垃圾时代的到来!”
(于是,有HDFS和MapReduce这两个组件组成的Hadoop1.0诞生了)

<hr/>2019-01-24 更新
第三章 Haddop2.0
有人的地方,就有江湖。
(这句话没什么用)
我们的喜羊羊同学麾下的大垃圾部越来越庞大。
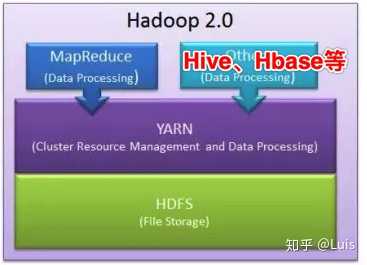
除了之前负责分布式存储垃圾的HDFS部门和负责分布式处理垃圾的MapReduce部队。为了解决部队资源的使用问题,喜羊羊成立了军机处:YARN。将所有的车、马、人等资源牢牢掌握在自己手中,每一次MapReduce部队的任务都需要在yarn这里申请、分配资源,喜羊羊对外宣称这是为了资源统一管理,提高利用率,然而坊间传闻,这是喜羊羊日益膨胀的野心与掌控欲的结果。
(YARN是Hadoop 2.0中的资源管理系统,它把集群的内存、cpu等资源抽象为资源池,负责整个系统的资源管理和分配,同时也可以监控管理程序应用。)
当喜羊羊推出他的特设组织Hive的时候,更是赢得了此时已经称王的你:杰杰马一世的欢心 和各部门大臣的信任。
(嗯,杰杰马接下来没多少戏份了)
Hive组织由一群高素质的人才组成。他们首先解决了一个痛点:各部门去使用垃圾的人习惯了说SQL这种语言,而MapReduce那群外邦过来的彪形大汉只会讲Java语言。让所有使用垃圾的人都会Java有些困难,并且还需要用java指挥他们去干活!所以真正能指挥MapReduce这个部队的只有一部分人。
(学习成本很高,一般数据分析、产品经理用不了,专业的工程师才会写MapReduce)
但是Hive出现了,他们充当了翻译官,并且熟悉MapReduce的工作方式,各部门只需要去找Hive组织,HIve再将SQL翻译给MapReduce。并且Hive这群复合型人才把HDFS上的各种处理好的垃圾分门别类管理的井井有条。
(Hive是一个基于HDFS的数据仓库工具,可以将Hive SQL转化为MapReduce进行数据处理查询的工具)
而当NoSQL家族的Hbase一支族人也来投奔,弥补了Hadoop部的重大短板,喜羊羊大宴三天,骄傲的说:大垃圾处理的大厦已经落成了,后人只需要在此基础上修修补补就好啦。
(Hbase是Hadoop项目的子项目,是一个分布式的、面向列的NoSQL数据库,虽然不是基于MapReduce,但是也是可以存储、处理大规模的数据,是Hadoop家族重要的一员)
(我找了一张Hadoop2.0的图)
喜羊羊成为了王国第一大红人,他位极人臣的权利带给他以奢靡著称的生活。据说喜羊羊大人杀了三千头狼取其腰子做烤狼腰子招待远道而来的Hbase的族人们,一时间导致王城方圆百里没有狼敢靠近。同时,喜羊羊傲慢的性格,蛮横的作风也让很多大臣敢怒不敢言。
(这一段是伏笔,没错,本程序员还会写伏笔)
然而,在一个叫做伯克利的地方,一个叫做Spark的组织建立并发展,号称一站式垃圾处理平台,妄图革了Hadoop和喜羊羊的命!
<hr/>2019年9月11日更新
第四章 Spark
十二时辰
&#34;不..不好啦,不好啦喜羊羊大人!!!&#34;
喜羊羊懒洋洋的从美羊羊身边起身:&#34;吵什么吵?什么事情大惊小怪&#34;
&#34;报告大人,据垃(数)圾(据)异常监控部门报告,今日午时左右一伙狼卫偷偷入城了! 明日可是杰杰马圣人,大宴万国的中元夜,可不能出任何差池呀!!!&#34;
喜羊羊大惊:&#34;快,快!联系storm部门,实时分析垃(数)圾(据),限你十二个时辰内找到这伙狼卫的位置!联系hive和mapreduce部门,分析出他们的目的&#34;
(storm 是一个分布式实时大数据处理系统)
&#34;好哒大人&#34;
手下退去,喜羊羊着急的来回踱步
&#34;这群可恶的狼,我不就杀了他们一点族人么&#34;
......
四个个时辰过后,喜羊羊还在踱步.
&#34;报告大人~&#34;
&#34;怎么样,狼卫抓到了没有?&#34;喜羊羊着急的问道.
&#34;还没有啊大人,storm吞吐量有限,无法实时处理全皇城的垃圾,这群狡猾的狼卫好像对我们比较了解,没有避开了我们监控的垃圾站点&#34;
(storm实时性高,但是吞吐量有限)
&#34;唉! 这群不争气的东西,那hive部门有没有分析出狼卫的目的呀?&#34;
&#34;报告大人,还在算! &#34;
&#34;怎么还没好?虽然我们比较懒散腐败,没有建立完善合理的垃圾仓库(数据仓库),导致MR任务需要算全城的垃(日)圾(志),这样比较慢,也不至于这么慢吧&#34;
(建立晚上的数据仓库,分层分表有助于提高数据查询效率)
&#34;大人,原来您心里有B树呀.原因是这群狡猾的狼卫昨晚在全城各处散播了很多脏垃圾(数据),数据挖掘部门的同学正建立新的模型,清洗垃圾(数据),算出他们真正的目的&#34;
(脏数据会影响数据分析与数据挖掘建模)
&#34;快去快去,对话这么多读者看的很累的&#34;
......
十个时辰过后,喜羊羊还在踱步.
&#34;报告大人~&#34;
&#34;怎么样,狼卫抓到了没有?&#34;喜羊羊着急的问道.
&#34;找到了大人,狼卫们,在花萼相辉!和杰杰马圣人在一起,圣人令您马上召见&#34;
喜羊羊脸青一阵白一阵:&#34;快!备马&#34;
--- 花萼相辉楼.---
万国朝拜,开过大帝,杰杰马一世.
喜羊羊拜见,看到杰杰马身旁之人后,大惊:&#34;啊! 似他,似他,似他,就似他!&#34;&#34;
&#34;我们的朋友,小哪吒?&#34;
(哪吒:你个瓜皮,怎么抠能是我呐)
喜羊羊咬牙切齿的说道:&#34;他就是Spark的首领狼王--------灰!太!狼!&#34;
(duang~ duang~ duang~ spark 登场)
灰太狼的眼神冷冷的看着喜羊羊.心中叹到:&#34;我儿小灰灰,今日就是你大仇得报之日&#34;
杰杰马咳嗽了一声:&#34;喜羊羊,听说今日有一伙刺客进了皇城想要行刺朕,你可查明?&#34;
喜羊羊背上一身冷汗,还未开口,杰杰马接着说道:&#34;不用回答我也知道,整整一天,你们一无所获.我身边这位是从遥远的伯克利投奔而来的Spark首领灰太狼同学,他们的spark streaming进行实时垃圾处理,吞吐量巨大,全城的垃圾都可以实时监控,比你们的strom高到不知哪里去了&#34;
(spark streaming 微批次准实时处理数据吞吐量巨大,应用于很多的实时数据统计场景)
喜羊羊张口无言,还想说什么.
杰杰马接着到:&#34;你想说你们的MR离线处理吗?哼!朕给了你们一下午时间,什么都没有算出来,看看人家Spark,计算速度比你们快多了,而且可以处理的垃圾量也不比你们少,而且在清洗刺客留下的脏垃圾(脏数据)上,进行多次迭代运算,更是你们快的多,灰太狼爱卿告诉朕,他们是基于内存..啊,DAG有向无环图还有什么RDD的反正朕也不懂,朕只看结果,如果没有灰太狼,今日朕被刺客暗杀了都不知道!&#34;
(Spark core相比与MR,计算速度更快,特别是迭代运算,提供众多算子和支持多种语言,通用性上也更好,基于的RDD数据模型可以在不存储中间结果数据的情况下容错等优势)
&#34;可是!圣人!&#34;喜羊羊刚想说这伙狼卫很有可能就是和灰太狼一伙的,但是又苦于没有证据,哑口无言.
杰杰马道:&#34;你是说你们部门有hdfs,yarn,hive这些吗?灰太狼爱卿已经告诉朕了,他们的spark团队可以和你们这些部门完美配合,如果他们死忠于你,灰太狼爱卿也从伯克利带来了mesos,,tachyon,spark sql等替代品&#34;
(伯克利数据栈也有分布式存储系统和资源管理系统,不过目前很多公司选择yarn,hdfs,hive和spark结合)
喜羊羊脸色雪白,&#34;不!hbase,Cassandra,redis他们这些nosql呢?&#34;
(spark可以很方便的读写各种nosql)
&#34;他们不来也不是你们hadoop专属,他们表示很乐意和spark合作&#34;
&#34;还有我新招募的kafka,rabbitmq呢?&#34;
(消息队列也支持)
&#34;哼!&#34; 杰杰马只回答了一个字.接着说道 &#34;之前一直听说你不在乎zookeeper,今天算是见识到了&#34;.
(之前忘说zk了,这次补上zookeeper是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的)
&#34;喜羊羊,你任人唯亲,贪污腐败,骄奢淫逸,不思进取,尸位素餐!你可知罪&#34;
&#34;呃,圣人你怎么突然会那么多成语了&#34;
&#34;少废话,把喜羊羊压入天牢,三司会审!&#34;
&#34;圣人,不要啊圣人,雅蠛蝶,饶命呀&#34;
杰杰马面无表情看着喜羊羊被拖下去,显然内心早就不满各种吐槽hadoop家族了.然后笑眯眯的转向灰太狼
&#34;灰太狼爱卿,我们淘淘帝国的大垃圾处理确实要技术升级了,你们spark和伯克利数据栈的其他同学们就接手喜羊羊下的各个部门吧&#34;
&#34;臣领旨,定不负皇恩&#34;
众人高呼万岁
&#34;圣人万岁,圣人英明,青青草原,淘淘千秋~&#34;
--- 天牢.---
喜羊羊目光呆滞,心如死灰.
这时,一个声音从暗中传来:&#34;喜羊羊,你想打败灰太狼吗&#34;
&#34;想!&#34;喜羊羊脱口而出&#34;你是谁???&#34;
&#34;嘎嘎嘎嘎嘎~ 我是谁?我比spark还大一岁,但是他们总说spark比我成熟,我知道我迟早有一天会取代他,你说我是谁?&#34;
喜羊羊吃鲸到:&#34;难道你就是&#34;
&#34;Flink!&#34;
第五章 Flink
<hr/>转载请署名,图侵删 |



