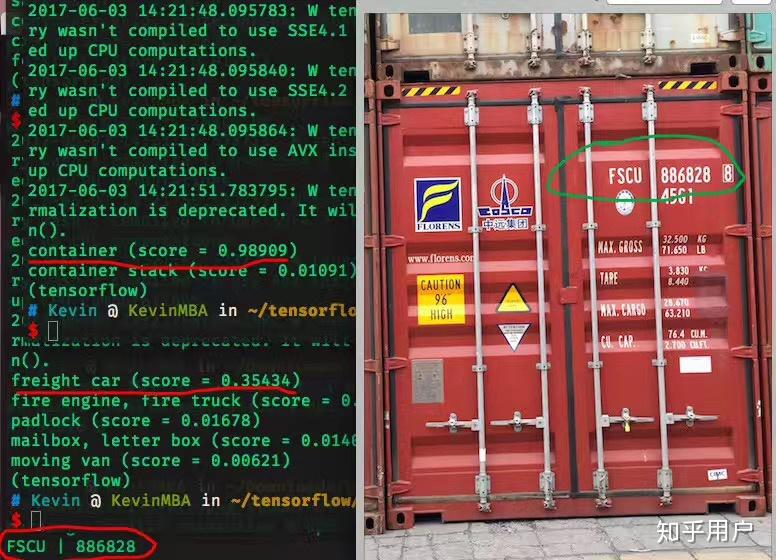
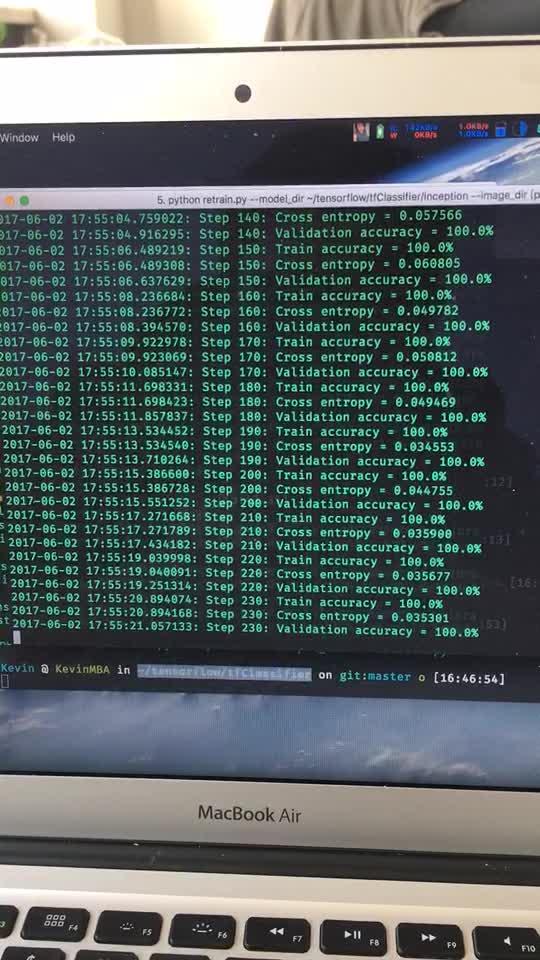
写在前面
从2018年10月中旬开始就进入了完全脱产的自学状态。直到写下这篇文章的时候为止已经整整半年多的时间,除开大约8周的假期时间,在剩下的24周时间里我从零基础开始完成了:
- 学习编程,主要掌握Python,跟着课程也学习了一些C、HTML、CSS、JavaScript;
- 学习了数据科学的理论和编程方法,如:Pandas, Numpy, Matplotlib等;
- 在线学习了四套关于Machine Learning和Deep Learning的课程。
现在已经能自己用框架写一些训练模型,读懂一些NLP方向前沿技术的文章,如:Transformer, BERT, GPT 等。
对于一个自学者来说现在真的是一个非常幸福的时代,在网上就可以免费学到各个名牌大学的精品课程,如果不是非要拿到那张文凭其实完全可以不用上大学了。但一路走来,由于缺少有经验的前辈指点,确实也走过不少弯路。所以,如果有人也想像我一样走上自学的道路,我希望我的经验能成为一个参考。
在这篇文章中我将会完整地介绍我真实的学习过程,并且根据学习效果总结出学习心得,希望能让像我一样的初学者少走一些弯路。
<hr/>从零开始学习Machine Learning全过程
首先我将按时间顺序介绍我在自学过程中的所有参考课程及资料。
不过在开始介绍之前我认为有几点需要先说明一下:
- 课程的心得是我作为一个初学者上完课以后整体感受总结的;
- 学习时间是按在完全不上班但周末仍然休假的情况下,一周5天,一天8~10小时来计算的,但也可能会同时在上几门课程;
- 初学者推荐度主要是根据课程的质量、课程的难度、学习的实用性等因素得出的,满分 5 颗 ⭐️;
- 许多课程都没有中文翻译,所以需要有一定的英语基础。
<hr/>1. 入门阶段(18年10月 - 12月)
这个阶段是比较盲目的,因为对这个专业领域的东西一无所知,也没有前辈可以指点迷津,所以基本上就是一个探路的阶段,也是踩坑最多的阶段。
Coursera: Machine Learning -- Andrew Ng
在一开始不知道哪个课程更好的时候,我干脆就选市面上最火的,也就是吴恩达教授在Coursera上的《机器学习》课程。这门课教授的是“传统”的机器学习理论,所谓传统其实也就是近年来在深度学习还没崛起的时代大家所用的机器学习理论和实践。课程比较重理论知识,而且课程里所使用的语言是比较冷门的Octave,所以其实入门门槛比较高以及后续的实用性不足,所以并不推荐初学者学习。
学习时间:约 6 周
初学推荐度:⭐️⭐️
CS50&#39;s Introduction to Computer Science -- David J. Malan
在艰难地学习《机器学习》课程的同时为了更全面地了解计算机科学知识以及编程技术,我选择了edX上这门非常有名的哈佛大学的CS50课程。课程的主讲老师 David 用非常生动的方式介绍了电脑运作的基本原理,简单易懂,相信上过这门课的人都会对计算机产生非常浓厚的兴趣。不过这门课好像只有英语和西班牙语版本,需要一定的语言基础。并且作业的难度也是非常大的,对于像我这种没有任何编程基础的人来说需要额外做非常多的功课才能独立完成。
学习时间:约 9 周
初学推荐度:⭐️⭐️
Python for Everybody -- Charles Severance
这门课是非常好的Python入门课程,课程时间不长,但基本把Python的基本知识都覆盖了。虽然在这个阶段的课程都基本没用到Python,但这是为了后面的学习打基础的,因为基本上Machine Learning领域的教学资料和主流框架都是使用Python的。
学习时间:约 4 周
初学推荐度:⭐️⭐️⭐️⭐️
这个阶段主要是大致了解Machine Learning的知识范围,以及所需的知识与技能。总结下来,要学习Machine Learning大致需要掌握:
- 基础线性代数运算(会矩阵乘法和转置已经能吃透大部分内容了)
- 基础微积分运算(会求导就可以了)
- 认识基本的数学符号(类似于Σ的符号能知道是累加的意思)
- 基础编程能力(为后面的学习打基础)
- 最后就是英语能力(大部分优质的学习资料都是英文的)
<hr/>2. 初学阶段(19年1月 - 4月)
经过了大约两个月时间的学习,已经大概了解了这个领域是怎么一回事儿了。接下来就要开始接触最新的专业方向了。深度学习,从大约1940开始就作为机器学习领域的一种算法被提出,但受阻于当时的计算能力以及数据量的不足这种算法一直都没有得到重视,直到最近几年得益于计算机技术的进步这种算法屡屡打破记录,尤其在 Alpha Go 击败 李世石 以后才真正崛起。
所以我们真正想要学习的其实是机器学习中的深度学习算法。
Coursera: Deep Learning -- Andrew Ng
与吴恩达教授的另一门课Machine Learning课程相比,这门课只讲授了Deep Learning的相关内容。尽管如此,知识量却一点也没有少,而且都是专业领域中比较新的,所以可以通过这门课来了解专业比较近期的发展状态。除此之外,这门课的作业都是用Python以及基于它的深度学习框架如TensorFlow来完成的,所以在对于技术的了解以及后续的实用性上都是非常不错的。虽然在已经上了一门Machine Learning后对这门课的内容还是比较好接受的,但对于完全的初学者来说还是有一定难度。
学习时间:约 6 周
初学推荐度:⭐️⭐️⭐️⭐️
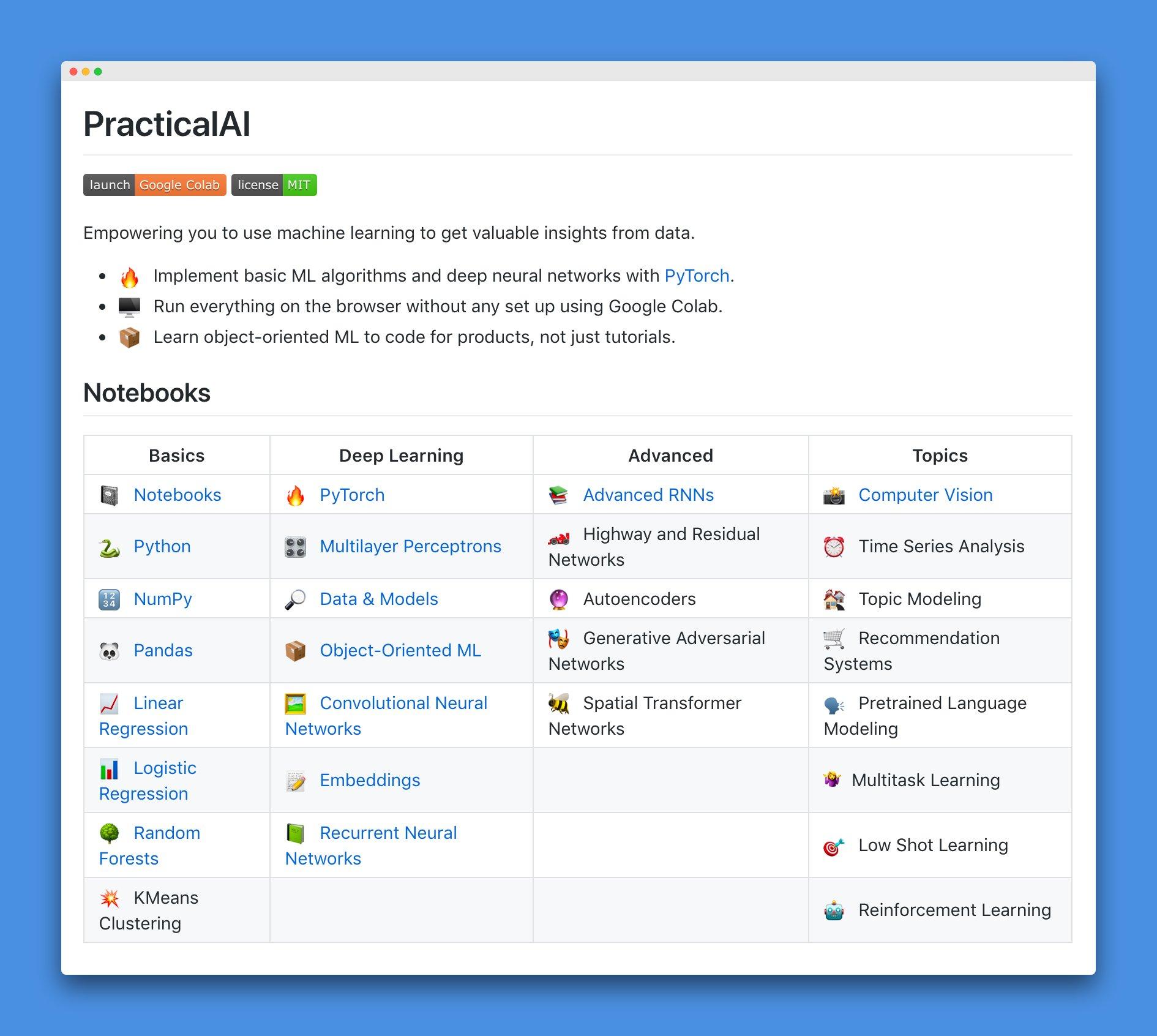
学完了吴恩达教授的课程以后虽然感觉对深度学习有了比较整体的认识,但还是觉得在实践能力上还比较欠缺。到底我学完了以后能做什么?心里还是没有一个比较清晰的答案。因此我又继续寻找其他课程,这次希望能找到一个更加注重实践的,幸运的是,让我找到了。 fast.ai: Introduction to Machine Learning for Coders -- Jeremy Howard
学了fast.ai的课程最深刻的感觉就是——相见恨晚,这不仅仅体现在学习机器学习的道路上,更是体现在学习这件事上。长久以来我们接受的都是传统的自下为上,也就是从基础知识到高级概念再到实践的教育。而在fast.ai的课程里,Jeremy Howard 提倡的是自上而下的学习方法,也就是回归到人最自然的学习方法。想想我们小时候是如何学习游戏、踢球、画画的,我们都是先按照自己的理解从模仿开始,随着对这样东西越来越熟悉再逐渐深入了解,学习如何把游戏玩得更好,研究踢球动作技巧,研究画画的笔法等等。在课程中,Jeremy 就是贯彻着这样的教学理念,从一开始就让大家先别管具体的原理,按照他所教的方法把机器学习的模型实现出来,让大家以最快的速度感受到这项技术的力量以及降低对它的恐惧感。
不得不说这样的方法非常合我胃口,而且效果也非常好。这门课主要介绍了 Jeremy 自己最常用的两种机器学习的方法,一种是针对规则数据的Random Forest,另一种就是针对大部分非规则数据的Deep Learning。虽然没有吴恩达教授讲解得那么全面,但深入浅出,让学习者很容易理解这项技术的主要作用和原理。
但这门课有一个门槛就是需要学习者最好有一年以上的编程经验,而且最好熟悉Python。不过,对于我这个只学了两个月而且还没有过开发经验的初学者来说感觉也基本能够理解所有实现的代码,但如果看源代码还是比较吃力。另外还有一点就是这门课目前好像对中文的支持还不够友好,不过国内也有热心的朋友在帮忙翻译,希望这么优秀的教材也能让国内的自学者们用起来。
学习时间:约 6 周
初学推荐度:⭐️⭐️⭐️⭐️⭐️
fast.ai: Practical Deep Learning for Coders -- Jeremy Howard
这门课才是fast.ai真正的重点课程,因为在这门课中Jeremy还介绍了他们专门为深度学习开发的一个库,利用这个库可以快速实现建模、导入数据以及训练模型。跟之前的课程一样,他还是采用的自上而下的教学方法,用最快的方式教会你使用他们的库,然后引导你用同样的方法去解决身边的问题。这门课还专门有个论坛让学习者们分享学习心得的,其中就有不少人在上过几堂课以后已经可以使用fast.ai框架训练出各种各样的模型,有的能根据卫星图分辨出图中的城市是属于哪个国家的,有的能根据植物的照片分辨出该植物是否患病,还有的能理解一些稀有语种的文字并自行造句。而这些都只需要上过三四堂课就能学会,上手难度非常低,让你在很短时间内就能领会到所谓的AI到底是什么、但同样的,这门课也是建议最好有一年以上编程经验。
学习时间:约 7 周
初学推荐度:⭐️⭐️⭐️⭐️⭐️
学完以上的课程以后基本上就能理解大部分的技术原理,接下来除了继续练习技术以外,还能根据自己的需要去学习更深层次的东西。
<hr/>3. 进阶阶段(19年5月 - 今)
深度学习也是有很多的研究方向的,而我选择的方向主要是自然语言处理(NLP)。这个方向在18年年末,随着Google Brain发布BERT预训练模型后,NLP领域迎来了近几年来最重大的突破,业内称这个突破就像当年ConvNet在计算机视觉领域的突破一样震撼。而且自然语言作为人与机器目前最主要的交互方式,无论在搜索、聊天、语音都会用到,这样的突破肯定会在不久的将来带来非常重要的价值。因此,深入理解这些技术背后的原理也是非常重要的,而要理解这些技术最好的方法就是看文献。
关于看文献最好的方法就是看别人重现文献方法的文章,这里只作简单推荐,因为我自己本身也还在消化这些内容。
The Illustrated Transformer -- Jay Alammar
这是一篇对Google Brain在18年上半年发布的非常重要的技术Transformer的解释文章。内容比起文献好懂很多,一点点仔细看完以后再重新看文献会感觉茅塞顿开。作者博客中还有对其他文献的解释文章,包括BERT。
The Annotated Transformer -- harvardnlp
harvardnlp是专门重现重要文献中提出的模型的博客,如果有耐心一行行代码地学习一定能对这些技术有更深入的理解。
<hr/>推荐学习路径
总结整个学习过程,主要踩的坑就是在理论上纠缠了太多时间而忽略了实践的重要性,所以如果你的目的也是想要快速地了解这个领域的话我会推荐以下学习路径。
1. 快速学习编程
编程是基础,但并不是说一定要学到可以找份工作才能学习Deep Learning。所以我建议在开始学习之前用最快的速度掌握基本的Python语法,达到能够写简单的程序的水平。当然除了Python本身,还需要花点时间学习Numpy、Pandas以及Matplotlib这类数据科学库的使用方法。在学习的过程中如果遇到什么问题,YouTube和Google是你最好的朋友(Bilibili和Baidu也勉强能用)。
2. 直接上手fast.ai
直接学习上面提到的fast.ai的两门课程,能够快速地让你从应用的角度理解Deep Learning的技术原理。先从整体上了解这项技术的功能,再深入理解技术内的原理是个不错的方法。
3. 加深概念理解
在对技术有个大致的理解后,如果想要进一步深入,可以学习吴恩达教授的Deep Learning,从基本概念开始深入学习。同时fast.ai也有一个进阶的课程讲解具体的概念原理,不过我也还没上过这个课不知道具体的效果怎么样。
4. 进阶深入理解
跟进行业最新动态,最好的办法就是读最新的有重要突破的文献,并且找最简单的方式实验技术的成果。比如BERT就是一个预训练模型,所谓“预训练”就是能够用他们训练出来的模型只作简单的“微调整”训练就可以直接用在多种语言任务上并且获得非常好的表现。所以利用预训练模型,我们自己就可以很轻松地训练出一个处理其他特殊任务的模型,而不需要花费大量资源和时间从头开始训练。
<hr/>写在最后
在最后我必须再讲讲一样与机器学习无关东西——英语。我的英语一直都是中等水平,大概6年前考过雅思6.5就基本上没怎么碰过英语了。但直到我开始自学之后才发现,读了这么多年书到头来最有用的还是英语。不得不说,外国人在分享知识这方面真的比我们要积极很多,很多人都乐意分享一些教学视频和文章,而且事无巨细都能找到教程。这都是非常值得利用起来的资源,所以学好英语就打开了另一扇门,能接触到更多的机会。
说了那么多,听起来好像很有经验一样,但其实我也仍然在学习。半年前我甚至对AI的理解都还是“能像人一样思考的机器”,充满了神秘,感觉遥不可及。但今天回想起来自己都觉得可笑,这一切不过是“数据科学”。知识才是力量,相信自己能学会并且坚持学下去,明天的你会感激今天的自己。
<hr/>此文转载自我的个人博客:
Machine Learning 从零开始 |