自然语言处理(NLP)和自然语言生产(NLG)
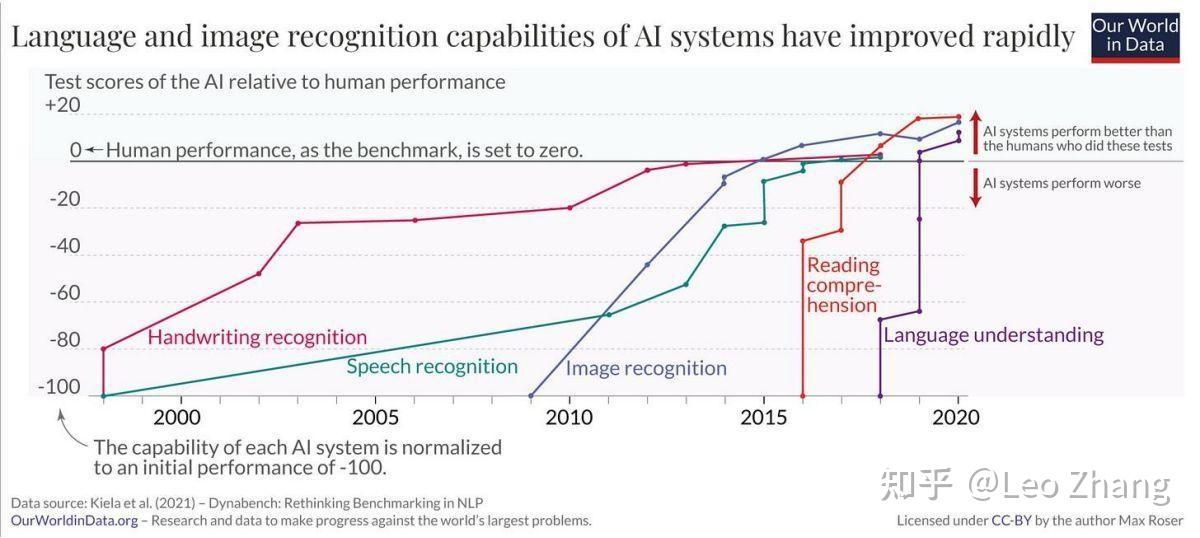
下图代表了人工智能在多个领域的达到的最高水平(和人相比)。阅读理解和语言理解都术语NLP的领域,接下来的是ChatGPT的横冲出世,引领对了对话系统的发展。
如下图所示,其中在语言理解这个领域的的影响主要源于基础模型的结果。 "语言理解 "这一术语需要和上下文联系起来,因为它并不是通常人类理解的语言理解。大语言模型(LLMs)在文本中寻找模式;他们真的不把每个单词和它们的意义直接映射。这可能会导致偏离真实意思的输出和严重的误解。
NLP任务收敛到两种不同的预训练模型框架
1. 自然语言理解任务 -- BERT+Fine-tuning
2. 自然语言生产任务 -- GPT + Prompt
3. 未来的趋势是两种任务逐渐 -- GPT + Prompt 统一 -- InstructGPT -- 通用人工智能(AGI)
其中包括BERT、DALL-E、GPT-3、LaMDA和其他一系列被称为生成式AI的大模型。可以从下面这张由Jaime Sevilla及其同事绘制的图中快速了解到Transformer模型的 "大规模时代"。它在2016年左右开始,计算机的性能达到了前所未有的水平,以每秒浮点运算(FLOPs)来量化。近60年来,摩尔定律的特点是训练计算量每18-24个月翻一番,而现在,在“基础模型”时代,每6个月翻一番。

截至2022年,所使用的训练计算逐级上升,谷歌的PaLM有25亿petaFLOPs,Minerva有27亿peta FLOPS。PaLM使用5400亿个参数,即应用于程序内不同计算的系数。2018年创建的BERT "只有 "1.1亿个参数,这让你感觉到了指数级的增长,从下面的对数图中可以很好地看出 。 2023年,有的模型是1万倍的,有超过1万亿个参数,还有一家英国公司Graphcore渴望建立一个运行超过500万亿参数的模型。

人工智能在医学领域的进展
接下来是医学人工智能在测试其与医生的表现方面迈出的一大步。上个月公布了美国医学执照考试(USMLE)的PaLM基础模型能力,并对其他几个医学问题的回答进行了评估,包括消费者健康问题。
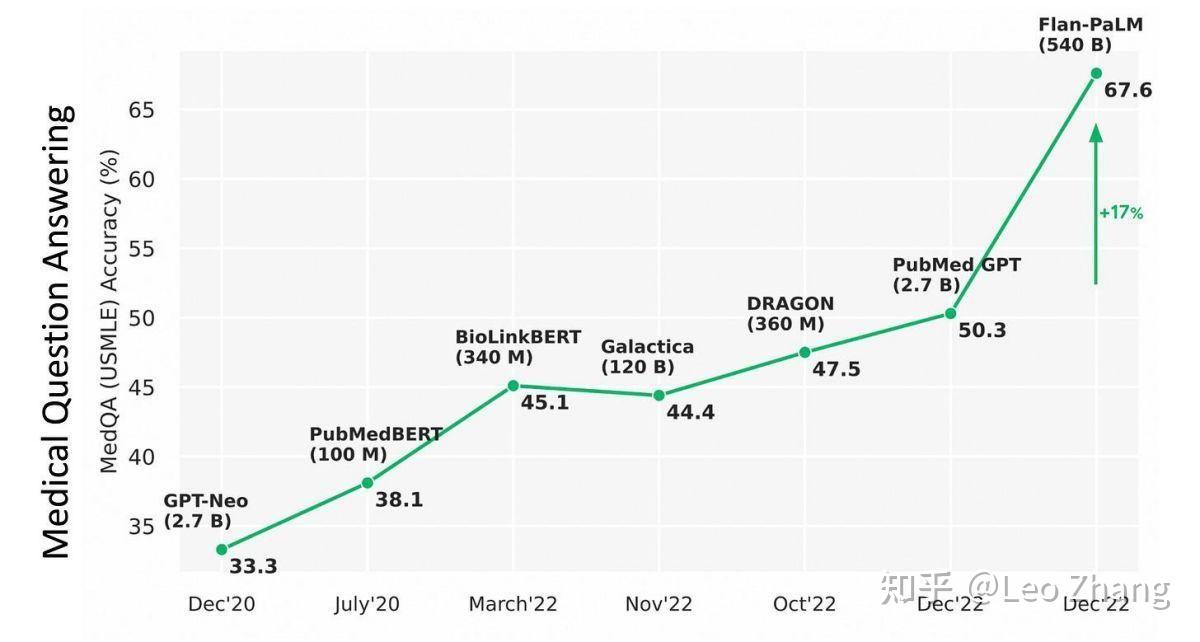
从上面的图表中,你可以看到PaLM的准确率从50%飙升到67.6%,绝对跃升了17%(相对增长了33%)。重要的是,在部分医学问题的回答中,MED-PaLM聊天机器人的正确率是92.6%,而其他医生的正确率为92.9%,这表明了AI已经接近人类医生。此外,对于答案的潜在危害,两者只有很小的差距:Med-PaLM可能的危害程度为5.9%,临床医生为5.7%;危害的可能性分别为2.3%和1.3%。来自谷歌和Deep Mind的作者总结说。"由此产生的模型,Med-PaLM,表现令人鼓舞,但仍然不如临床医生的表现。我们表明,理解力、知识回忆和医学推理随着模型规模和指令提示的调整而改善,这表明LLM在医学中的潜在效用"。
值得注意的是,MED-PALM的研究结果也在ChatGPT在USMLE的所有3个考试部分得到了复现。
GhatGPT在医疗领域NLP的测试可以见我写的另一篇问诊
Leo Zhang:ChatGPT的进化——ChatGPT在医疗健康NLP任务中的测试对比 |