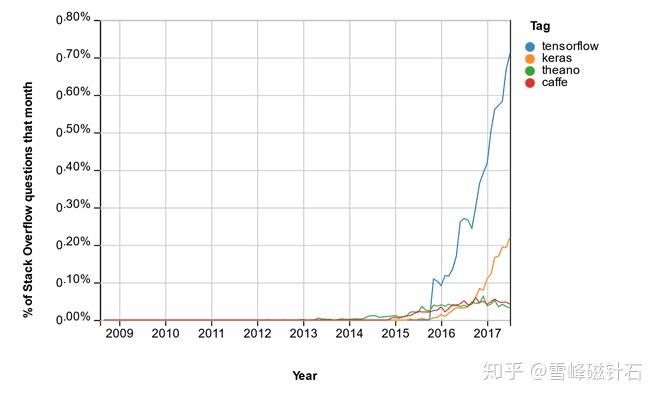
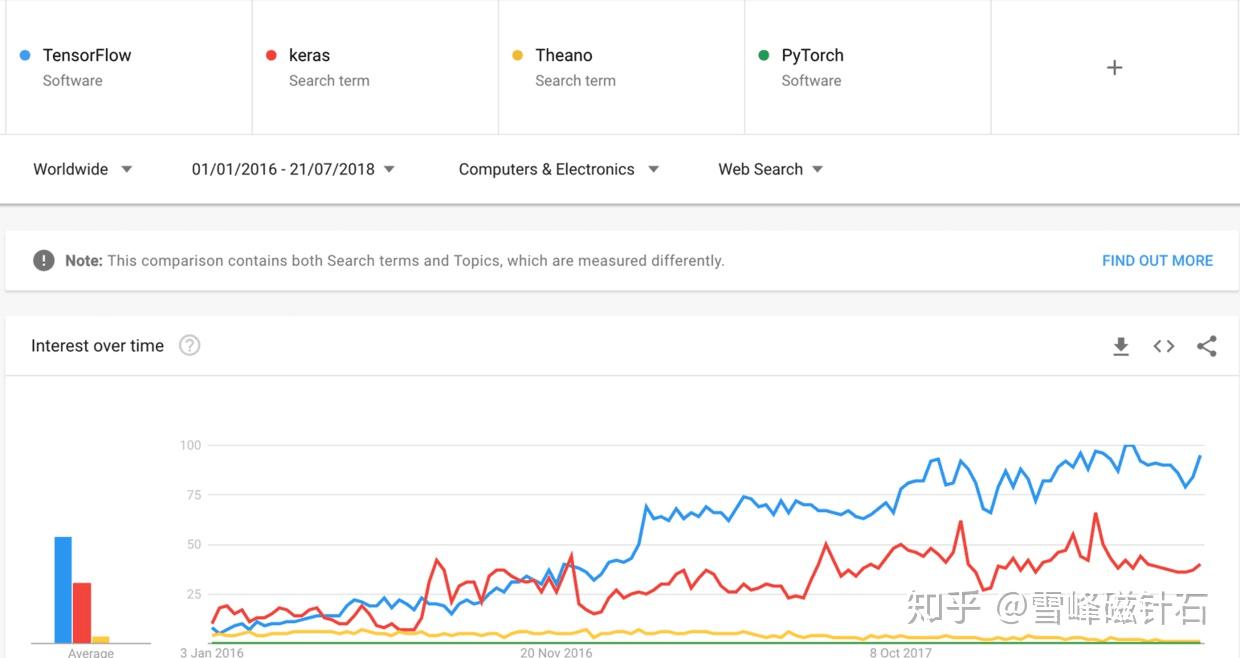
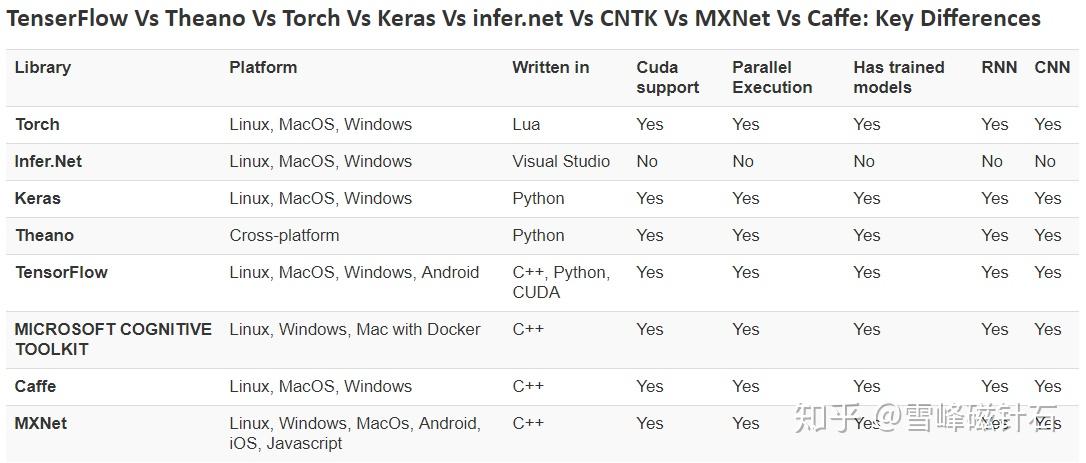
好工具非常多,其他答主的分享也很棒。但使用工具只能让人入门,我们有没有可能自己写一个优秀的机器学习工具库,为开源做贡献,同时积累经验呢?
答案是肯定的,我试过了,是真的。本着授人以鱼不如授人以渔,本文会从「开发者角度的来看如何做出一个好的机器学习工具库」。
1. Start Small (从小做起)
写工具切忌眼大肚子小,如果你计划要写一个TensorFlow,那估计这辈子都不可能完成。因此不妨从最基本的小模型做起。举个简单的例子,假设你想做一个聚类工具库来实现各种聚类算法(kmeans,dbscan,hdbscan),第一步不妨先挑一个自己熟悉算法动手尝试一下,感受一下算法的门槛。毕竟这是个小马过河的问题,最好先对自己的水平有一个良好的评估。
每实现出一个新的算法,就把它们整理好放到GitHub上去。可能过一段时间你就会发现有人开始star你的项目了,这会大幅度的增强你的信心。我自己的写工具库的故事就是如此,我一开始实现了一系列算法主要是为了自己的研究,结果莫名收到了不少star,这给了我很大信心,做出后续工具库也就是水到渠成了。
2. Design High (往“高”设计)
当你有了一系列聚类模型后,你就会发现其中有很大的重构和整合机会。举个简单例子,所有的聚类模型应该都可以fit(X_train)数据,当模型被拟合后,predict(X_test)应该可以在新的数据上进行预测,给出聚类标签。同理,一个聚类模型可能在完成训练后(fit后)应该生成训练数据X_train的聚类标签,并储存在labels_这个attribute中。以sklearn为例,fit(),predict(),和labels_是大部分聚类算法所共享的,而这些算法都是从ClusterMixin中继承而来。- >>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
- >>> kmeans.labels_
- >>> kmeans.predict([[0, 0], [12, 3]])
所以在开发工具库时,可以在完成2-3个模型后开始设计底层的抽象类(abstract class),之后让其他模型都从该abstract class上继承。另一个好处是这样你可以在这个abstract class上轻松添加很多实用功能,比如get_params, set_params,__repr__等。感兴趣的朋友可以从模仿sklearn做起:sklearn.base.BaseEstimator - scikit-learn 0.20.3 documentation。
3. Readability & Deployment Matter(文档与部署很重要)
很多程序员只写代码,不写文档,不写案例,不做宣传。那么很自然的,你写的东西也就没人用。因此写好文档与示例非常重要的。我建议至少花和写代码一样长的时间写文档,其中主要有三个构件:
- 代码中的docstring。建议使用numpydoc的风格:numpydoc docstring guide - numpydoc v0.9.dev0 Manual
- GitHub上的ReadMe文档。例子可以看https://gist.github.com/dupuy/1855764
- Read the Docs的API文档。使用指南看这里:Home | Read the Docs
值得注意的是,ReadMe文档最好是用rST语言来写,因为Read the Docs的语言也是rST,统一语言可以减少大量的开发成本。rST的编写指南可以参考:https://thomas-cokelaer.info/tutorials/sphinx/rest_syntax.html
使用Read the Docs的另一个原因是它可以通过代码中的docstring自动生成工具库API,节省大量的开发成本。
除此之外,写好工具文档还不够,我建议针对每个模型单独提供一个示例文件,比如kmeans就做一个kmeans_example.py帮助使用者了解你的api。另一个很好用的工具叫做Binder,它可以在线运行你的jupyter notebook,这样可以帮助使用者在不安装的前提下尝试。
同时要记得:人类是视觉动物,一个好的图文实例远远好于干巴巴的长篇大论。
同时也要记得:人类是懒惰的。因此建议早早采用PyPI和conda来分发你的工具库,这样使用者就可以轻松使用pip和conda来安装啦。
4. Sustainable Development(可持续开发)
写好几个模型容易,但保证工具库是可持续和可扩展是很难的。假设维护5个模型很简单,那么维护200个呢?所以在开发工具时就要考虑到这一点,有几个点非常重要:
- 首先是必须有单元测试(unit test),每个对应的模型如无例外都应有对应的测试,保证代码的覆盖度。
- 其次是善用集成测试工具(continuous integration),它们可以在多个平台与Python版本下自动运行你的单元测试,常见的工具有:
- Continuous Integration and Deployment service for Windows and Linux
- Continuous Integration and Delivery
- Test and Deploy Your Code with Confidence
- 相似的,维护代码的可读性和测试覆盖度(code coverage)也很重要,对应的工具有:
- Coveralls.io - Test Coverage History and Statistics
- Velocity | Code Climate
- 最后要写好开发指南(contribution guide)与如何反馈问题
- 如何参与开发,为其他感兴趣的人提供一个模板
- 如何反馈问题,一个标准issue report该有哪些部分
- 后续开发计划是什么?新模型的添加标准(inclusion criteria)是什么
不难看出,在这个阶段的重点是如何把一个项目做成真正的开源项目,一个持久的项目。到达这个阶段以后,项目本身已经比个人更加重要,我们必须为了可持续性而牺牲掉一些便携性。
5. When Possible, Optimize! (优化)
一个有效的工具库必须要考虑到扩展性,这个主要是说在数据量上的scalability。一个工具库如果只能解决几百几千个小数据集,那么就只是个玩具。真正的实用性来自于scalability和鲁棒性(robustness)。所以当你的工具库有了一定的规模后,建议多考虑重构和效率提升。
从机器学习,特别是Python工具库开发的角度来看有几个简单的技巧:
- 向量化(vectorization)
- numba加速(A High Performance Python Compiler)
- 并行化(parallelization,一般用Joblib: running Python functions as pipeline jobs比较多)
- 用C重写模块,用Cython调用(Cython: C-Extensions for Python)
其他更大规模的集群不在本文的探讨框架下,但有趣的对比实验可以参考「对于 Python 的科学计算有哪些提高运算速度的技巧?」
另一个值得注意的是,大部分机器学习工具库一般不把GPU支持作为首要任务(深度学习库除外),因此可以把这个需求推后实现。
6. One more thing ,know why to do it(保持初心)
写工具库的最终目的是为了锻炼自己,回馈社区。如果一开始的目的就是要出名,做个大新闻,有大概率只会铩羽而归。我开发过特定领域的通用库,同时也和很多优秀的开源贡献者有过探讨交流,包括scikit-learn的核心作者Alexandre Gramfort。Gramfort带给我的最大震撼不是工程与学术能力超强,而是超乎常人的认真---在一篇工具库论文中他给我们写了满满4页的评语,甚至运行了我们大部分案例与测试,这种精神让人肃然起敬。
所以写库不必太在意成功是否,自己努力过坚持过就好,只有真正的热情才能让我们一直持续维护与更新。我认识不少只有几个用户却一直不放弃的开发者。我想这才是开源的真正意义吧。 |