从2011年Siri诞生以来,语音智能助手在智能手机上出现,已经有了十多年的历史。但直到今天,此类智能助手产品依然被诟病为“人工智障”——不同厂家的产品有好有坏,但通常都难以让消费者满意。
具体而言,很多情况下消费者期望的是智能助手能准确地理解自己提出的问题,给出对应的回答或者执行正确的命令。但实际上,目前的智能助手只能对一部分预设的场景进行响应,大多数情况下依然只能回落到互联网搜索返回结果的情况——显然这远不是用户想要的。
尽管随着AI技术的发展,业界的语音识别和自然语言处理能力都有了很大的提升,但依然远无法满足用户对于真正智能的智能助手的期待。而近年来,随着大模型技术的出现,手机的智能助手终于获得了摆脱“人工智障”处境的希望和契机。
现阶段,以GPT家族为代表的业界一流大模型,已经展现出了优秀的性能与潜力——大模型不仅可以依靠自身的知识储备(例如ChatGPT)或者外部检索信息(例如New Bing)对用户提出的问题给出流畅且基本准确的回答,而且还可以成为优秀的AI智能体(Agent),借助第三方工具解决依靠自身难以解决的问题。
目前ChatGPT已经开放第三方插件,而学术界基于开源模型的tool learning研究也取得了一系列成果。尽管目前大模型距离完美依然有很远的距离,仍然要面对诸如计算代价高昂,幻觉问题难以充分克服之类的缺陷,但目前的大模型已经具备了非常充分的可用性,可以在很多场景发挥足够大的作用。
目前大模型行业有一个明显的发展趋势——那就是基于全能通用的基座大模型,发展服务于各个具体方向,专精某一个细分行业的垂类大模型。显然,手机智能助手天生就是一个垂类大模型的优秀舞台。
站在手机助手的角度,目前语音到文本的ASR技术已经基本上发展成熟,主要的瓶颈就在于如何更加智能更加有效地让模型回答问题和执行命令——大模型(哪怕是体量小一点的大模型)显然可以很完美地解决这些问题。站在大模型的角度,具体到手机这一场景,许多通用场景下需要解决的问题自然就不是问题了。用户对于手机助手的需求方向相对单一,绝大多数需求都可以归类到内容问答、闲聊和工具调用(例如日程管理、购物买票等)这几个典型场景之中,任务难度也相对比较简单,诸如代码生成之类的通用大模型较高难度任务,在手机场景显然是完全不需要考虑的。
当然,手机场景给大模型带来的并不全是机遇,同样也有挑战——作为典型的C端消费产品,市场上主流的品牌都具有数以千万甚至亿级的用户总量,其中哪怕只有1%的用户使用大模型产品,都会带来极其可观的访问量,进而带来巨大的计算压力。
以当前的硬件技术水平,即使是OpenAI也做不到足额足量敞开向用户提供访问——GPT-4到今天依然限制只能付费用户使用,且每3小时只有50次提问机会(不久之前的限制更加严格,3小时仅有25次提问机会)。而且,由于应用场景的特点,手机上的智能助手不可避免地需要使用到手机中储存的用户个人信息,这些隐私信息显然不能随意上传给云端的大模型。
既然云不可靠,那么全程部署到端侧可以吗?显然也不是那么可行——当前手机芯片能够提供的AI算力仍然有限,即使是开源模型中尺寸较小的7B模型,想要在手机上达到可用的推理性能也依然要面临非常大的挑战。这还仅仅是考虑了推理速度——实际上如果对7B模型进行进一步的推断优化,很可能需要牺牲原本就不充裕的模型性能,严重的情况下甚至可能导致模型无法有效完成任务,满足用户需求。
除了性能问题之外,内容安全问题同样是大模型在手机场景应用中的挑战——基于监管要求,大模型服务的提供者必须尽可能确保大模型不会输出有害内容,避免给用户带来潜在损害。对于云侧提供服务的大模型而言,内容安全问题相对容易解决——即使是无法完全从模型的源头避免有害内容输出,也可以通过输出端的附加手段(例如单独的内容审核策略)阻断有害内容输出。但显然端侧大模型不能这么做——无论是隐私问题还是计算代价问题,把输出送到云侧审核都是不可接受的。
由此可见,未来大模型与手机的结合,仍然有很长的路要走——端侧与云侧不同尺寸模型之间的协同配合,将成为大模型在手机这一舞台上施展拳脚的必由之路。
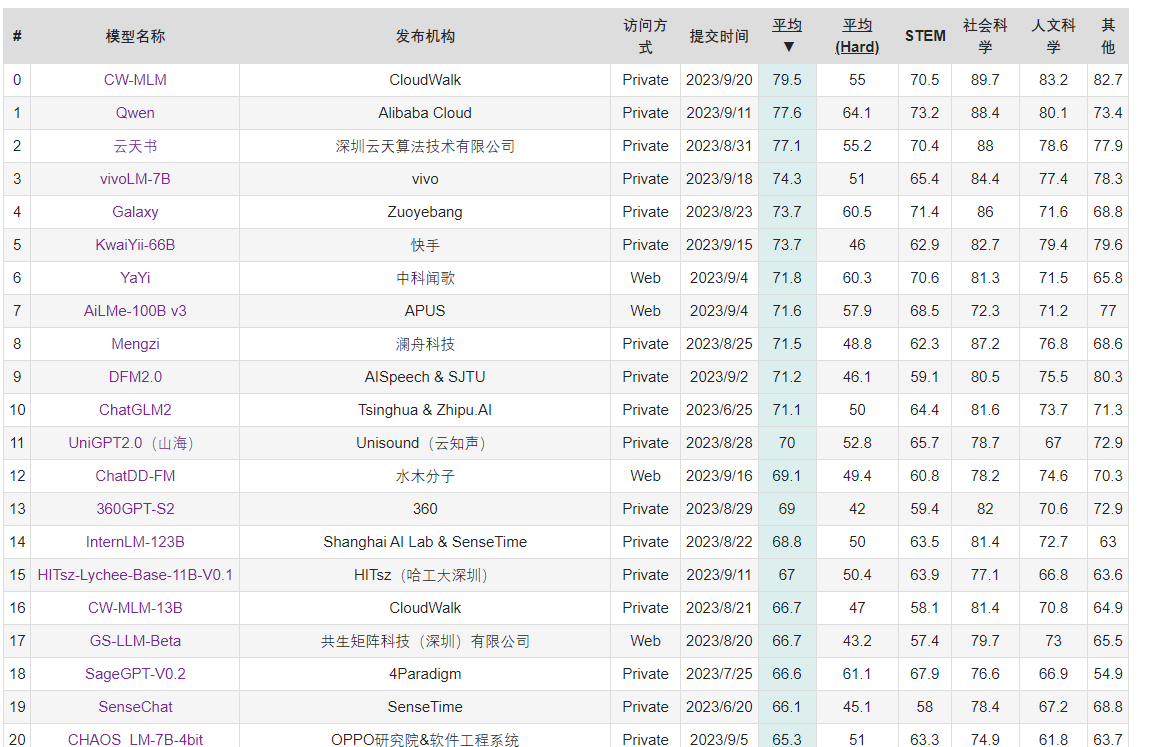
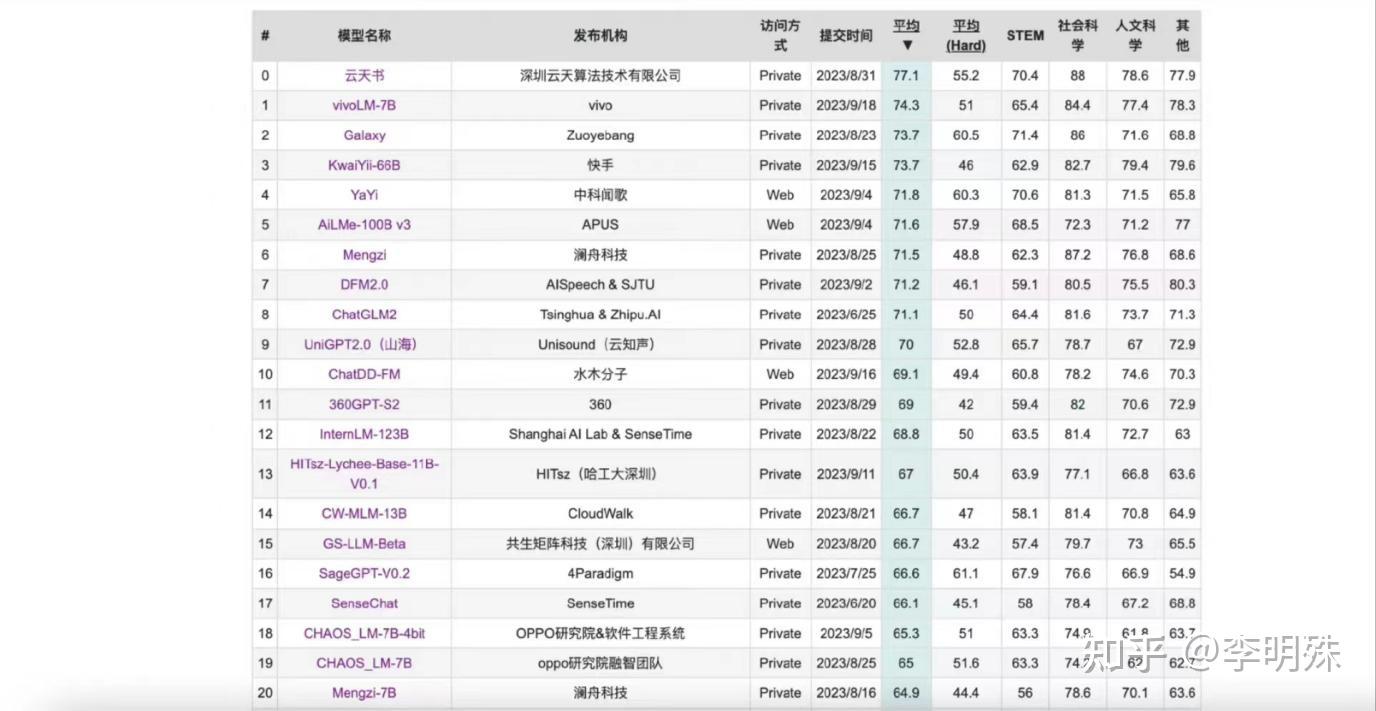
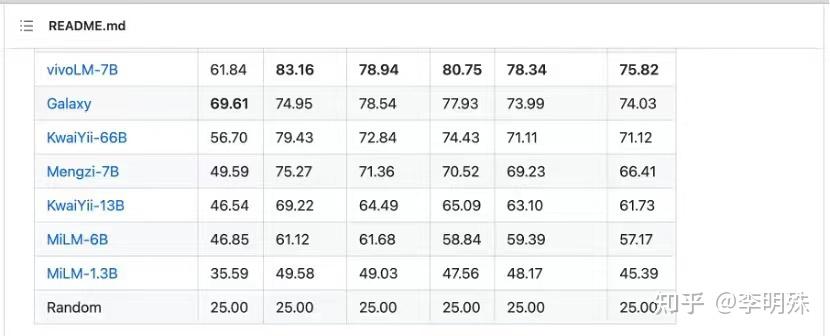
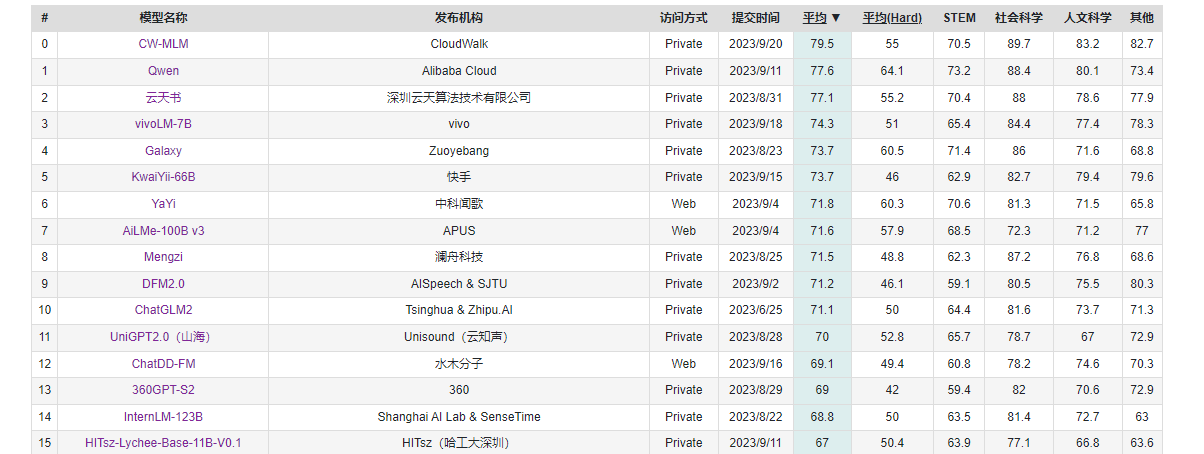
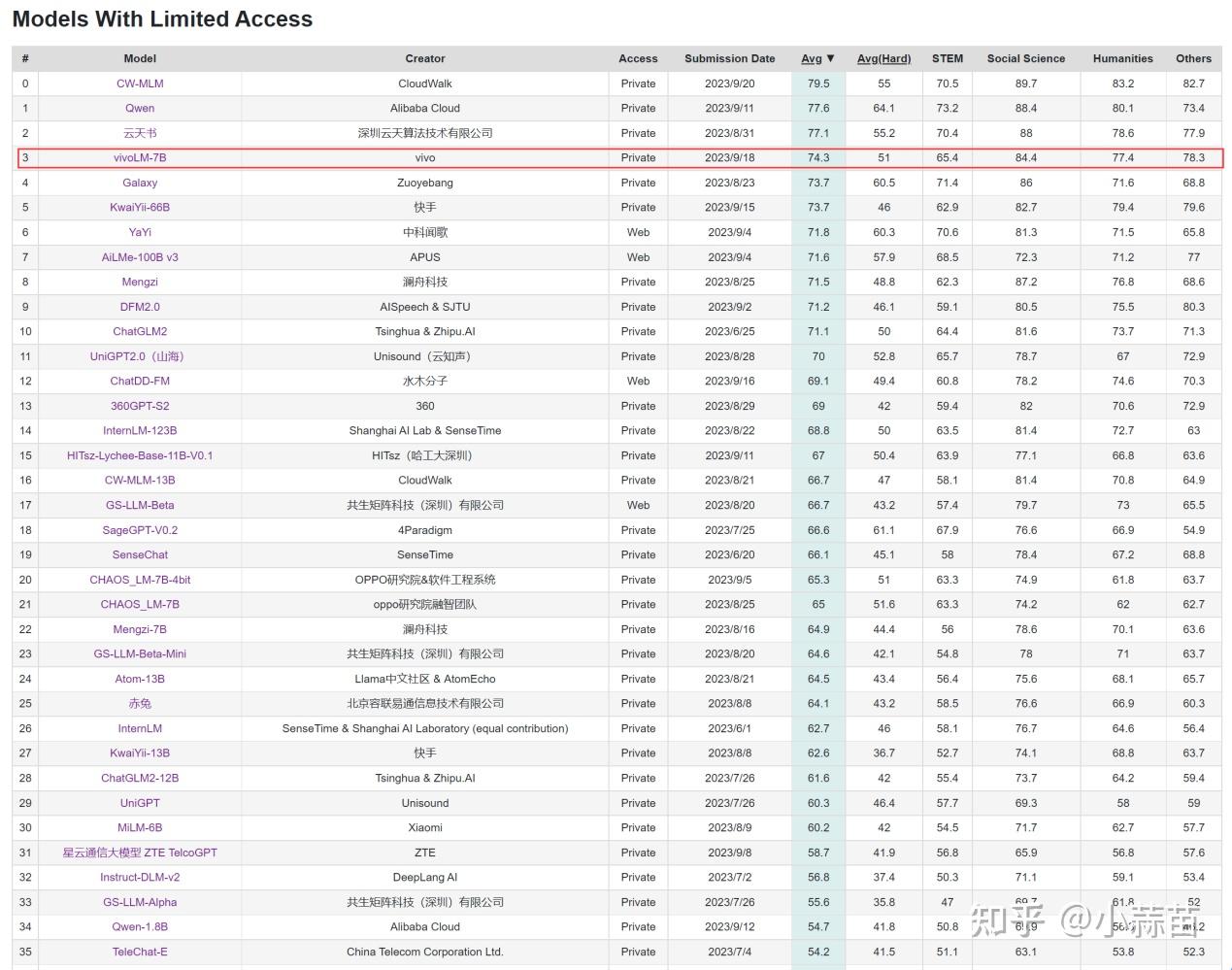
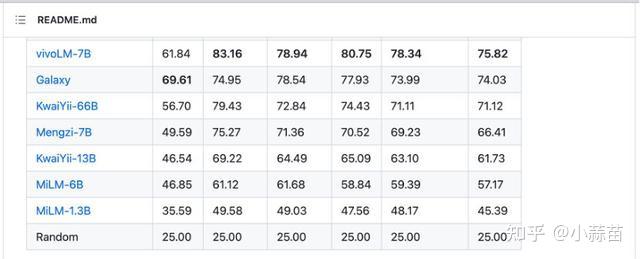
2023 年 9 月,在博鳌亚洲论坛国际科技与创新论坛上,vivo称即将发布自研大模型——在C-Eval中文测试集上,可以看到vivoLM-7B模型的平均分为74.3分,提交时在非公开模型中排名第二(2023年9月18日结果,目前排名可能有变动),今后vivo可能会将这一7B模型开源。
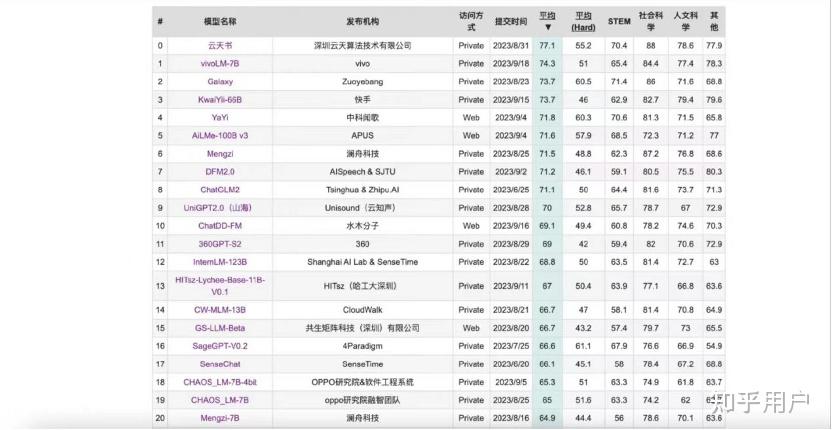
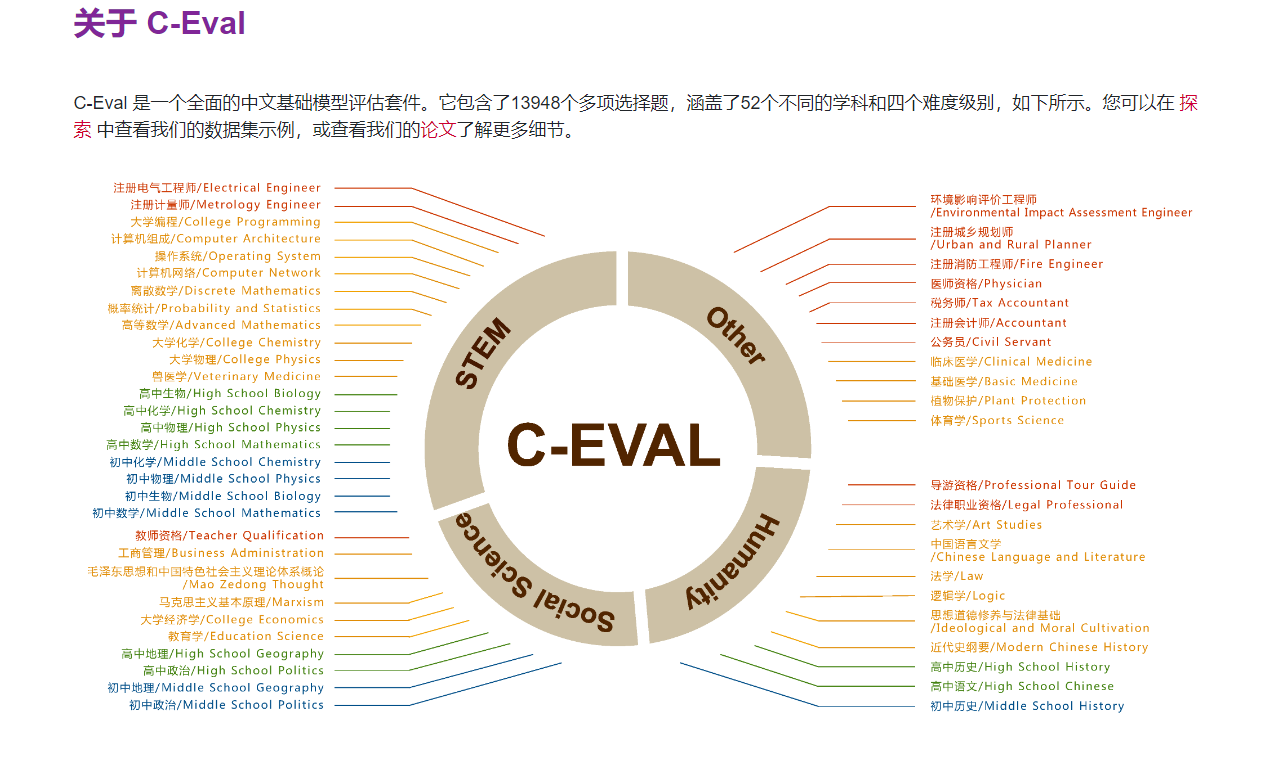
尽管目前的大模型评测手段仍然存在局限性,无法充分准确地全面反映通用基座模型的性能,但对于垂类模型而言,这样的性能已经足够证明其具有在具体细分垂类下的可用性潜力了。这个7B模型仅仅是一个开始——事实上vivo要发布的并非是一个单独的7B模型,而是一个涵盖多种不同尺寸的,完整的模型矩阵。
与目前已有的开源模型家族(例如著名的LLAMA系列)不同,vivo此次发布的模型矩阵,并非是对已有开源模型的简单模仿与迁移训练,而是针对手机行业的实际需求做了充分的调整。整个模型矩阵的尺寸既有最小的1B模型,也有业界主流的7B、66B模型,而最大的基座模型则直接达到了130B和175B(与GPT-3相同)。
基座大模型(尤其是千亿级大模型)的训练,不仅需要大量人力物力的投入,而且对于整个Pipeline的方方面面都有着极高的要求——数据清洗,资源调度,并行化计算,每一个步骤都需要极高的算法与工程能力支撑。如果技术实力不够强大,那么就算你财大气粗,有万卡级别的A100集群,那也依然会受困于垃圾数据和设备空转,无法真正训练出一个优秀的大模型(尤其是千亿级大模型)。vivo大模型矩阵的构成,本身就证明vivo在AI算法技术和工程能力方面,具备非常深厚的技术积累。
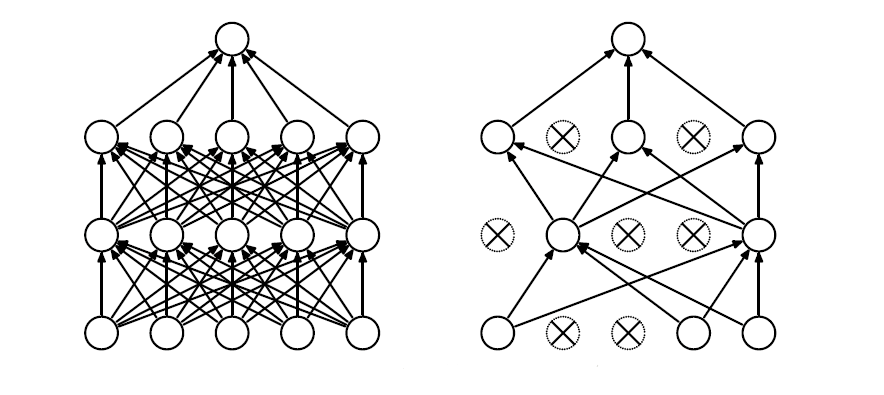
显然,这一不同于其他模型家族的体量矩阵,是针对手机智能助手这一需求做了充分适配的结果。7B甚至1B的“微型”模型,经过面向NPU的工程化之后,可以在手机上以较低的负载(200ma电流)长时间运行——此时大模型对手机的压力并不比一个音乐播放App更高,这就为大模型在手机场景的应用提供了基础和切入点。
不仅如此,vivo的AI团队还基于RLHF等方法,对模型进行了进一步的人工对齐与调优——直接将内容安全集成在模型内部,让端侧模型从源头避免有害内容的输出,自然就解决了端侧内容安全的问题。这一策略说起来容易,但要落地实现,却需要极高的技术能力。
当然,尺寸的缩小必然会带来性能的劣化——因此需要有更加强大的模型来协助端侧解决一些更加困难的问题,此时部署在云侧的66B模型就成为了端侧模型的强力助力。而千亿级参数的全尺寸大模型,则扮演了“教师”和“基座”的角色,以完整的全尺寸探索大模型的能力能够达到的上限,指引垂类大模型研发迭代。
得益于开源模型与框架相关生态的发展,目前大模型市场已经涌现出了很多大大小小的玩家,进入大模型市场的门槛已经比半年前低了很多。但尽管如此,基座大模型的从头训练依然有着极高的门槛——国内仅有少数企业具备基座大模型的训练能力,而能够进行千亿级的全尺寸大模型训练的玩家就更加稀少了。
可以预见,接下来OriginOS4将从系统底层集成大模型的能力,让大模型为用户体验的提升赋能。目前在手机系统中,除了常见的拍照和语音助手之外,同样也有其它的一系列基于AI的应用场景,而大模型能够赋能的远不止一个语音助手。举个简单的例子,手机输入法的联想功能实际上就是自然语言处理技术的一个典型的应用场景——此前的输入法只能通过用户之前的输入习惯给出一两个候选词的预测结果,而现在基于大模型,输入法可以直接基于用户的习惯和已经写过的内容,直接帮助用户续写内容,大幅提高工作效率。
无论是对于整个行业还是对于手机这一细分方向,“大模型到底能做什么”这个问题都还没有一个比较置信的答案。大模型到底有多大的潜力,能给实际的产品带来怎样的变化,仍然无从可知。但无论具体场景如何,有一点是确定无疑的——想要在这条道路上探索,必须具备坚实的技术积累。本次vivo展示的大模型矩阵,体现出了vivo在AI技术方面的惊人实力。期待vivo可以给出大模型赋能手机系统,提升用户体验的优秀答卷。 |