统计学确实是机器学习,或者更高一层的人工智能的学科基础之一(其他的还有哲学、数学、经济学、神经科学、心理学、计算机工程、控制论、语言学……),但是并不能说机器学习的本质就是统计学,不然联结主义的神经网络模型要站出来跳脚了。
就像,物理学的基础是数学,但是也不能说物理学的本质就是数学。
早期的机器学习确实十分依赖于统计学。但统计学仅基于概率空间。你可以从集合论中推导出整个统计学,集合论讨论了如何将数字分组为称为集合的类别,然后对这个集合施加一个度量,以确保所有这些值的总和为1,这就是概率空间。但机器学学并不仅仅基于概率空间。
而且,统计机器学习的风险在2015年陆汝铃教授在给“南瓜书”作序的时候就提到过:
王珏教授认为统计机器学习不会“一路顺风”的判据是: 统计机器学习算法都是基于样本数据独立同分布的假设,但是自然界现象千变万化,“哪有那么多独立同分布?”
可能是两者使用的方法的相似性导致了机器学习本质是统计的说法,可以理解,但未免有点管中窥豹的意味。以线性回归举例,在统计建模和机器学习算法中都常用到。
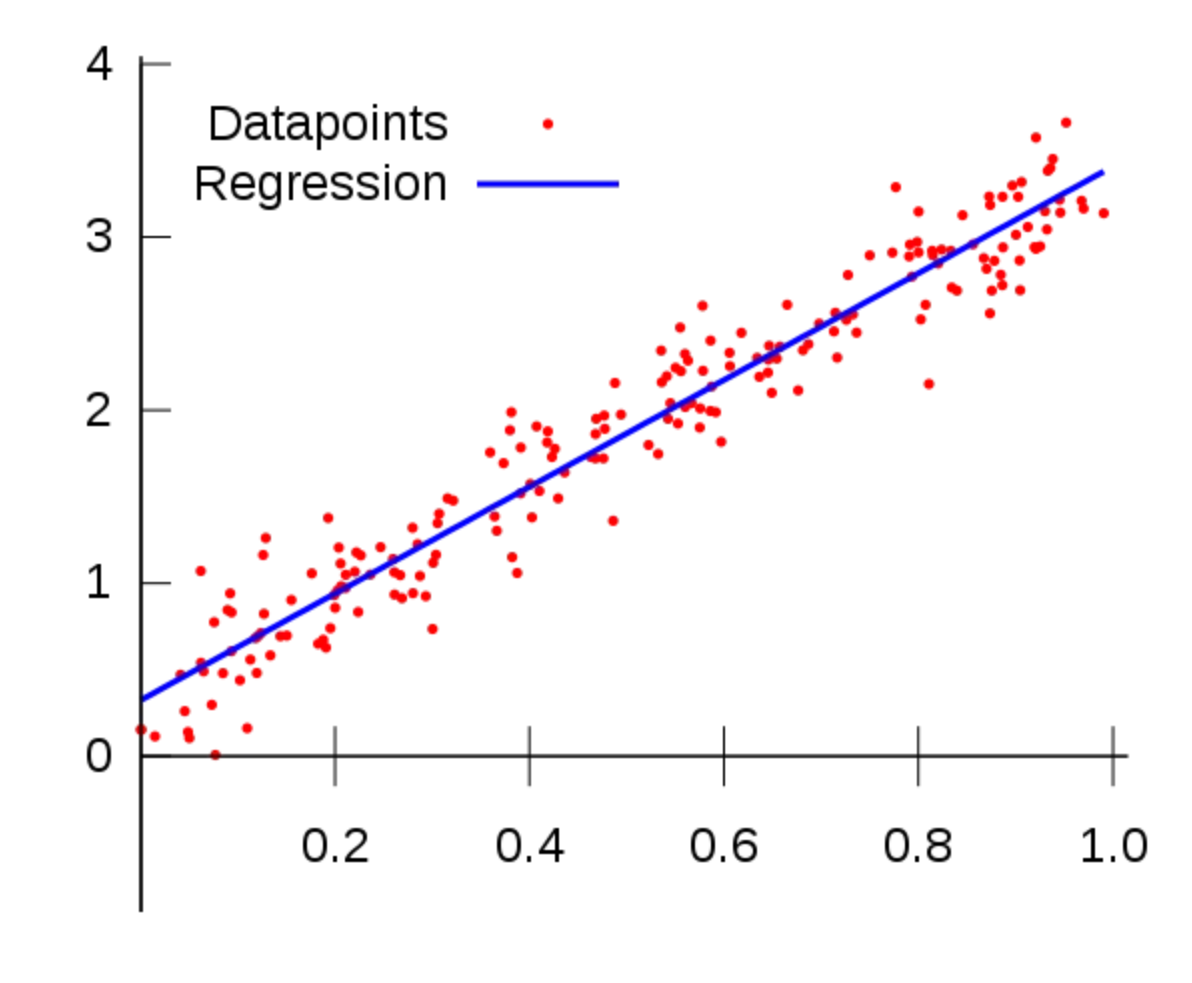
线性回归是一种统计方法,但我们也可以用线性回归算法进行训练,可以得到与使用统计回归模型以最小化数据点之间的平方误差相同的结果。
在统计建模中,线性回归常用于建模因变量与一个或多个自变量之间的关系。目标是理解和量化这些变量之间的关系,并对数据所代表的总体进行推断。通常会使用统计假设和技巧,如假设检验和置信区间,来评估估计系数的显著性和不确定性。
在这种情况下,重点是理解潜在关系并从数据中得出有意义的结论。模型的可解释性和估计参数的统计显著性是重要的考虑因素。
在机器学习中,也可以使用线性回归,但关注点不同。线性回归的目标是构建一个能够根据自变量准确预测因变量值的模型。重点是找到能够最小化预测误差的最佳模型。
在机器学习中,模型的可解释性可能不如预测性能重要。相比于模型的可解释性,机器学习算法更加关注预测的准确性。比如神经网络,可能可以达到很高的预测准确性,但缺乏可解释性,使得理解变量之间具体关系变得困难。
所以啊,虽然统计建模和机器学习都可以用线性回归,但它们的目标和优先级是不同的。统计建模关注于理解关系和推断,而机器学习关注于预测和优化准确性。

总结一下,机器学习和统计学在底层目标、数据和可解释性上有根本区别。
· 底层目标:统计学的目的是基于样本对总体进行推断,以得出关于总体的结论,比如确定变量之间的关系、估计总体参数等。而机器学习的目的是通过在数据中寻找模式来进行可重复的预测,也就是用数据构建模型来进行预测和决策。
· 数据:统计学的目的不是进行预测,建模的目的是为了显示数据和结果变量之间的关系,一般不涉及多个数据子集。而机器学习需要大量的数据才能进行准确的预测。模型是使用训练数据构建的,并使用验证数据集进行微调,最后使用测试数据集进行评估。
· 可解释性:统计模型通常较易于理解,因为它们基于较少的变量,并且关系的准确性由统计显著性检验支持。但机器学习数据集中包含大量的特征和权重,从这些数据中开发的模型既可以极其准确,又几乎无法理解,而且往往会为了预测准确性而牺牲可解释性。
<hr/>传播先进文化、推动社会进步,蒙您欢喜,不要忘记点赞、分享、关注@清华大学出版社 IT专栏
哦~ |