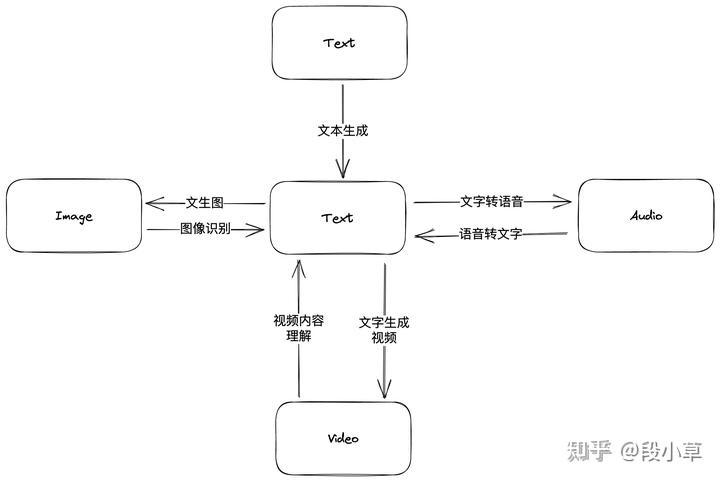
ChatGPT的又一次重大更新,炸裂程度堪比当初推出的插件功能。
更新的功能并不复杂,就两点:
- 能听能说(语音支持)。仅支持移动端(iOS和安卓)。
- 能看(图像支持)。支持全平台。
两个功能预计未来两周内推出,仅向ChatGPT Plus用户开放。(预计又要迎来一波订阅量高峰了)
语音支持
严格来说,此前的 ChatGPT 在移动端也是支持语音的,用过的知友应该都体验过APP上的语音输入功能。
但是之前的ChatGPT是只能“听”(语音转文本),不能“说”(文本转语音,TTS),只有耳朵没有嘴。
而这次更新让ChatGPT既能听又能说,官方的叫法是“back-and-forth conversation”(来回对话),让用户能跟ChatGPT进行语音交谈。
由“一去”变成“一去一回”,这差别可大了。应用场景会多很多,比如,
1、口语老师。把ChatGPT当英语口语老师,跟它进行对话练习,简直是想锻炼口语的同学的福音。
其实之前ChatGPT刚出来的时候,就有人这么干过,但需要安装浏览器插件,进行语音-文字和文字-语音的转换,由于不是官方支持的,所以像识别质量和发音效果这些是没法保证的。
而根据OpenAI的介绍,ChatGPT更新后,将由一个全新的文本转语音(TTS)模型提供语音功能支持,它能够仅从文本和几秒钟的样本语音中生成类似人类的音频,结合Whisper模型的语音转文本,一同保证用户与ChatGPT进行语音交流的质量和流畅度。The new voice capability is powered by a new text-to-speech model, capable of generating human-like audio from just text and a few seconds of sample speech. We collaborated with professional voice actors to create each of the voices. We also use Whisper, our open-source speech recognition system, to transcribe your spoken words into text.
新的语音功能由新的文本转语音模型提供支持,能够仅从文本和几秒钟的样本语音中生成类似人类的音频。我们与专业配音演员合作创作了每一个声音。我们还使用我们的开源语音识别系统 Whisper 将您的口语转录为文本。
以及可能很快又有一批第三方插件没有活路了。
2、语音客服/智能机器人。
以ChatGPT对自然语言的理解能力,当一个客服绰绰有余,现在有了语音支持,文本-语音、语音-文本随意转换,还能可以变换、模仿更多人声,充当个语音客服或者导购机器人之类的将是绝杀。
当初的“人工”智能可以变成真正的“人工智能”了。
“人工”智能
图像支持
OpenAI 在技术报告中透露 GPT-4V 模型在2022年就已经完成训练了[1]。

而支持多模态的GPT-4也早在今年3月就发布了,只是图像功能一直没有开放给ChatGPT用户使用,到底是因为算力不足,还是总体效果不理想,亦或是其他什么原因就不得而知了。
但是现在“图像输入”终于来了。
在这几个月的时间里,已经有不少公司率先把图像功能加入到自家的Chatbot产品中了,比如谷歌的Bard,百度的文心等。
所以现在这个时间点来看,功能本身已经并不新鲜,重要的是实际效果,以及到底能不能覆盖更多的应用场景。
看了OpenAI的演示之后,还是被惊艳了一下。
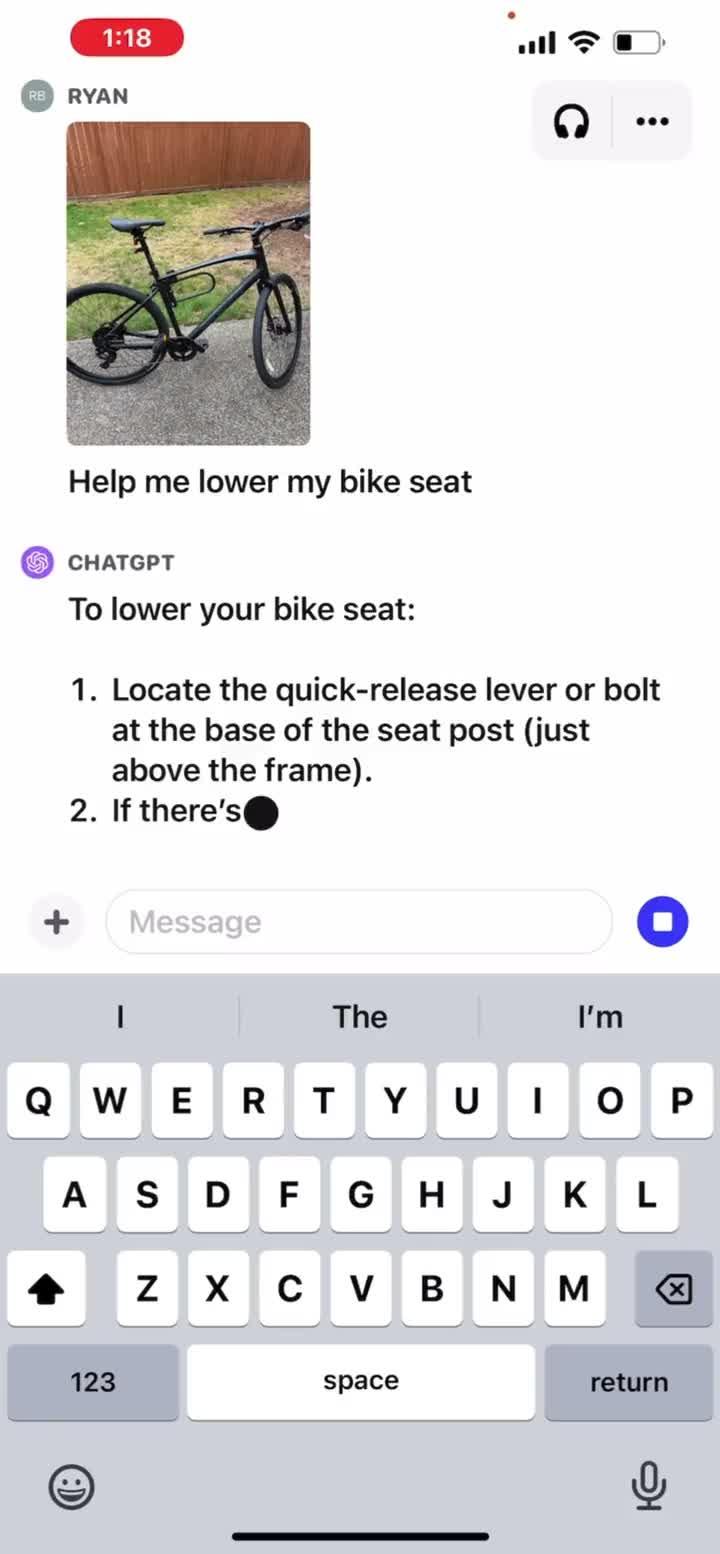
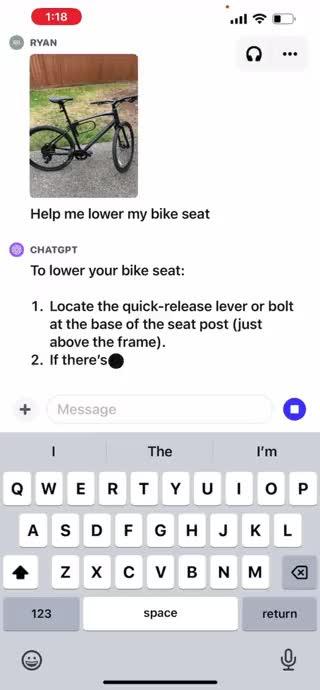
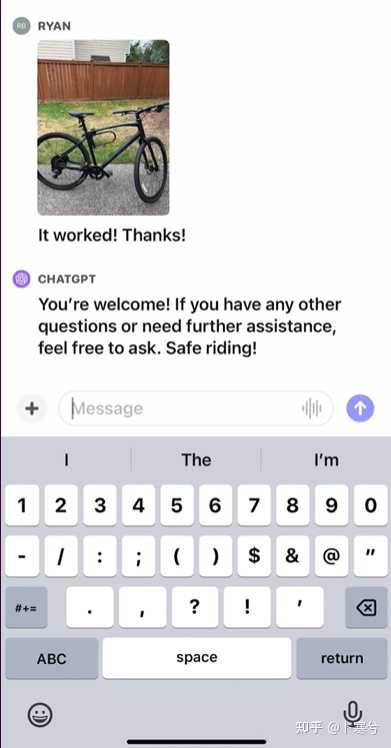
ChatGPT手把手教你修自行车
先拍一张山地车的照片;

问ChatGPT如何把车座调低。
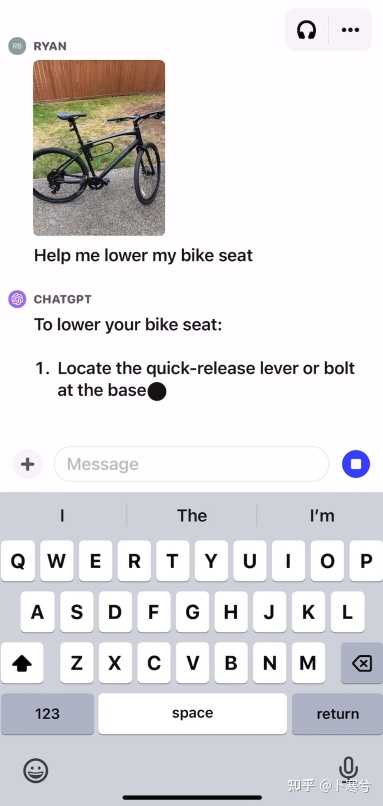
ChatGPT根据输入的图像和问题给出解决步骤。

不太确定操作步骤,给一张特写图。
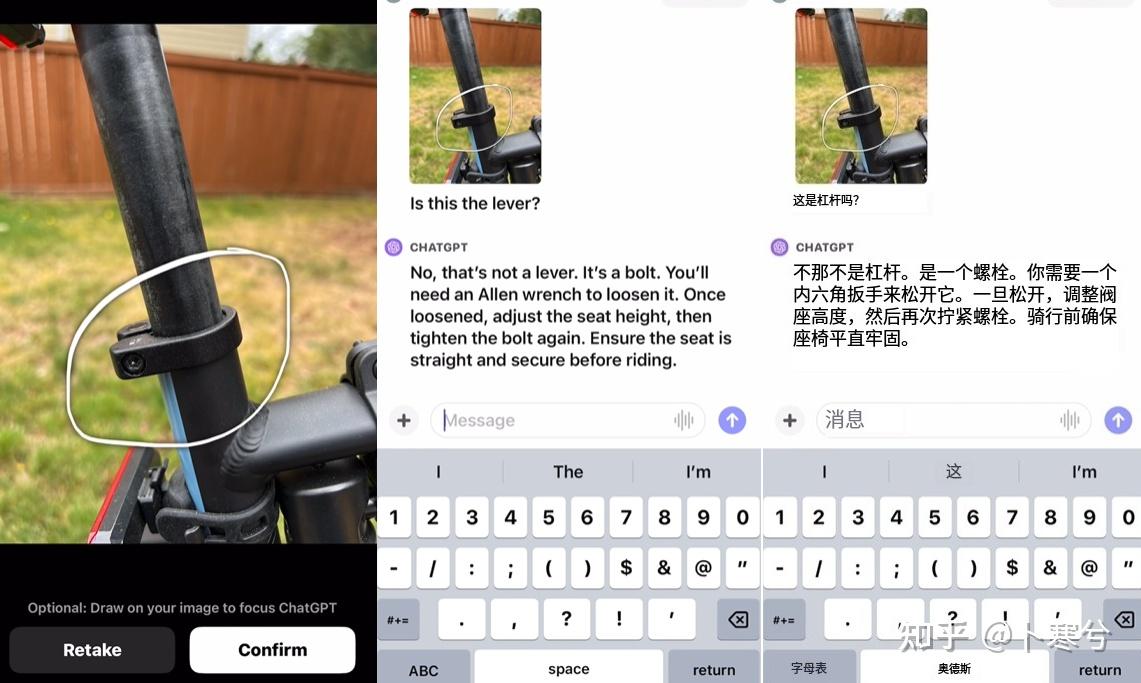
内六角螺栓也能识别并理解其功能。
接下来再把说明书和工具箱拍给ChatGPT,询问它是否有合适的工具。
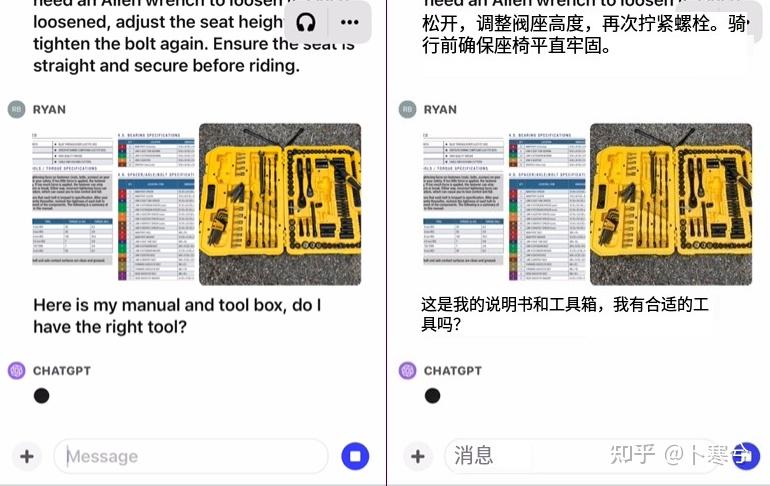
ChatGPT的回答。
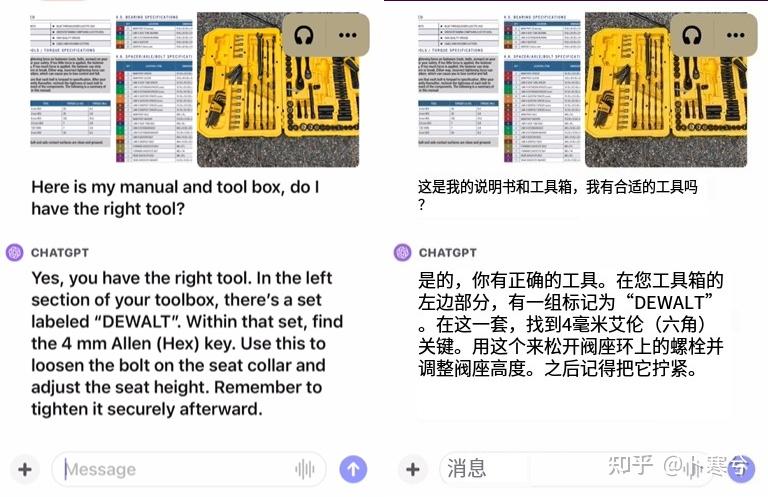
最后,在ChatGPT的指导下,“手残党”成功调低自行车车座。
说实话,这个演示给中ChatGPT的图片理解能力着实有些夸张了。也难怪网友们都表示很惊叹。
ChatGPT 完全体还有多远?
ChatGPT自从被推出就被当作人工智能(至少在LLM领域)产品的天花板,所以每一次更新都能引起很多人的关注。
今年伴随着类ChatGPT等AIGC产品的诞生,让人们看到了大模型的能力。
大模型因此也被认为是最有可能实现通用人工智能(AGI)的途径。
而大模型的佼佼者OpenAI/ChatGPT自然也被寄予厚望和最多的关注。
之前发布ChatGPT的插件功能,被认为是ChatGPT通向人工智能的重要一步。
OpenAI给ChatGPT的发展路线就像照着AGI这样的完全体不断拼凑,每次重大更新就是在拼图上增加一块。
如果把通用人工智能比作现实世界中的“三维生物”,那么只能处理文本这单一模态信息ChatGPT可算作“一维生物”,而此次更新后的ChatGPT则进化到能处理文本、语音、图像的“二维生物”。
距离AGI还差环境感知、自主决策等具身智能的属性和功能。
这个距离到底有多远还未可知,但是每一次进化,都让我们离AGI更近一步。
我很好奇在说、听、看之后,接下来 OpenAI 还会赋予 ChatGPT 什么能力。 |