[1]. How Much Does ChatGPT Cost to Run? $700K/day, Per Analyst (businessinsider.com)
[2]. Reddit Wants to Get Paid for Helping to Teach Big A.I. Systems
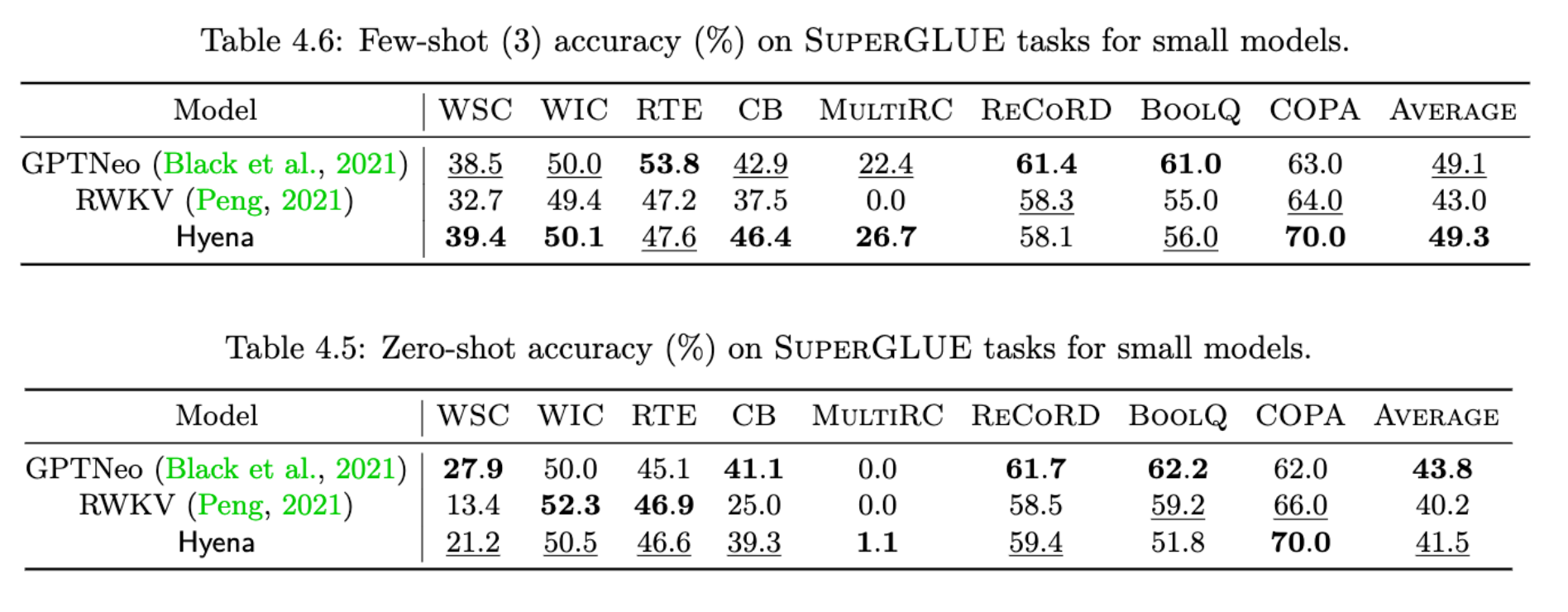
[3]. Hyena Hierarchy: Towards Larger Convolutional Language Models 论文
[4]. Hyena Hierarchy: Towards Larger Convolutional Language Models 博客
[5]. Microsoft reportedly working on its own AI chips that may rival Nvidia’s
Rahimi等人的“Extending Boundary Updating Approach for Constrained Multi-objective Optimization Problems”提出了一种隐式约束处理技术——边界更新法(BU)与显式约束处理技术相结合,从而显著提高有约束多目标优化算法的效果。
Colomine等人的“Epoch-based Application of Problem-Aware Operators in a Multiobjective Memetic Algorithm for Portfolio Optimization”提出了一种基于问题感知算子的多目标算法,并应用于投资组合优化问题中,取得了比其他算法更好的结果。
Lin等人的“AMTEA-based Multi-task Optimisation for Multi-objective Feature Selection in Classification”则提出了一种基于多任务优化的多目标特征选择算法,以提高多个相关分类任务的性能。
这些研究为解决现实中的多目标优化问题提供了新的思路和方法。
Multi-objective Feature Selection in Classification
Chen等人的“Multi-Objective Location-Aware Service Brokering in Multi-Cloud – A GPHH Approach with Transfer Learning”探讨了如何通过迁移学习来解决多云环境中的服务中介问题,并提出了一种基于遗传编程和迁移学习的方法。
Sarti等人的“Under the Hood of Transfer Learning for Deep Neuroevolution”研究了基于进化算法的迁移学习方法来优化深度神经网络的结构。
Babaagba和Ayodele的“Evolutionary based Transfer Learning Approach to Improving Classification of Metamorphic Malware”则提出了一种基于演化算法的迁移学习方法来改进恶意软件分类算法的方法。
Neri和Turner的“A Fitness Landscape Analysis Approach for Reinforcement Learning in the Control of the Coupled Inverted Pendulum Task”使用Fitness Landscape Analysis方法分析了强化学习算法在控制倒立摆任务中的表现,并发现探索能力对于在高崎度环境下实现最优强化学习具有重要作用。
Almansoori等人的“Further Investigations on the Characteristics of Neural Network Based Opinion Selection Mechanisms for Robotics Swarms”研究了基于神经网络的观点选择机制的特征,探讨了在机器人群体控制中应用这种机制的可行性和性能。
Montague等人的“A Quality-Diversity Approach to Evolving a Repertoire of Diverse Behaviour-Trees in Robot Swarms”使用质量多样性方法来进化多样化的行为树,以帮助机器人群体应对不同环境下的复杂任务。
José Ferreira等人的“A Self-Adaptive Approach to Exploit Topological Properties of Different GAs’ Crossover Operators”提出了一种自适应方法来利用不同遗传算法的交叉操作的拓扑特性,提高算法的性能。
Bryan Martins Lima等人的“Adaptive Batch Size CGP: Improving accuracy and runtime for CGP Logic Optimization flow”使用自适应批量大小的方法,提高了Cartesian遗传编程在逻辑优化任务上的准确性和运行时性能。
David Wittenberg和Franz Rothlauf的“Small Solutions for Real-World Symbolic Regression using Denoising Autoencoder Genetic Programming”使用去噪自编码器结合遗传编程来解决小样本符号回归问题。
Ting Hu等人的“Phenotype Search Trajectory Networks for Linear Genetic Programming”则探讨了一种基于搜索轨迹网络的线性遗传编程演化分析方法,探究线性遗传编程在解决符号回归问题上的表现。
Julia Reuter等人的“Graph Networks as Inductive Bias for Genetic Programming: Symbolic Models for Particle-Laden Flows”探讨了如何将图神经网络作为遗传编程中的归纳偏差来提高演化算法的性能,以解决Particle-Laden Flows问题。
Michał Kowalczykiewicz和Piotr Lipinski的“Grammatical Evolution with Code2Vec”介绍了一种新的演化计算方法,将机器学习中的Code2Vec技术与语法进化相结合,用于解决软件工程中的程序合成问题。
Zhou等人的“A Boosting Approach to Constructing an Ensemble Stack”提出了一种改进的集成学习方法,通过演化计算生成不同的基本分类器,然后使用Boosting技术将它们结合在一起,以提高分类器的性能。
Zhang等人的“MAP-Elites with Cosine-Similarity for Evolutionary Ensemble Learning”介绍了一种基于MAP-Elites算法和余弦相似度的演化集成学习方法。该方法利用MAP-Elites算法来维护多样性和保留精英个体,同时使用余弦相似度来评估个体的相似度,进而组合成一个更好的集成模型。
Matteo De Carlo等人的“Interacting Robots in a Artificial Evolutionary Ecosystem”探讨了在演化机器人领域中,通过设计一个交互生态系统来更自然地评估机器人,并发现这种评估方式对机器人的最终行为和形态有重要影响,同时仍然保持了相当的适应度性能。
Marko Đurasević等人的"To bias or not to bias: Probabilistic initialisation for evolving dispatching rules"介绍了一种使用初步演化调度规则的概率信息来提高遗传编程生成调度规则的收敛速度和质量的方法。
最近大火的AutoGPT备受关注,因为大家意识到给ChatGPT额外增加外部搜索能力,和反思记忆模式,就可以让他形成自动规划的agent。只需要给定最终目标,即可以完成全部的子任务分解,多步骤规划,任务结果评估等环节
其实AutoGPT属于Autonomous Language Agents (ALA),可以称为自主式语言agent。我觉得今年可以密切关注这一领域问题的进展,或许有更多意想不到的发现。
这是ReAct论文第一作者姚顺雨提出的概念。AutoGPT的思路其实可以上溯到论文 ReAct: Synergizing Reasoning and Acting in Language Models
在以往的扩展Language Models(LM)的工作中,一种是通过chain of thought (CoT) 去引导其进行多部推理完成复杂reasoning trace,但主要依赖模型内部知识。