@包寒吴霜 同学对推断统计中常见的误解做了很好的科普,这个问题实在常见又有趣,忍不住补充一点。

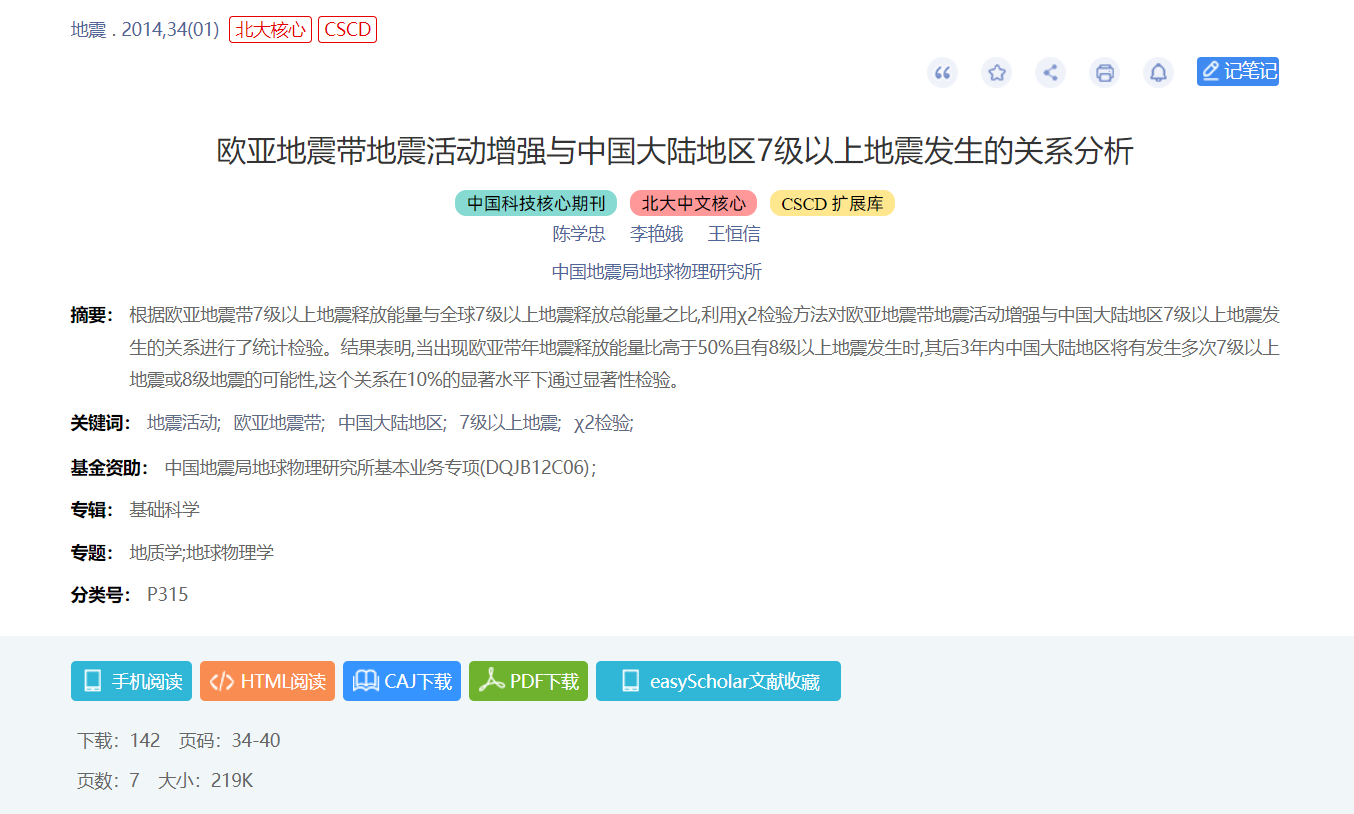
文献原文
文献原文中说【显著性水平为10%,意味着如果以这个结果进行决策,面临的风险是10%,正确的可能性为90%】。
p<0.1的p值是什么意思?是假设H0为真(在这里即关系不存在),得到这篇文献报告的数据的概率,即p(D|H0)。p<0.1就是说假设关系不存在,我得到这样的数据的可能性很小,但我现在确实得到了,就说明关系不存在这个假设多半是错的,推断关系存在,拒绝H0。
但这里,文献中进一步推论,说我们得到了显著的结果,那么以这个结果进行决策(即赶紧防地震),面临的风险(因为关系其实不存在,所以防了却白防了)是10%,也就是说H0为真的可能性为10%,这其实是把推论关系倒过来了,即p(H0|D)。
p(H0|D)才是我们真正想知道的,但因为不能直接计算,我们采用了折中的方案,计算p(D|H0),因为通过假设H0为真,我们可以得到一个抽样分布,进而有可能根据得到的数据计算概率。问题是,p(D|H0)和p(H0|D)相等吗?
这其实是【零假设显著性检验】这种最常用的推断统计方法的一个核心问题。Cohen(1994)对这一点进行了很生动的描述。如果不考虑概率,那么命题A“如果H0为真,那么不会出现数据结果a”成立的话,其逆否命题“如果出现了数据结果a,那么H0为假”也成立,这样的话零假设显著性检验就没有问题。
但如果在其中加入概率,命题A“如果H0为真,那么数据结果a出现的几率很小”成立,其逆否命题“如果出现了数据结果a,那么H0有很大可能为假”就不一定成立了。
例如:命题“如果一个人是美国人,那么他是美国国会议员的可能性很小”是成立的,但是其逆否命题“如果一个人是美国国会议员,那么他很可能不是美国人”显然就不成立。
先验概率
Cohen举了一个形象的例子:成年人精神分裂症发病率为2%,现在有一个诊断精神分裂症的方法,据估计其对精神分裂症患者做出阳性诊断的几率至少为95%,判断阴性的准确率大约为97%。我们假设H0:诊断对象正常;H1:诊断对象患有精神分裂症,即P(判断阴性|H0)≈0.97,P(阳性诊断|H1)>0.95。
看起来这个诊断很准确。这似乎说明假如H0为真,即诊断对象正常,我们做出阳性诊断的几率小于0.05,那么在我们做出一个阳性诊断的时候,就应该拒绝H0,所以诊断对象患有精神分裂症。但事实真的是这样吗?

根据这个数据,P(阳性诊断|H0)确实小于0.05,但是P(H0|阳性诊断)却是60%!当你做出阳性诊断的时候,只有40%的几率对象真的患有精神分裂症,其他60%都是假阳性。现在不会再觉得这个诊断准确有效了吧?
这里P(阳性诊断|H0)和P(H0|阳性诊断)的巨大差距,是由精神分裂症过低的发病率(2%),也就是H1成立的先验概率引起的。
这个例子看起来可能有点不恰当。对每一个个体,都可以进行一次H0是真,还是H1是真的判断,这与推断统计的现实情况确实不太一样。但其实,我们可以把这个例子里的每一个个体都当做一次抽样,并把诊断当做一个连续的变量,也即达到一定标准后诊断为阳性。
我们可以画出H0为真和H1为真时的抽样分布图:

图中蓝色阴影部分占整个H0分布的比例,即假设H0为真,诊断阳性的概率,也即P(D|H0),小于0.05(原谅笔者拙劣的画图技能),但我们真正想知道的是当我做出一个阳性诊断的时候,诊断对象究竟是精神分裂症患者还是正常人,也即P(H0|D),在图中当做出阳性诊断时,对象是正常人的几率,其实是蓝色阴影部分占红色、蓝色阴影部分之和的比例。在这个例子中,这一比例高达60%。
这是因为精神分裂过低的发病率引起的,体现在图中也就是H1的分布比H0矮太多,如果H1的分布高一些,那么P(H0|D)就会减小一些。
统计检验力
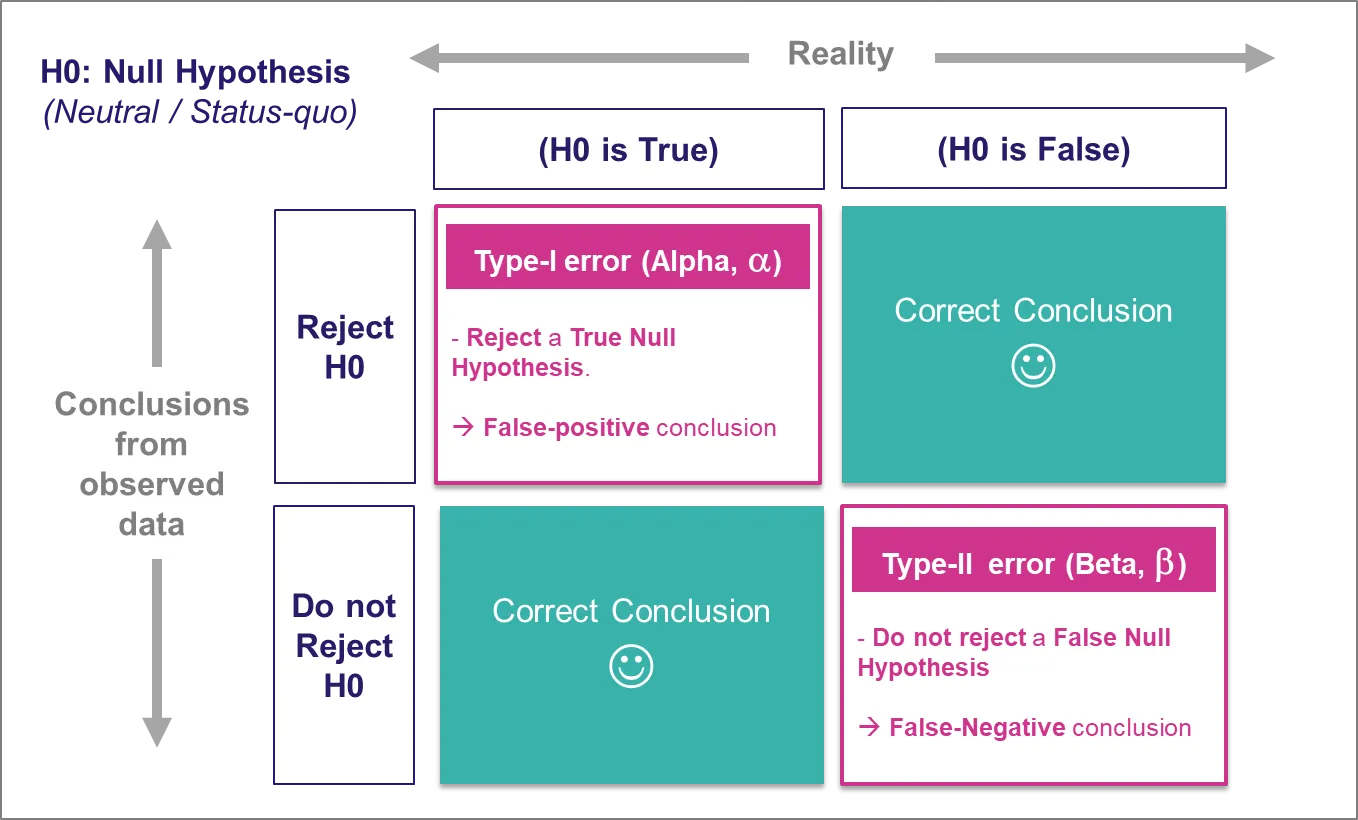
我们先来回顾一下零假设显著性检验中一些基本概念。
第一类错误α:错误拒绝H0假设,也即H0假设为真,却拒绝H0假设的概率。
第二类错误β:错误接受H0假设,也即H0假设为假,却接受H0假设的概率。
而检验力是1-β,所以其定义就是,当H0假设为假,正确拒绝H0假设的概率。
要计算得到了显著的结果,那么H0为真的可能性,可以用一种理论上的算法:首先,我们需要假定一个抽象的值,即当我们提出一个假设的效应,这个效应真实存在的先验概率R。在科学研究中,我们提出的假设自然不会都是在现实中存在的效应,这个先验概率因学科而不同,硬科学可能更高,软科学可能更低;也受到提出假设根据的理论的好坏影响,理论越好,假设的效应真实存在的几率也就越高。
以我熟悉的心理学为例。目前为止,心理学界所有研究平均的检验力大概只有30%到40%,我们就假设检验力1-β为0.3。我们再假设我们提出的假设效应真实存在的概率R为0.3,也即我们提出10个假设,其中有3个是真实存在的效应,对于心理学这门软科学来说,这个估计不算低了。
那么现在,我们得到的所有显著结果(P(D|H0)<0.1)可以分为以下两类:
1.真实存在的效应,也即H0确实为假,检验力决定我们正确拒绝H0假设的概率。在所有研究中占的比例为R*(1-β)=0.09。
2.其实并不存在的效应,也即H0为真,却因为第一类错误被探测为显著。在所有研究中占的比例为(1-R)*α=0.07
那么在这种情况下,我得到一个显著的结果,说明效应真实存在的概率就是0.09/(0.09+0.07)=56.25%,比0.9小了很多,而另外的43.75%都将是假阳性结果,也就是说结果显著,但真实的效应并不存在。
在上面的例子中,如果R不变,检验力由0.3提高到0.8,那么显著的效应真实存在的概率将提高为0.24/(0.24+0.07)=77%。
在此基础上,R提高到0.5,也即两个假设的效应中就有一个真实存在,这时显著的效应真实存在的概率才接近90%。
<hr/>那么回到地震的研究,对于这个数据并不充分、显得粗糙的研究,你认为它的先验概率和统计检验力处于怎样的水平呢?
统计检验力必然不高,先验概率难有公论(地壳运动的联动可能存在,但为什么一定是后3年内?),但至少就我所见,在得到0.1水平上的显著结果的基础上,推论关系真实存在面临的风险,远大于10%。
参考
Cohen, J. (1994). The earth is round (p<. 05). American psychologist, 49(12), 997-1003.
Button, K. S., Ioannidis, J. P., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S., & Munafò, M. R. (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience, 14(5), 365-376. |