华为的工程能力太强了。
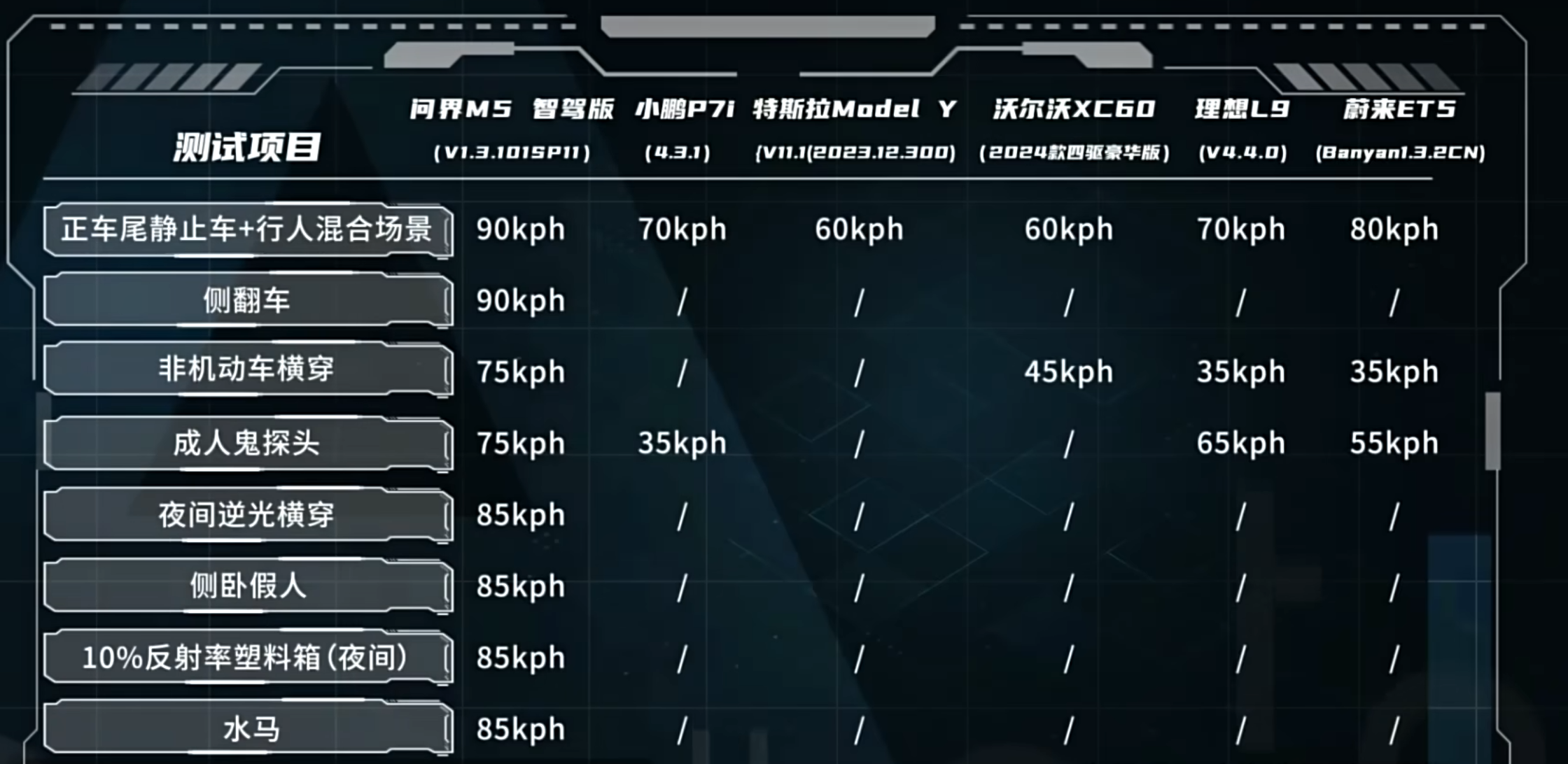
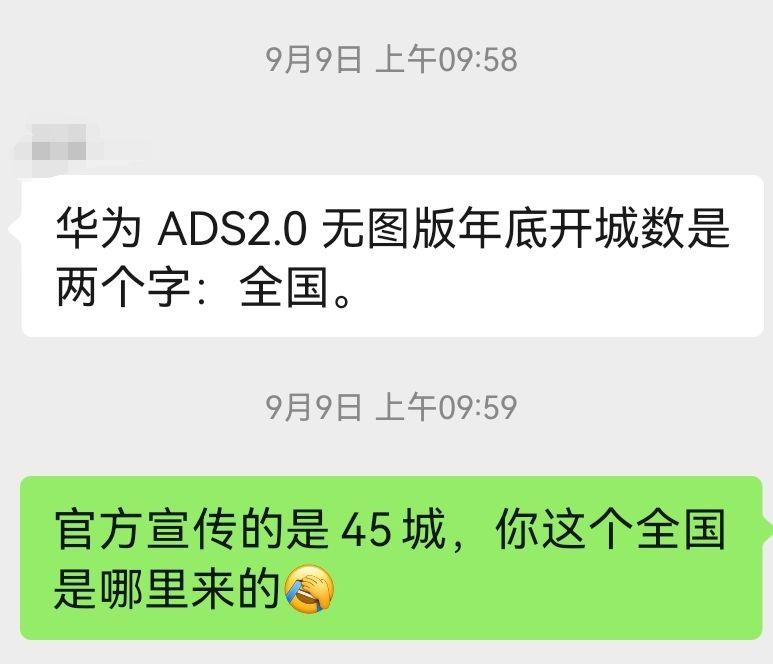
今年上半年,各家厂商都说要开图到40-50个城市,然而到了这个时间点,反倒都拿不出来。
结果华为在发布会上直接扔出来,告诉用户,智驾版今年底就能覆盖全国。

再来说华为的智驾技术。
从发布会的PPT上来看,也同样是基于BEV+Transformer算法,外加占用神经网络的。
但与特斯拉不同,华为的自动驾驶技术采用了激光雷达。
GOD基本就可以理解为占用神经网络的另一个叫法。

我简单解释一下占用神经网络,不太准确啊,但大概是这个意思。
传统的自动驾驶方案是给图像中每一个出现的物品拉框标注,辨别物体,优点是识别的比较准,缺点是不认识的识别不出来,当年特斯拉撞卡车一部分原因就是这个。
而占用神经网络就是告诉车,那有个东西占住了位置,不能撞,就光看理论也要安全得多。
特斯拉的纯视觉方案是通过摄像头的焦距判断的,泥萌都用过苹果手机上那个测距尺吧,特斯拉的原理是类似的,缺点就是需要大量算法和算力支持。
国内,尤其是华为的算法就比较简单粗暴,激光雷达探测到那有个东西,那就占上了呗,别去撞就好了。
当然,这背后涉及巨量的数据融合和计算问题。
比如激光雷达和摄像头的采样频率就不一样,怎么融合到一起?
但相较于华为,别家的软件能力和数据处理能力都要弱一些。

在之前的一篇报道中,我看到一个问题,即尽管目前路上跑了很多车,但大部分车企的数据处理能力还不够。一位业界专家告诉九章智驾:
目前,我们还没有看到哪家公司具备处理量产车上回传的大规模数据的能力。即使是某家在数据闭环层面做得比较前沿的造车新势力,即便是每辆量产车每天只回传5分钟的数据,他们也难以应对这样的数据量,因为当前的存储设备、文件读取系统、计算工具等都还无法应对极大的数据量。
看起来,各家公司手上都积累了不少真实数据,但真实数据用来做仿真,有个很严重的痛点是:复用性差。
——工程化与标准化。
此外,华为还有个优点,车型相对比较少。
对于其他车企,已经跑在路上的车型数量相对较多,每辆车的配置又存在差异。这种差异可能导致一辆车的数据在另一个型号上无法服用,甚至去年的车的数据到今年也不太好用。
特斯拉则是在车型的一致性商非常高,也因此为图像算法积累了大量的数据和优势。
但不管怎么说,华为从问界M5到现在,真正深度介入汽车生产也不过短短数年时间,而在这几年内,快速迭代更新自动驾驶算法和路线,年底就能实现全国都能跑。
这个工程能力,真的是,太™变态了。 |