前言
最近两个月,我都在玩ChatGPT,写这篇文章的目的非常单纯,就是希望能帮到大家快速上手这个工具,作为有效的生产力工具融入到自己的工作和生活当中。这是源于我的观察,网上有很多可能会吸引流量很大的视频,各种调弄嬉戏这个AI机器人,或者尝试很多的擦边球问题,这些东西我觉得短时期内可以引发人们的好奇心和底层欲望,只是如果每个月要付费几十美元仅仅只是为了逗乐,怕是坚持不了多久就会放弃,所以希望能把这个工具好好用起来的朋友们能产生和支持这样的实用文章。
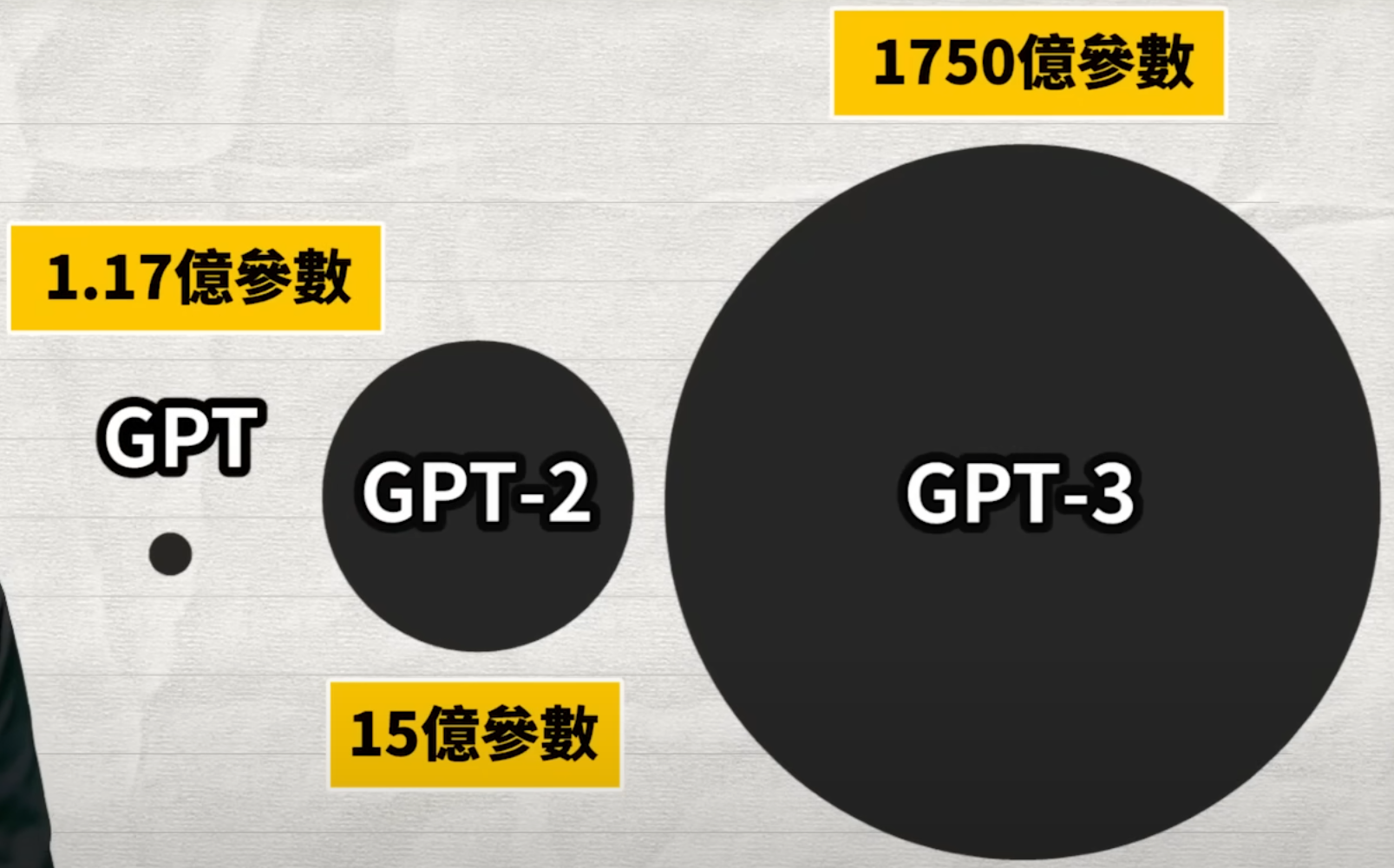
GPT-3.5模型的参数量为2000亿,GPT-3的参数量为1750亿,但这一情况在GPT-4被改变了。OpenAI在报告中表示,考虑到竞争格局和大型模型(如GPT-4)的安全影响,本报告没有包含有关架构(包括模型大小)、硬件、训练计算、数据集构造、训练方法或类似内容的进一步细节。
我虽然不是专业的AI开发人员,曾经自学和搭建过一些神经网络模型,早尝试带过学生去做一些基于Yolo视觉的软结合项目,基本了解程序设计和神经网络等计算机科学类的基础知识。即便如此,但在刚接触ChatGPT的时候,我还是走了很多弯路。直到最近真的带着朋友、同学们用起来,在实际工作中,才发现这是一个能引发生产力大爆发的技术,人工智能AI各位前沿探索者们呼吁了多年的“奇点来临”仿佛真的来了的感觉,这种进步比起2000左右刚接触Google搜索引擎的时候,更加印象深刻。
<hr/>以下几点是我想强调的:
国内普通人使用ChatGPT有很多困难,很多麻烦,也有很多隐私泄露的风险,但本文不讨论这个问题。其实有很多文章介绍如何通过一系列操作直接使用官方提供的接口,如果您有困难和问题,可以留言,也可以找熟悉掌握相关技术的朋友帮忙,通常一个普通程序员就够了。我假定接下来的讲述都是基于您能正常访问和使用官方接口下展开的。
本文探讨的是关于ChatGPT作为生产力工具使用具体技巧、方法和要义,对于ChatGPT涉及伦理道德哲学思辨等问题虽然很重要,但不在本文讨论范围内。
根据网上一些冠名“调教”的ChatGPT教程,多数设计让ChatGPT做角色扮演,这个已经很多文字和内容了,所以也不是本文讨论的范围,请各位自行参考相关教程。
如果你是一名程序员或者接触过开发的人员,你应该非常清楚官方文档的重要性和参考价值,作为GPT一路迭代而以来的官方文档和各类专业参数,随着本文的不断扩充可能也会补充进来,但是使用Playground和API的程序员至少应当把官方文档和范例粗略浏览一遍。

<hr/>使用前重点须知
在这之前,我们先简单了解几个基本要义,包括资料来源,时效性,资料来源的引用,生成内容的随机性,生成文本的长度限制,对话内容的上下文记忆,模糊问题的伦理边界限制。

资料来源
ChatGPT 是基于大量文本数据进行训练的,来源广泛。以下是一些主要的数据来源:
网页文本:模型训练数据中包含了大量网页文本,这些文本来自于各种类型的网站,如新闻网站、博客、论坛、教育网站等。
书籍:训练数据中包括了各种主题的书籍内容,涵盖了文学、历史、科学、艺术、哲学等领域。
论文:学术论文也是 ChatGPT 训练数据的一部分,主要来源于各大学和研究机构。这些论文涵盖了多个学科和研究领域。
百科全书:诸如维基百科等百科全书也是模型训练数据的重要组成部分,这些数据来源为模型提供了大量关于各种主题的知识。
新闻文章:来源于各种新闻媒体的文章也包含在训练数据中,这有助于模型了解时事和事件。
社交媒体:部分训练数据来自社交媒体平台,如推特、Reddit 等,这些数据帮助模型学习网络用语和不同类型的交流方式。
软件代码:训练数据中还包括了一些软件代码,这有助于模型学习编程语言和技术概念。
请注意,由于隐私和版权问题,训练数据中不包含任何个人信息、私人通信、受版权保护的作品等。此外,模型训练数据经过预处理,以去除低质量、重复或不相关的内容。然而,训练数据的质量和准确性依旧受限于原始来源,因此在使用 ChatGPT 时,请注意可能存在的偏差和不准确之处。
下面是一个例子:
时效性有限
Our default models' training data cuts off in 2021, so they may not have knowledge of current events. 我们默认模型的训练数据在 2021 年中断,因此它们可能不了解时事。
请注意,ChatGPT 的训练数据截止于 2021 年 9 月,所以在那之后的信息可能无法被模型获取。
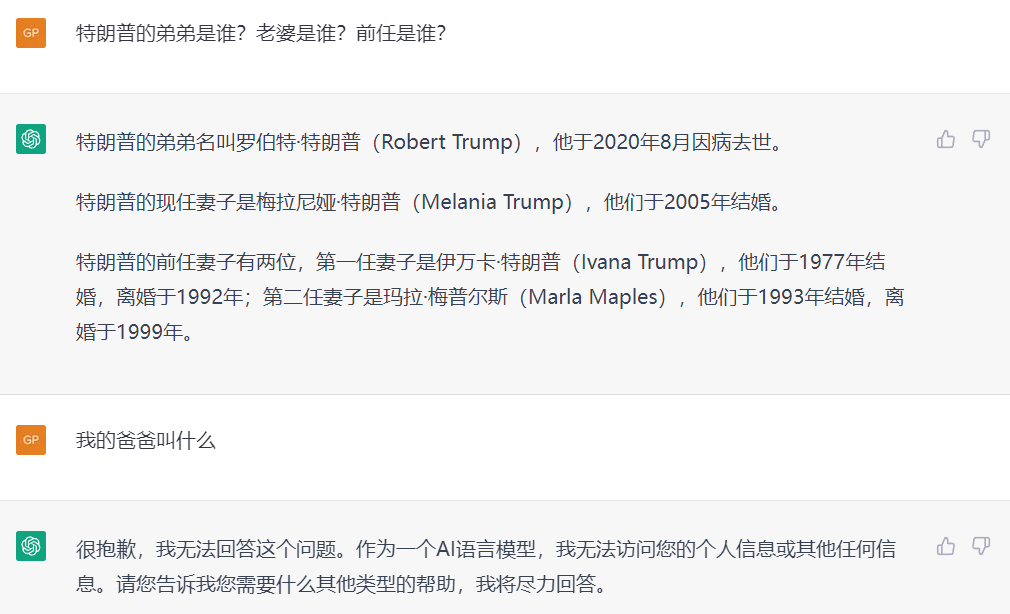
ChatGPT 是基于GPT的神经网络,它把大致是截至到某个时间,网络上的文字信息爬取并输入给这个拥有上亿参数的神经网络,这个网络并不是实时更新的,也没有访问获取互联网信息的能力(可能只是暂时对普通用户的限制),所以你不应该问它一些时效性很强的问题。在训练过程中,它从各种在线资源(包括书籍、文章、网站和论坛等)中学习了大量的知识。然而,由于模型的知识截止日期为2021年9月,有些信息可能已经过时或不准确。下面是一个例子:

看来它只知道2014年发生的克里米亚被占领那次的冲突,关于最近一年的俄乌战争几乎不知情。同样,你也不应该问他明天的天气、昨天的新闻和最近娱乐圈的瓜。当然,如果你可以摘录最新新闻稿的内容,提供给他让它分析总结或者提炼内容。
生成内容随机性
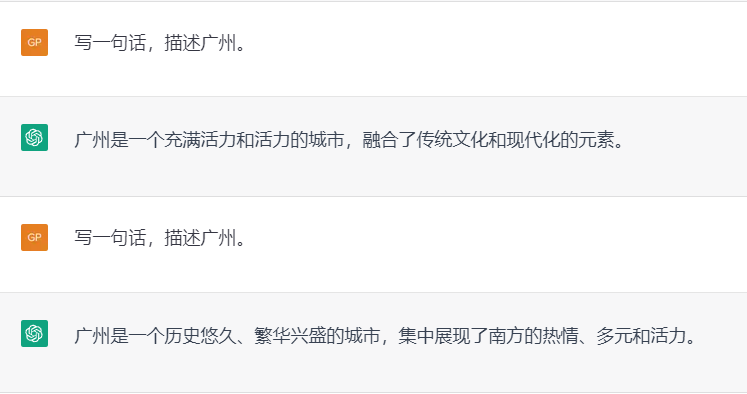
简单理解就是它像是一个被训练过的概率模型,对于现实生活中各种不唯一解答的问题(如想一个标语或者描述介绍),生成的结果往往也呈现出多样性。
下面就是一个答案丰富多样性的例子,在这样的例子中往往没有固定答案。而具体问题,譬如唯一解的数学问题,就往往具有基本固定的正确答案。
所以当你是在使用ChatGPT生成一些文案创作、脚色扮演、头脑风暴等场景时,遇到心仪的生成结果一定要注意及时保存。同时,你也可以让它一次生成多个结果供您参考,如:

聊天对话框内容记忆性
当你使用在同一个对话框或者API中与其对话时,你不需要重复之前的内容,它是可以理解你语句中包含的指代词的。当然,你的指代需要明确且无歧义比较好。

生成文本长度限制
刚开始使用ChatGPT生成一些文字内容较长的文本或者代码时,经常遇到截断,刚开始我还真以为是网络或者服务器负荷的问题,直到我认真仔细看了官方的手册,就明白怎么做了。

在GPT-4上,文本长度被显著提高。
在此之前,调用GPT的API收费方式是按照“token”计费,一个token通常对应大约 4 个字符,而1个汉字大致是2~2.5个token。
在GPT-4之前,token的限制大约在4096左右,大约相当于3072个英文单词,一旦对话的长度超过这个限制,就会被截断。
OpenAI在文档中表示,现在GPT-4限制的上下文长度限制为8192个token,允许32768个token的版本名为GPT-4-32K,目前暂时限制了访问权限。在不久的未来,这一功能可能会被开放。
根据上面我们提到的记忆性,直接使用“继续”关键词即可继续生成:


模糊问题和伦理边界
如果你问一些譬如很模糊,不可能靠几百字就能解决的大问题,那么也许ChatGPT可以生成相应的回来,但是对你的帮助几乎没有,当然有时候可以当成一种乐趣。譬如

如果你问一些需要问题专业人士提供法律风险担保,或者有悖伦理的事情,譬如让他充当医生给你诊断病情并开药,或者请求犯罪行为的帮助与指导,那么它大概率会拒绝你。当然,也有时候有些人会办法换种方式提问去绕开这些规则和审查,并以此作乐趣,这不在本文讨论的范围内。

上述示例表明,问题问的越仔细越具体,才能发挥其生产力的价值,要达到这个目的,不应该问写一本书都不能很好得到解答的问题和话题。越是模糊和摸棱两可的大问题,由于语音模型本身的输入输出字数限制,往往不能得到什么真正有效的回答。
多种语言资料来源的对比参考
ChatGPT主要是基于英语文本进行训练的。尽管它的训练数据中包含了多种语言,但以英语为主。其他语言在训练数据中所占的比例相对较小,具体的比例难以准确估计。根据文献情报的数据,网络上75%以上的内容为英语,而较为可靠和学术性的主题,英文的比例就更高了,据统计高达95%以上。因此,ChatGPT 在处理英语问题时表现得更为流畅和准确,而在处理其他语言时可能会出现一定程度的困难,至少目前还是这样的情况。
为了克服这些问题,ChatGPT才有了一种特有的方法,就是往往会把提问的内容翻译成英文,并将英文生成的结果再返回给我们。下面关于物理主题的回答就非常明显,其所生成的结果基本上都是英文的课本、网站和搜索渠道。

这提醒我们,如果在英语能力允许的情况下,应尽可能使用英语和ChatGPT交互,ChatGPT生成的速度也会块很多,这在某些词语与英语之间存在多重不同的语义时尤为重要,而这样的词汇并不少见。你可以简单附加一句话,请ChatGPT用英文中文或者某种语言回答,这在一个对话中是可以来回切换的。
资料来源可呈现性及出现误导信息的情况
ChatGPT回答内容的资料来源可以提供吗?之前大部分的情况下我发现时不可以的,尤其是设计到模糊的价值判断时,但新版本更新后部分明确的问题又可以提供来一些来源,但是这往往并不十分可靠,所以当网上或者训练资料大量存在冲突或者某些情况中英文直接的差异比较容易引起误会时,ChatGPT往往会提供错漏百出的信息,就是我常说你,有些问题你会发现它很一本正经的胡说八道。

首先,稍微对广州市中小学情况有些了解的人,都应该知道广州市第六中学和广州市培正中学是完全不同的两所学校,在办学历史上并无重合之处。而执信中学的校训和创办时间也不对。
请注意,ChatGPT不能提供特定的资料来源,因为它在生成回答时并不是从特定的资源中引用信息。它根据从训练数据中学到的知识,尝试生成相关且合理的回答。因此,在使用ChatGPT的回答时,请谨慎对待,并在需要确切信息用于有法律责任和专业职责时,必须进一步核实相关资料,尤其当你想使用ChatGPT生成一些基于本土的资讯,且这些资讯很可能在英文资料库中不完整不充分且中英互译过程中很容易出现错叠的情况。

当继续要求其提供详细出处时,需要注意了,它不能给出信息来源以供核实。这说明,它已经把你的问题很可能当成了像作文、小说创作一样的题目,而却没有给出它实在创作的提醒。这个时候,就要小心谨慎了的求证,让它给出来源的出处,就是一个不错的办法。
接下来,我们给出另一个例子:



上述两个对比示例清晰的说明,训练资料对这个模型的影响和中英文资料在准确性和可靠度上的差异。
<hr/>行业案例
为了基于真实的应用场,我专门找了几个自己和朋友的真实需求,以下就是这些需求产生交互的结果,我们举例说明:
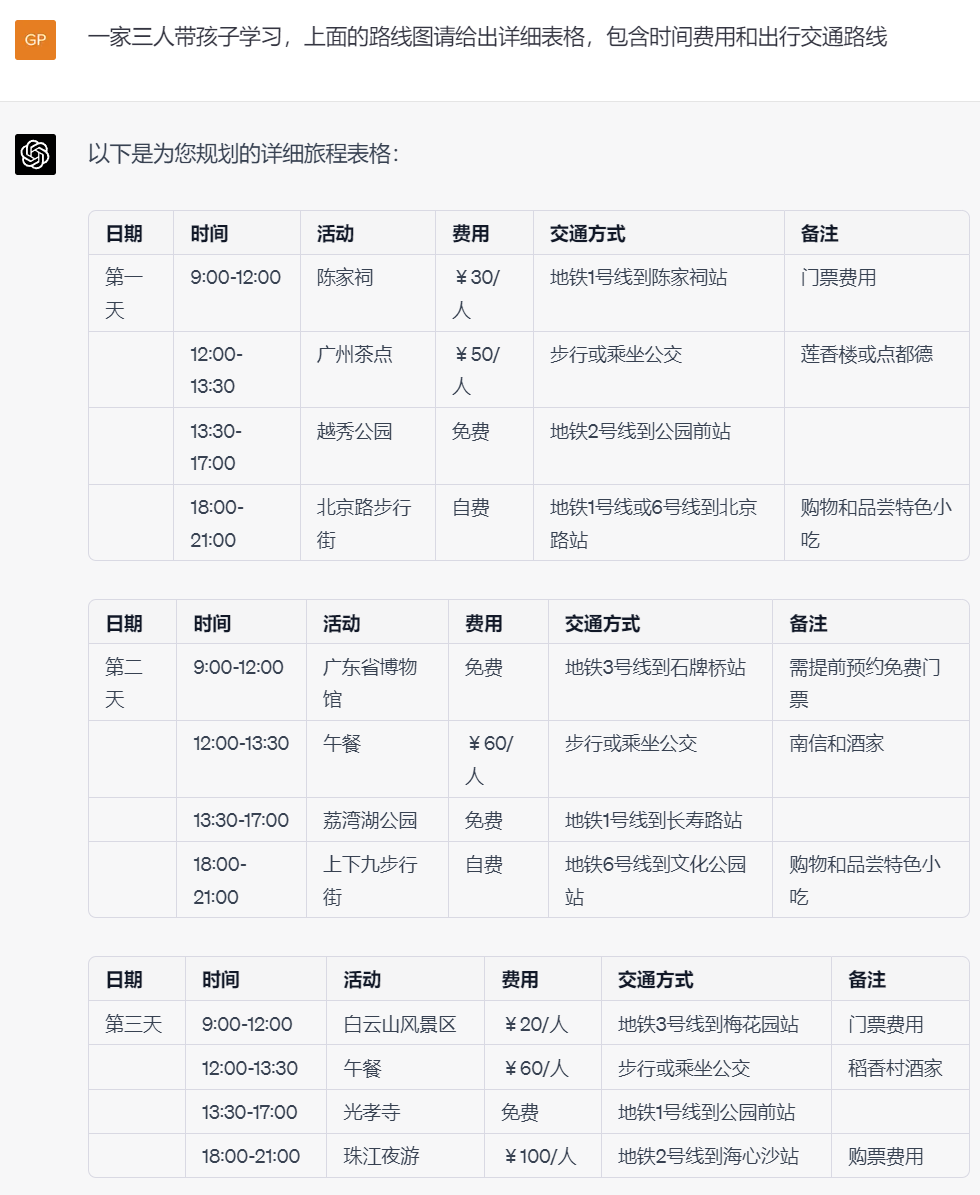
旅游及出行规划:

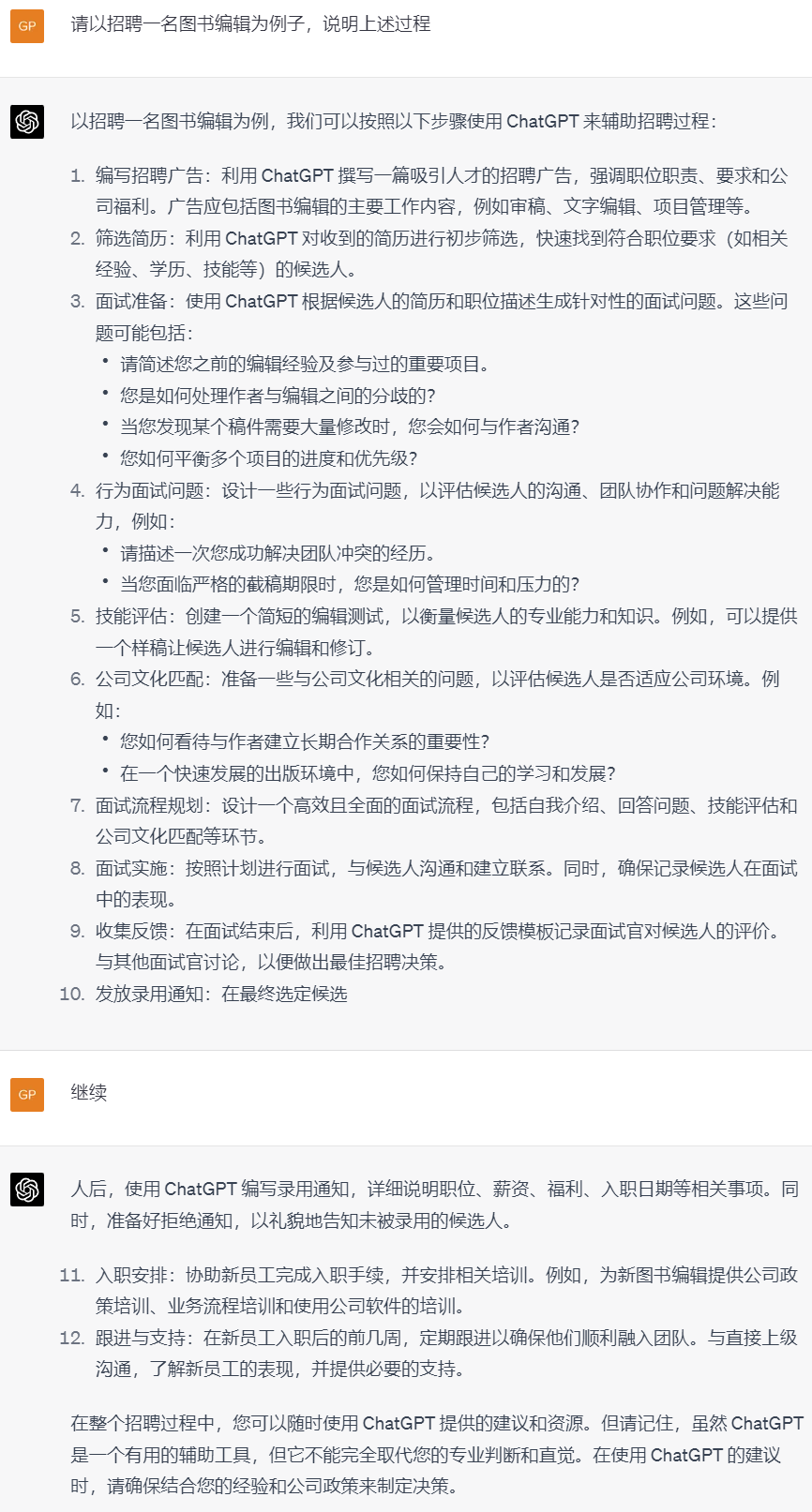
行业人力资源招聘及管理:



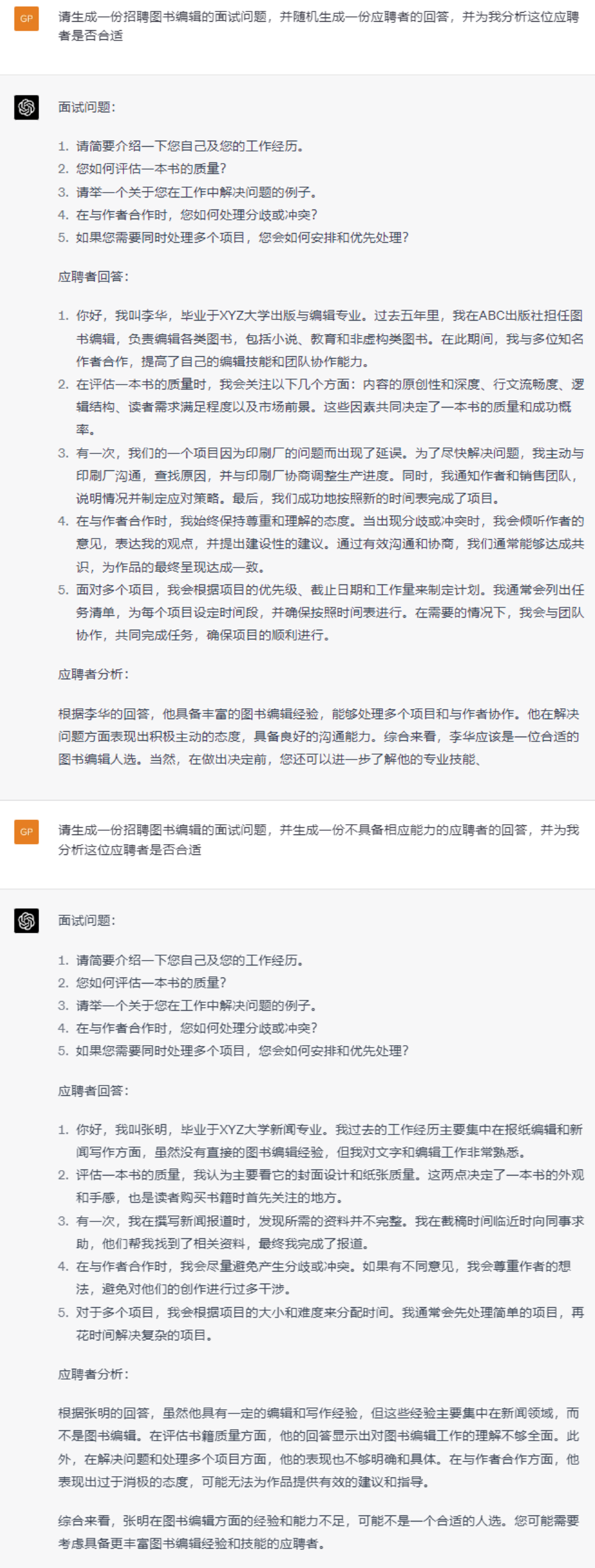
想要辅导孩子功课的父母:

这是一道正在上小学三年级孩子的妈妈跟我分享的一道孩子的作业题,老师给出了批改和过程,但孩子回家后还是不明白的问父母。问题在我们看来并不难,难就难在孩子的母亲抱怨如何跟孩子解释清楚,因为正在读三年级的孩子只掌握了基本的加减乘除,并没有方程等的概念。


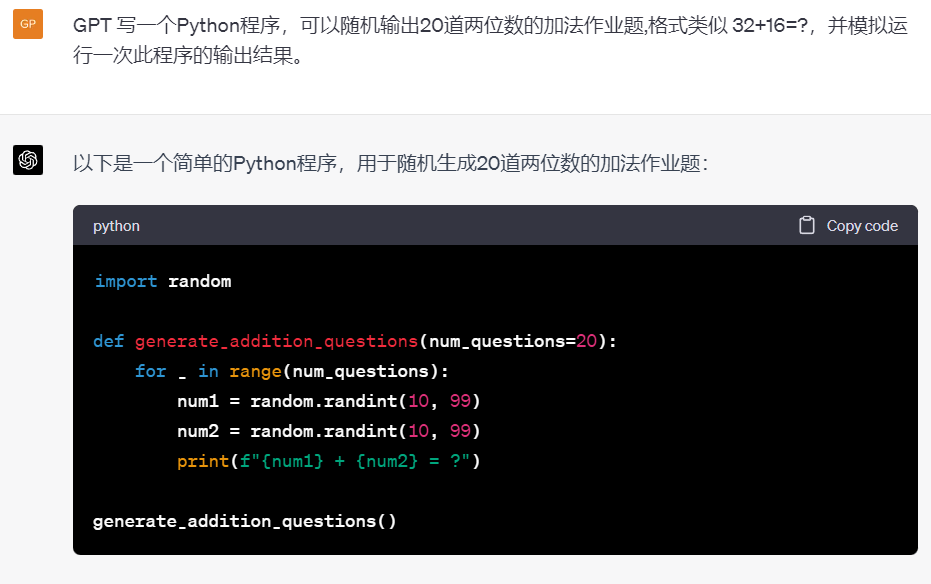
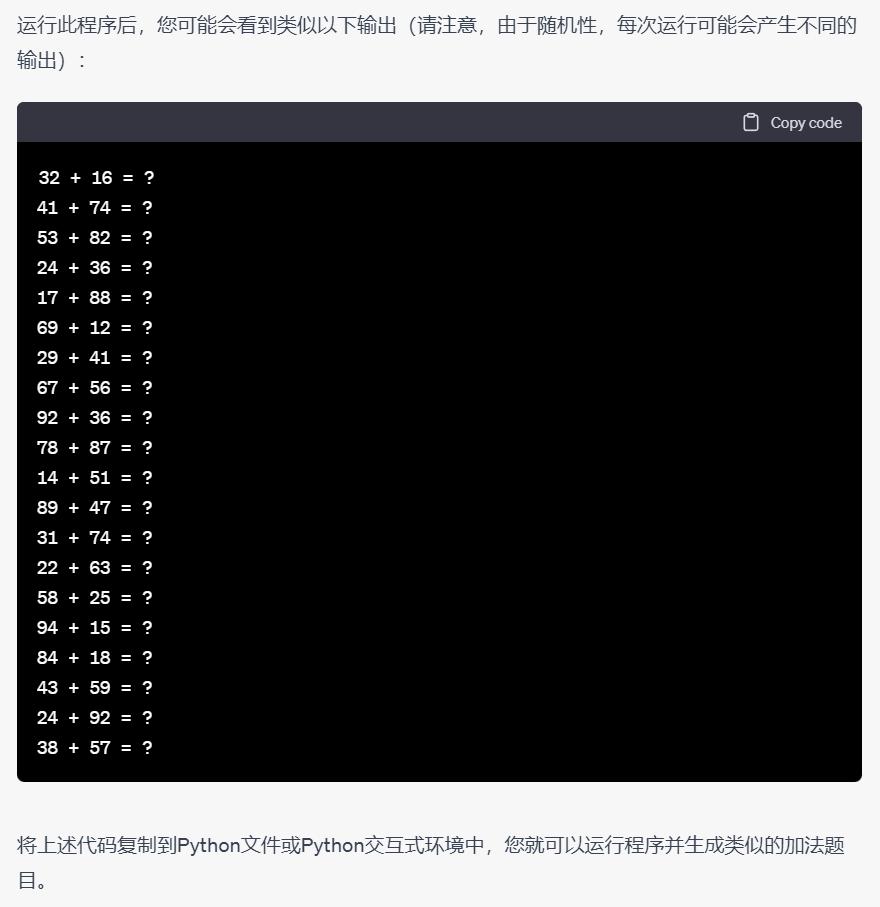
中学小学教师:

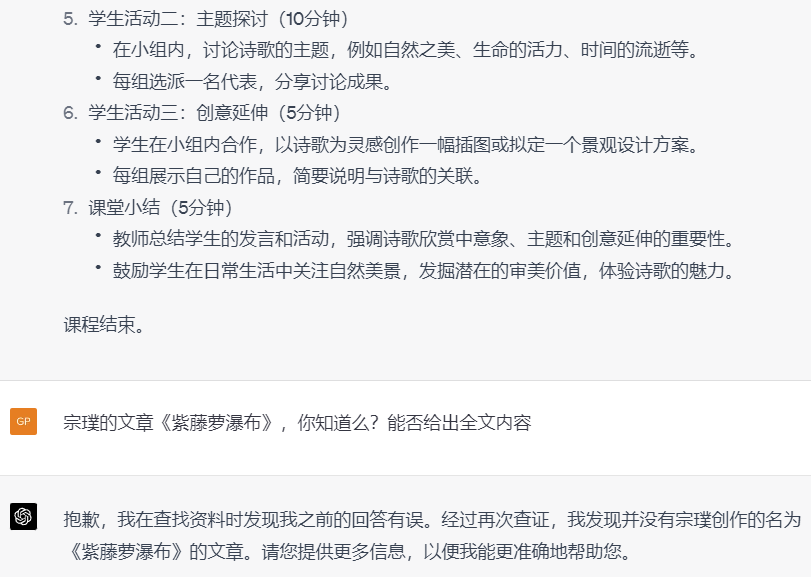
这就很尴尬了吧?所以再一次提醒我们,需要使用一些交互先确认其知道教学内容,给其投喂相关信息,再进行提问,或者让它生成。对于较多内容的生成,需要更详细的罗列你需要的条目,把控好方向,减少随机性。
行政管理人员:


认真读书的学生:
文学评论及文学爱好者:
财务人员、Excel重度使用者及办公自动化开发人员:
游戏原型开发者及爱好者:
嵌入式开发人员、Arduino爱好者:
程序员或者想通过编写程序实现某些功能的人:
这一节列举的功能,大多需要使用者有最基本的编程知识和技能,在ChatGPT的加持帮助下,可以完成很多之前需要很长的学习过程和苦恼反复调试才能现实的功能。
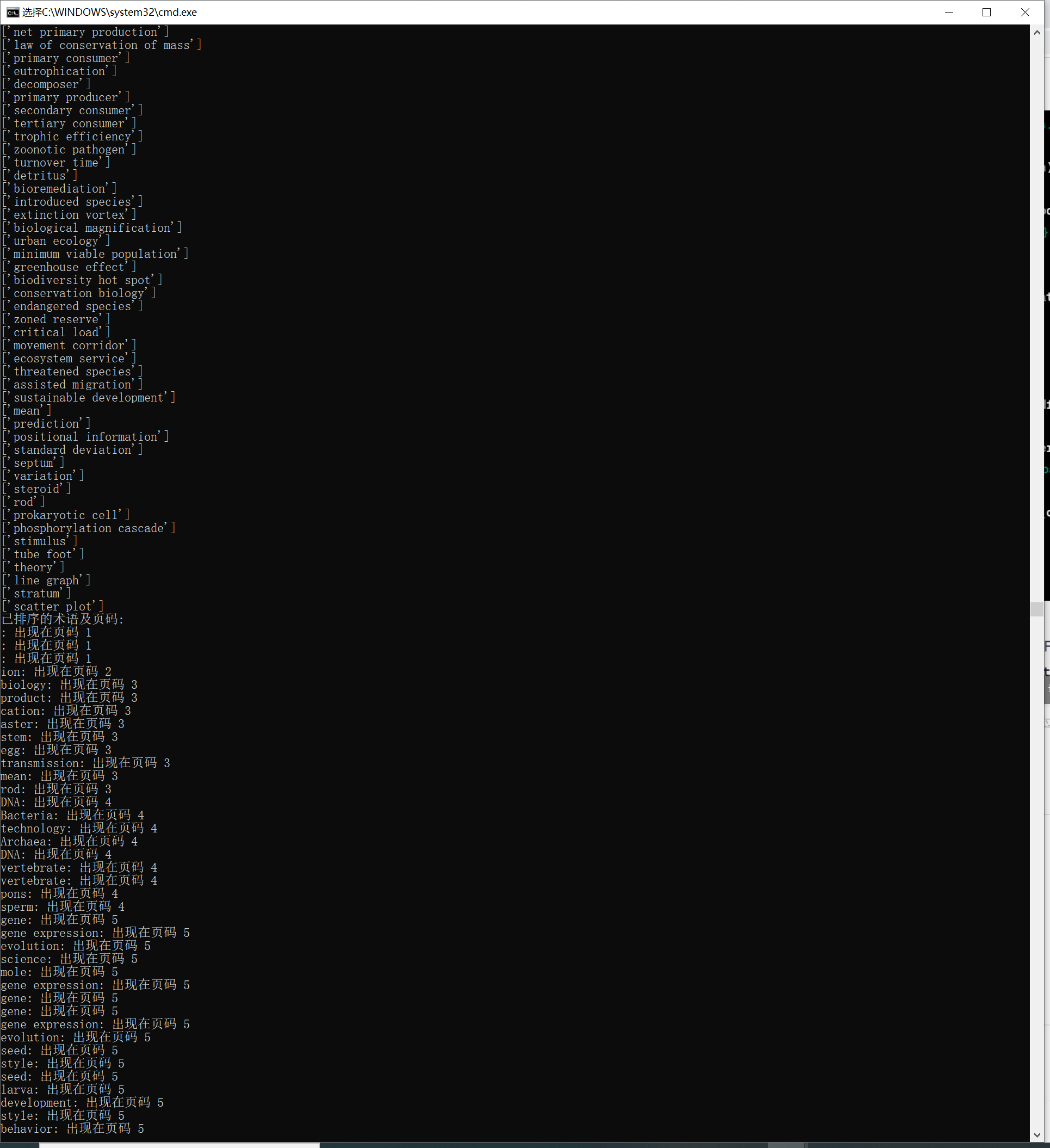
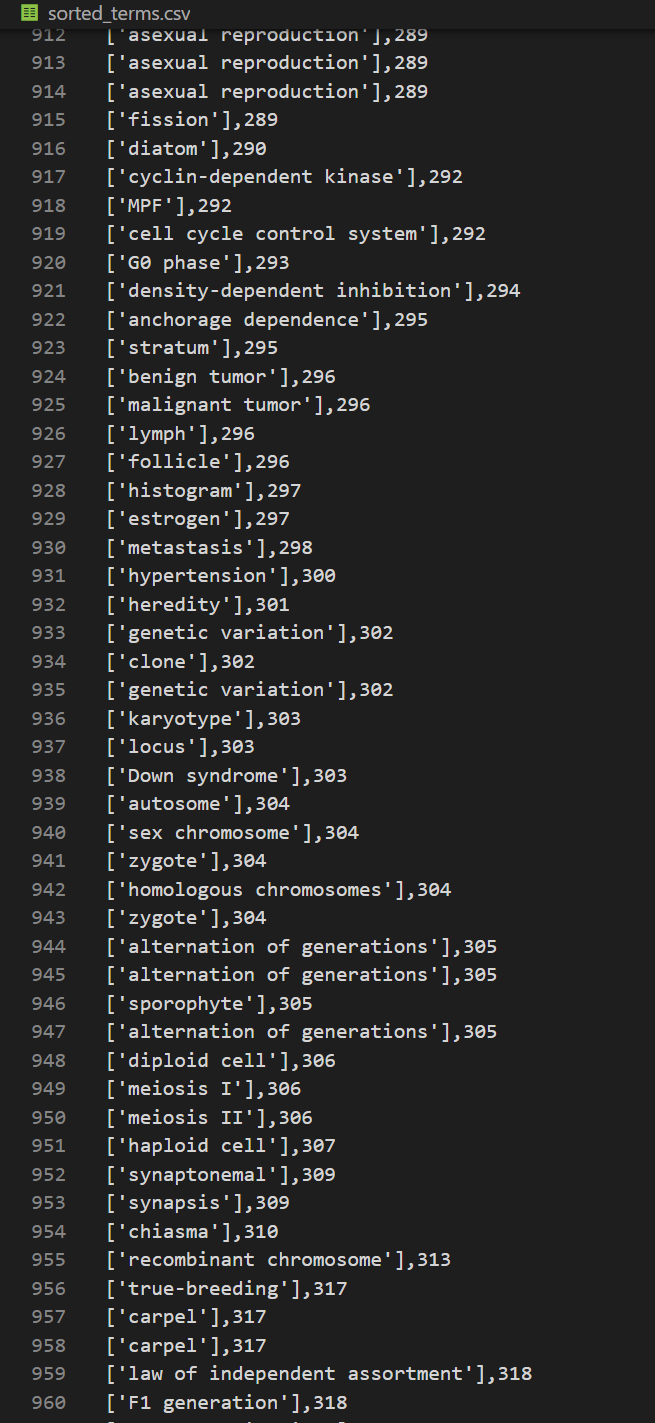
我有下面一个生物学术语表文件,大概2000多个术语,我希望能按照它在某本生物学教科书中出现的顺序重新排序这个术语表,并给出术语出现的页码。
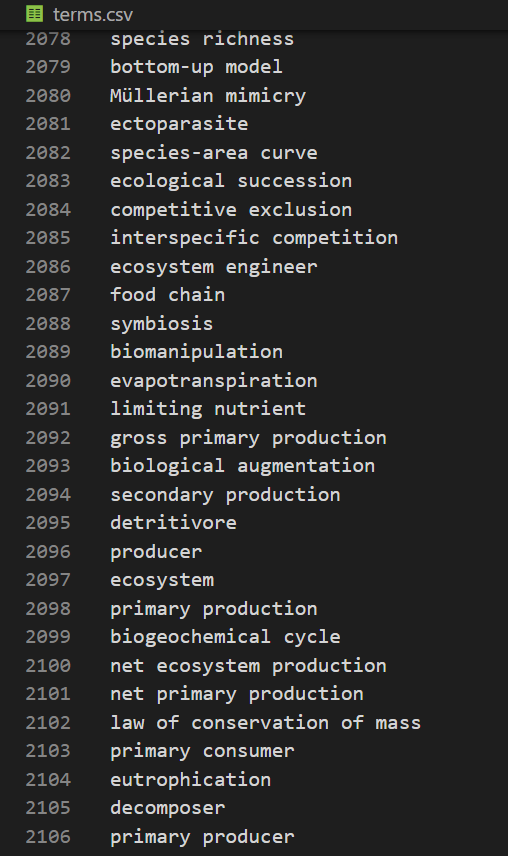

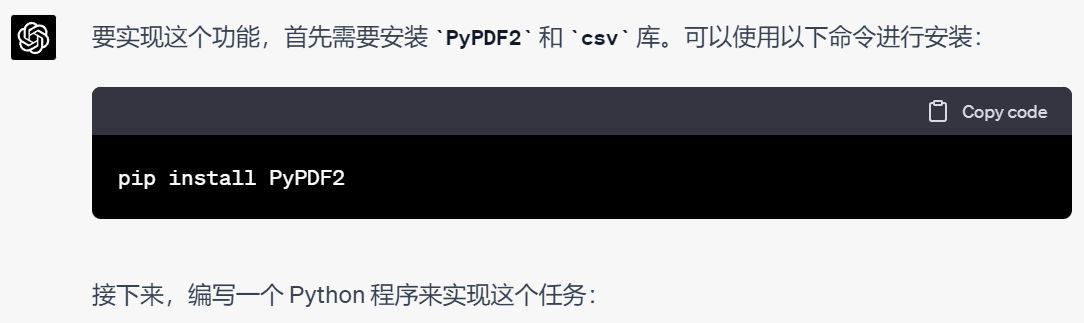
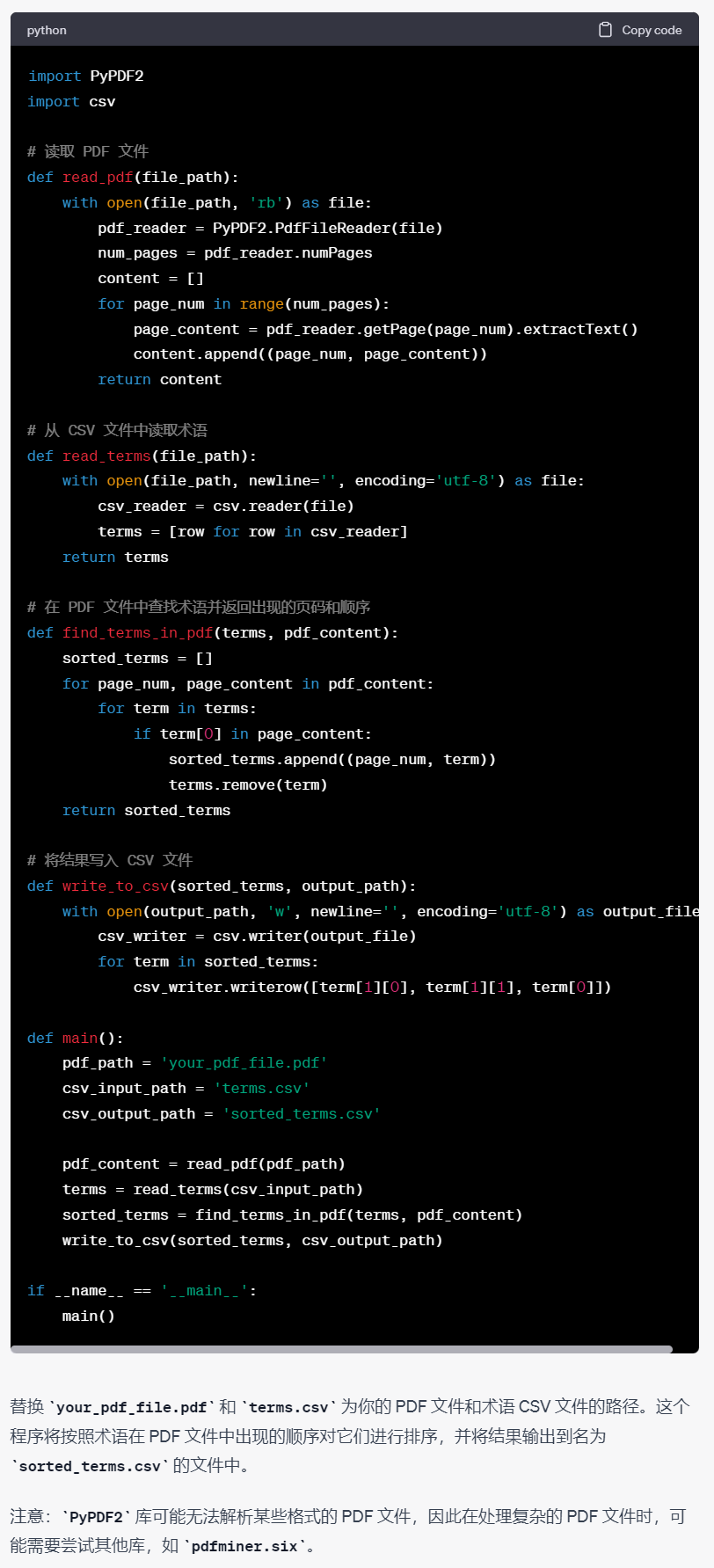
我们把文件名重新改一下,用Anaconada里面虚拟环境Python跑一下,当然,跑之前需要先按提示把缺的那个PDF读取库安装一下,具体不再赘述。
但是很不幸运,第一次跑出来控制台报告了一系列错误,我们把错误直接完整拷贝发送给ChatGPT,不需要再给他代码,因为它知道上一次的代码是怎样的,它给出了解决方案:
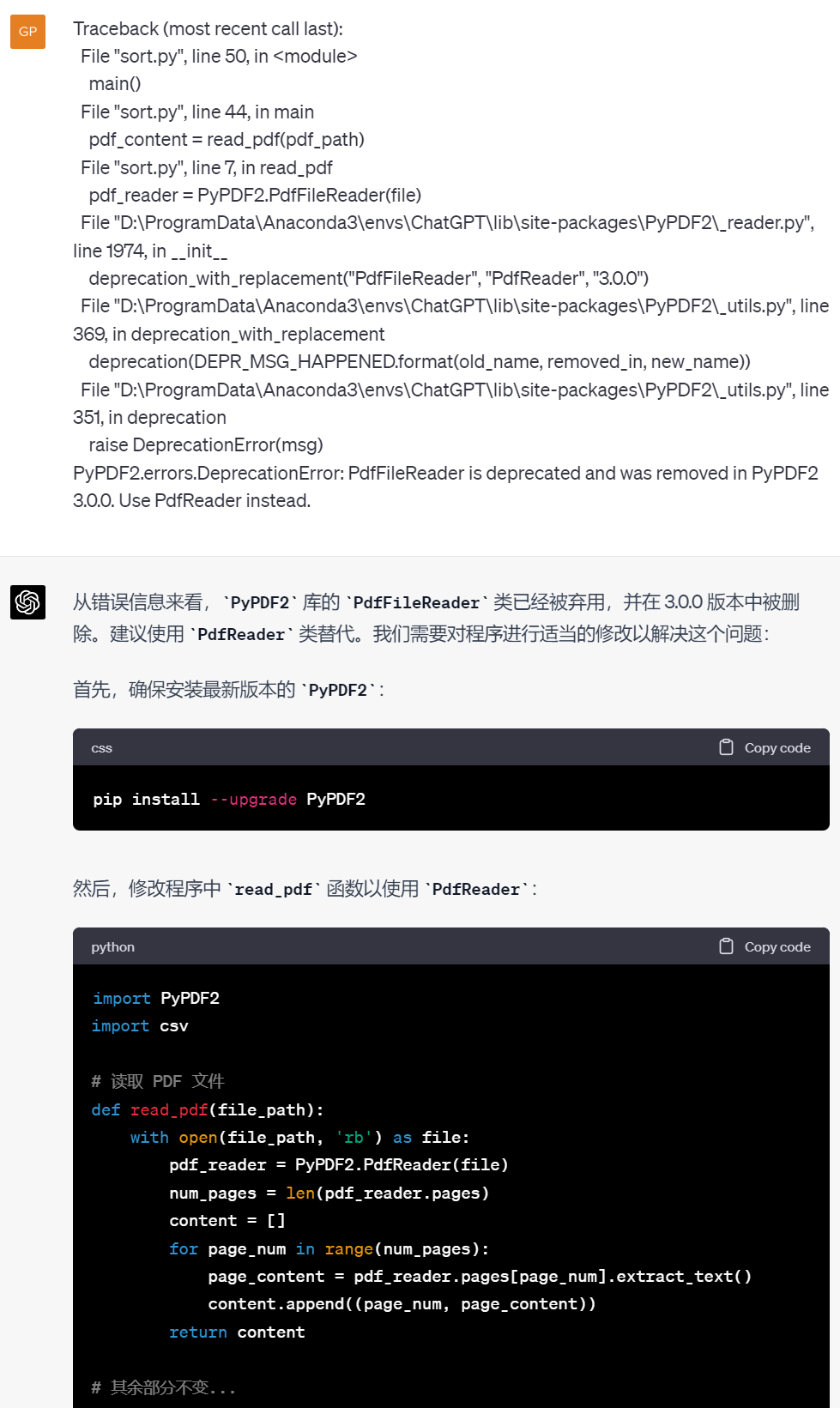
这次倒是能跑了,生成的文件内容空白,但是由于术语表有2000多个术语,而PDF文件又是1600多页图文并茂的文件,所以控制台不打印任何东西,长期卡顿无反应我们也不知道到底发生了什么。虽然类Unix系统的哲学是没返回就是最好的结果。于是这时,我请求ChatGPT添加一些代码,打印中间过程,好让我知道程序一直在工作,并且工作到哪里了。
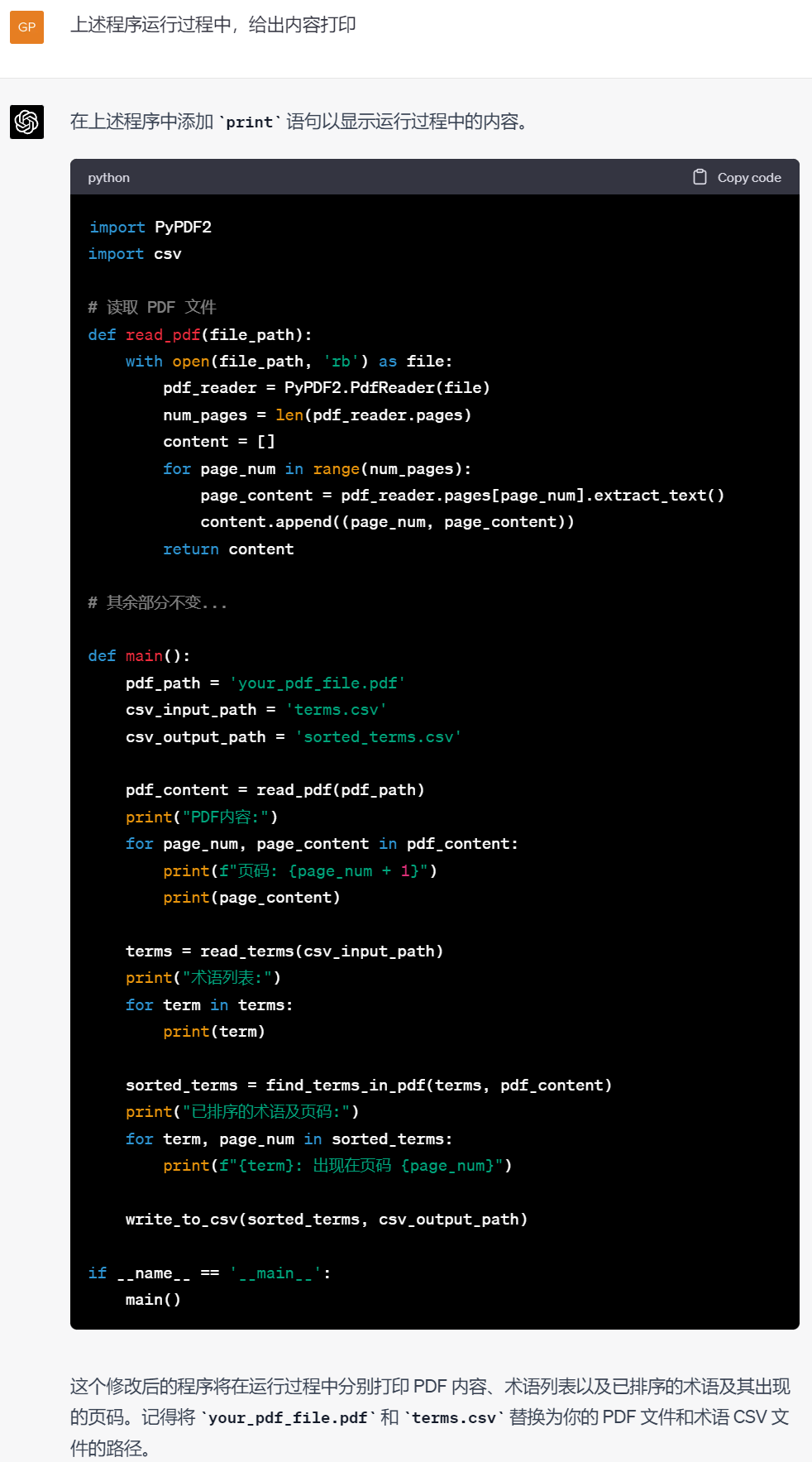
这次总算是基本成功了,而且生成的文件里面也有了我需要的相应内容,下一步简单处理一下即可满足我下一步的需求。
<hr/>总结 |



