巧了,最近我们在做的AI Agent(尤其是LLM-based AI Agent,即基于大型语言模型的人工智能代理)可能是题目中提到的“AI最新趋势”和“可能的创业方向”的共同答案(之一),而具体应用场景就有很多了,比如复杂任务自动化,情感陪伴机器人等。下面详细说一下。
什么是AI Agent:
其实到目前为止也没有明确的定义。我们在之前的论文中定义为(一个基于人工智能的程序,它能够完成需要人类智能的复杂任务):Artificial Intelligence Agent (AI Agent) is defined as a program that employs artificial intelligence techniques to perform tasks that typically require human-like intelligence. AI Agents can take many forms, from simple chatbots to complex autonomous systems that interact with their environment and make decisions in real time. They can be trained using a variety of machine learning techniques, including supervised, unsupervised, and reinforcement learning, and can be programmed to perform specific tasks or learn from their experiences in order to improve their performance over time.
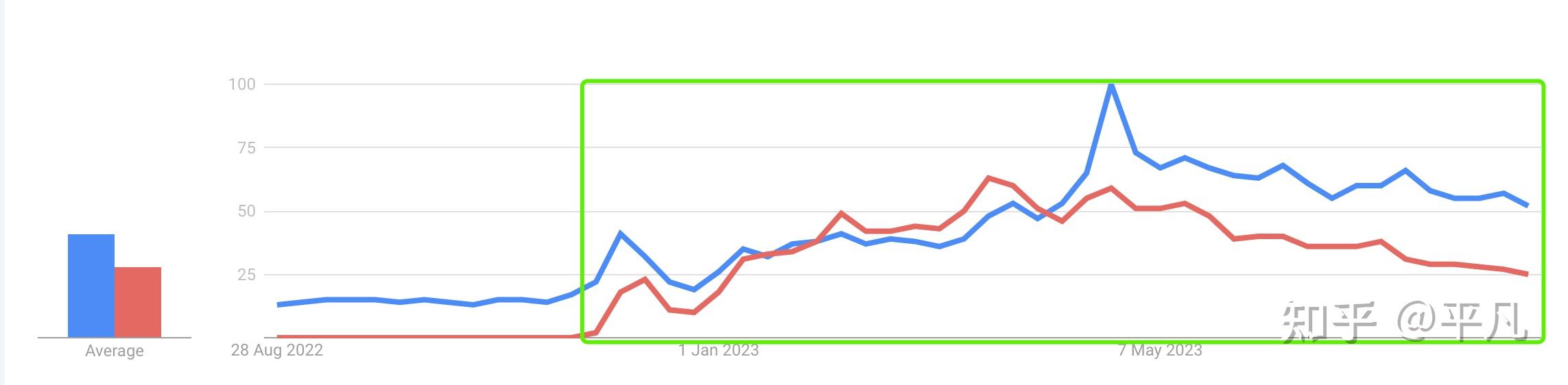
“AI最新趋势”
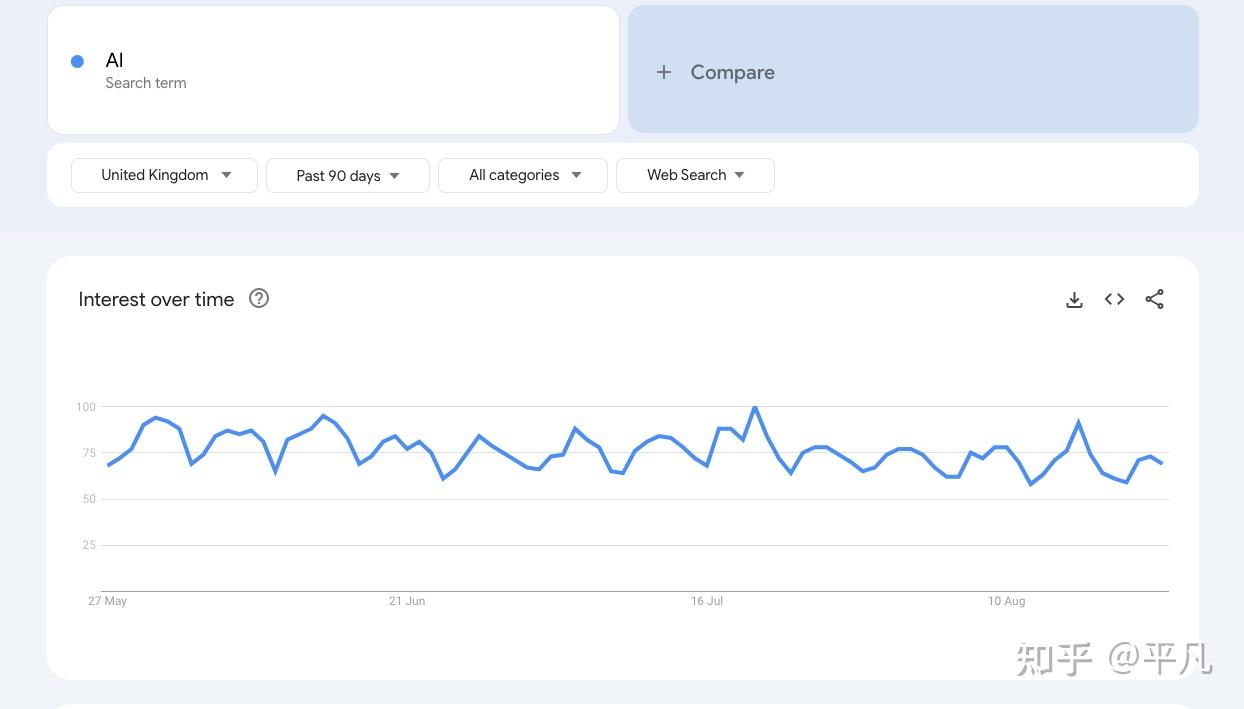
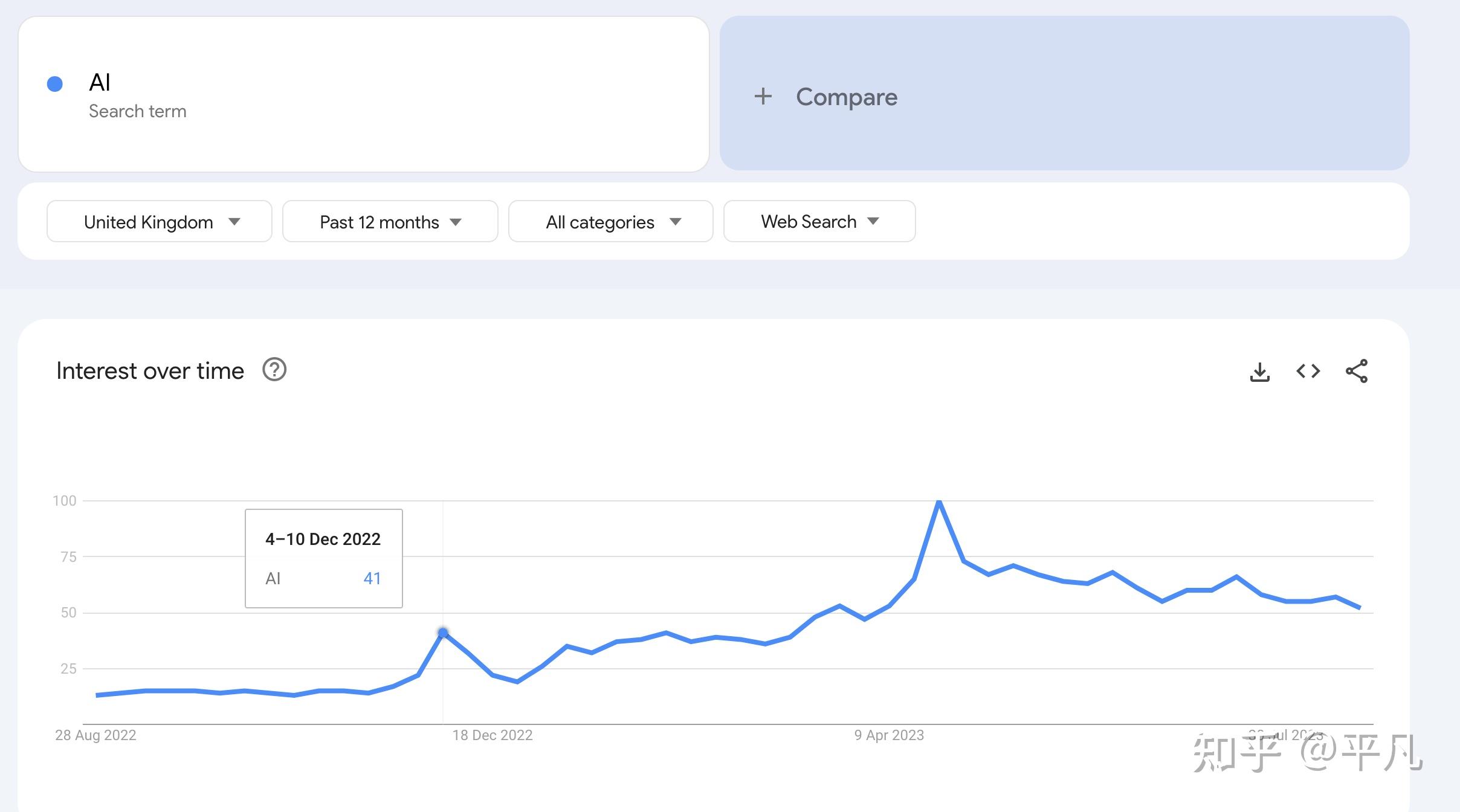
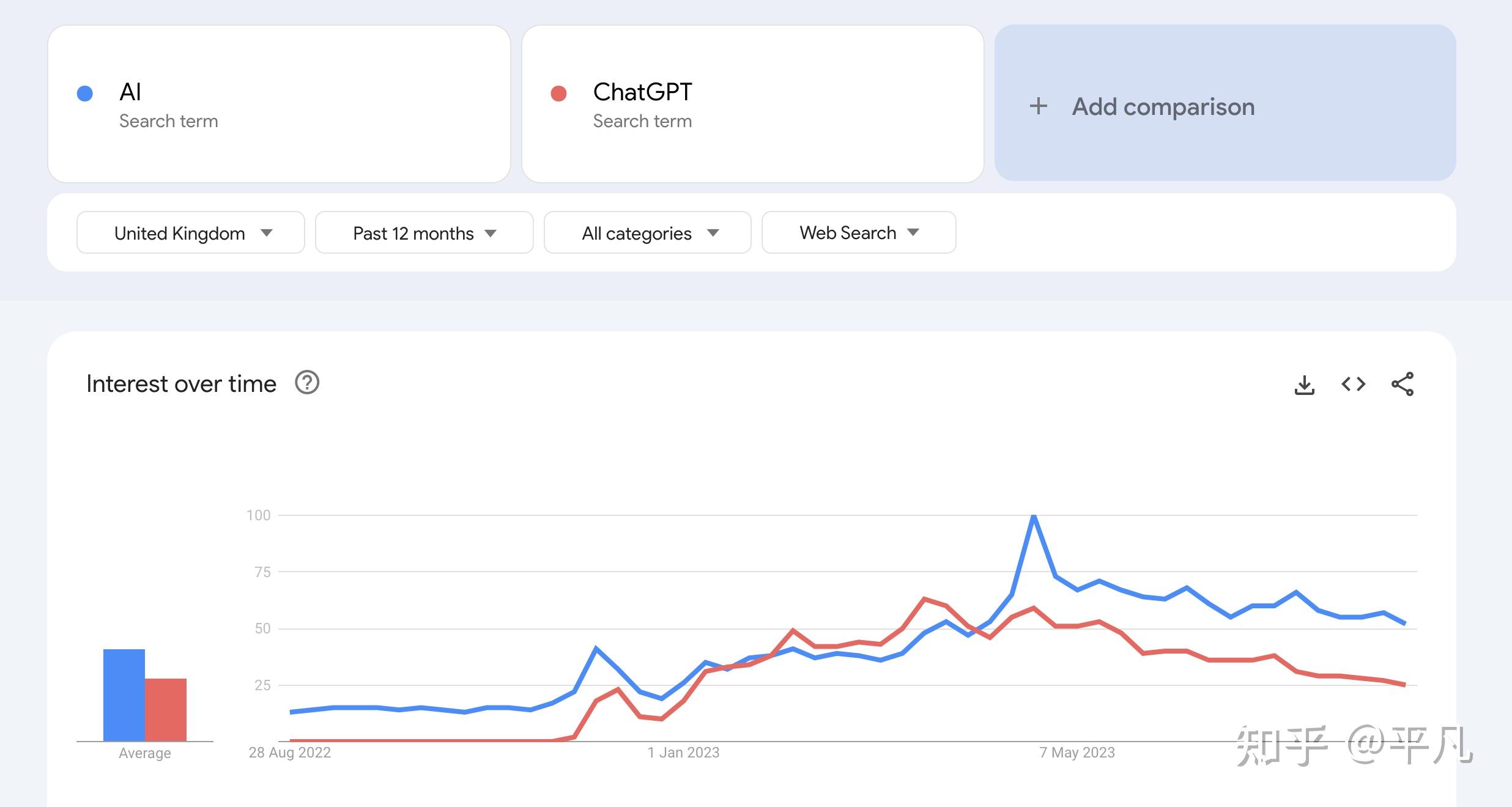
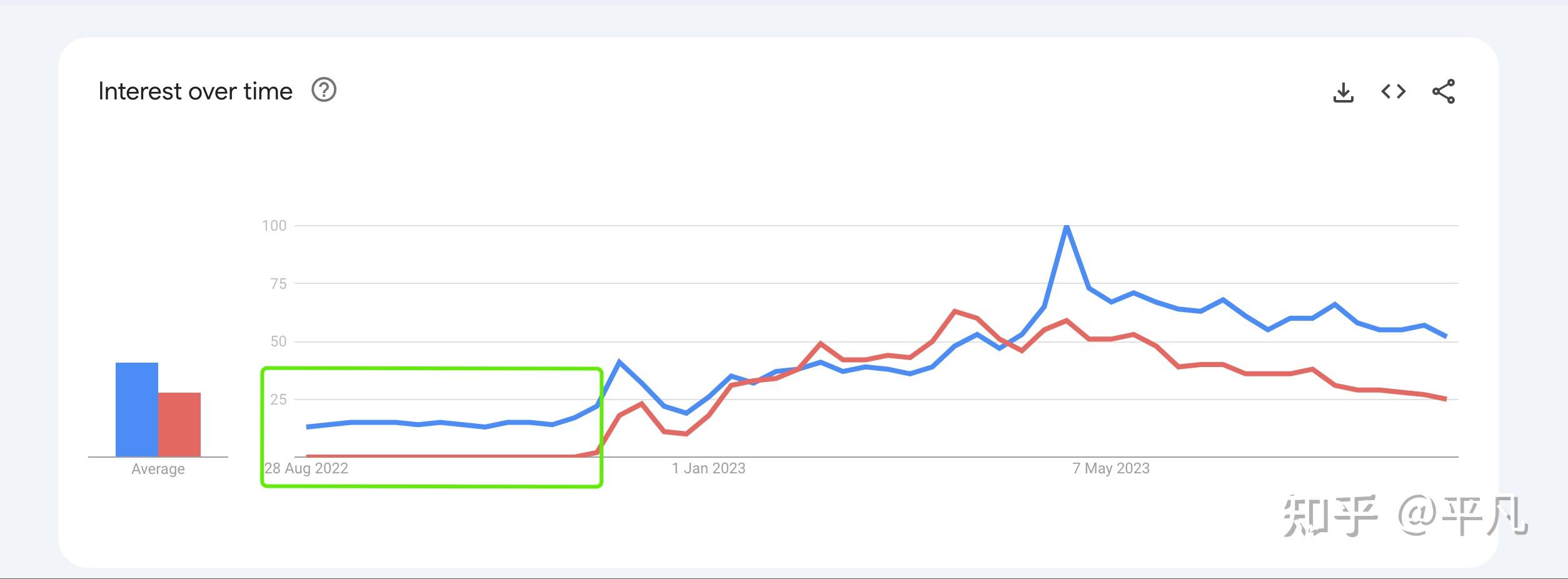
ChatGPT(一种特定的LLM)是最火、最新的方向之一,这个大家肯定不质疑。基于ChatGPT的技术自然是更新的技术,虽然很难判断是不是最新趋势,但现在来看AI Agent肯定是最新技术之一。
“可能的创业方向”
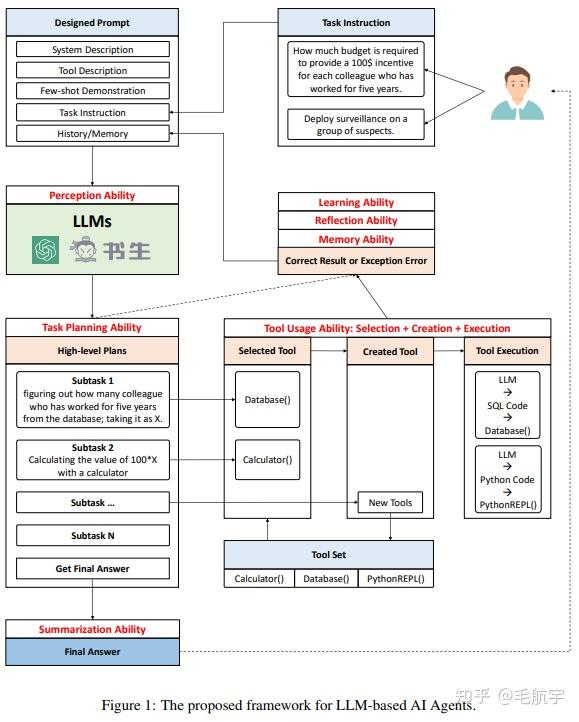
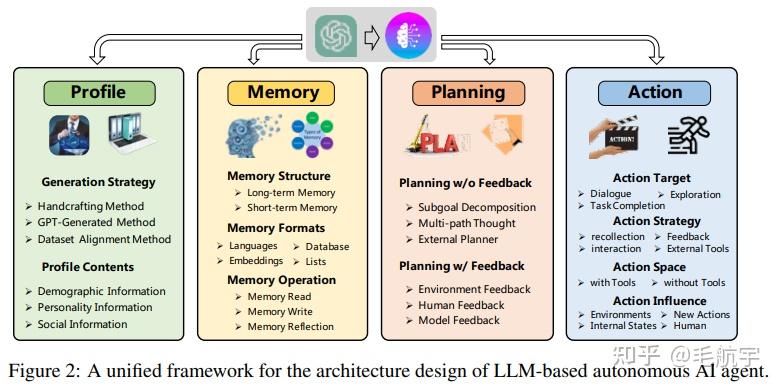
LLM-based AI Agent是在类ChatGPT的LLM基础上,进行planning、reasoning、decision、tool usage(规划、推理、决策、工具使用)等技术加成,让LLM不仅能够进行通用问答,还能真正和现实世界中的实体进行交互,达到改变世界的目的。这种技术极大的拓展了LLM的应用范围,自然能够找到更多的创业方向。例如:
1、复杂任务自动化:帮助用户处理繁琐、重复性且需要大量文本处理的工作。例如,自动化文档摘要生成、智能客服和自动回复系统等。其实也有大量的非文本处理任务,这个很关键,具体就不说了。
2、情感陪伴机器人:LLM嵌入机器人,它能够与用户进行自然语言交互并提供情感支持和陪伴。这种机器人可以在孤独、焦虑或需要情感支持的人群中发挥作用。
3、LLM本身就可以完成的文本类任务:例如智能内容生成和编辑(生成文章、博客、新闻稿等,并提供语法纠正、风格建议和内容优化等功能)、教育和培训领域的智能助手(为学生、教师和培训师提供个性化的学习支持、知识问答和辅助教学)。
关键技术
大家如果感兴趣可以看我们的论文《TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents》,里面有一些关键技术的讨论。另外可以看下最新综述《A Survey on Large Language Model based Autonomous Agents》。这两个论文都是近一个月之内的。
 |