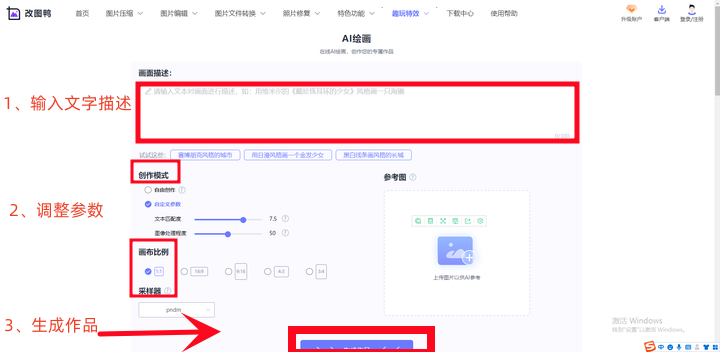
说个瓜。
在ChatGPT出来之前,国内互联网普遍都是跟着谷歌后面走的。谷歌认为大模型方向没啥搞头,所以国内互联网公司对大模型投入都很少。
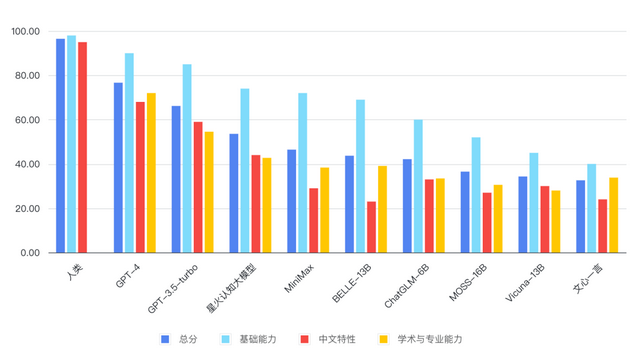
但,当时有个人觉得大模型是未来的方向,就是清华大学的教授、智谱AI的创始人之一,唐杰教授。我记得是他在19年就投入大语言模型炼丹的工作。于是,在ChatGPT火起来的时候,唐杰教授和他的智谱AI拿出了中文领域里最强的大语言模型——ChatGLM。国内其他互联网公司提供的大语言模型,都不如满血版的ChatGLM。
这里就看出,大语言模型先发优势是多重要。实际上大语言模型的最核心论文就三四篇,只要是从事NLP领域的人,基本上跟着youtube上的视频,一周也能看个七七八八。但就算如此,在训练过程中,依然有不少坑需要踩。所以对于训练大语言模型,经验就尤为重要。
这里不得不提国内某云计算大厂的大语言模型诞生,实际上也就是去年看到GPT3.0效果很好后,开始尝试。当时公司内有5,6个组,同时开始炼丹,然后PK,看谁的效果最好就留用谁的。这个时候,一个从清华大学毕业的博士,因为之前跟智谱AI关系密切,很快就让他领导的小组的模型在测试中脱颖而出。最后pk掉了其他组,改名成了XXXX,成为了现在大家熟知的一个模型。
所以为啥国内大语言模型感觉还差些,因为他们真实诞生的时间可能都不满一年。炼丹师的经验不足。而openai的员工已经在这里跑了好几年了。
而一次大语言某些的训练,时间成本也很高。经常一次全量的训练所需的时间是按月计算的。而且正如我说的炼丹,在模型训练跑出结果之前,没人知道这次效果如何。失败一次,意味着几个月的工作都没结果。只能把失败经验总结,然后投入下一次炼丹中。
我比较乐观的估计,国内明年的大语言模型能赶上ChatGPT3.5的水平。那个时候,才是国内真正大模型能开始商用的时间点。
当然,一些微调模型也在快速迭代中。是否可以通过微调垂直领域的信息,让大语言模型可以快速在某些领域落地也不好说。
不过,国内最限制大语言模型应用发展的,绝不是国内大语言模型本身性能。 |