由此可见,FrameExit框架如其名,是一种基于“条件化提前退出(Conditional Early Exiting)策略”的框架;是将简单的采样策略与提前阻断任务的动态门控策略相结合的方案;早期主要用于优化视频识别场景,可以用较少的frame处理简单视频,用更多的frame处理更复杂的视频;实现这个策略的目的是让更大场景的视频任务能够应用在资源有限的硬件上。如今应该已经适配多模态任务。
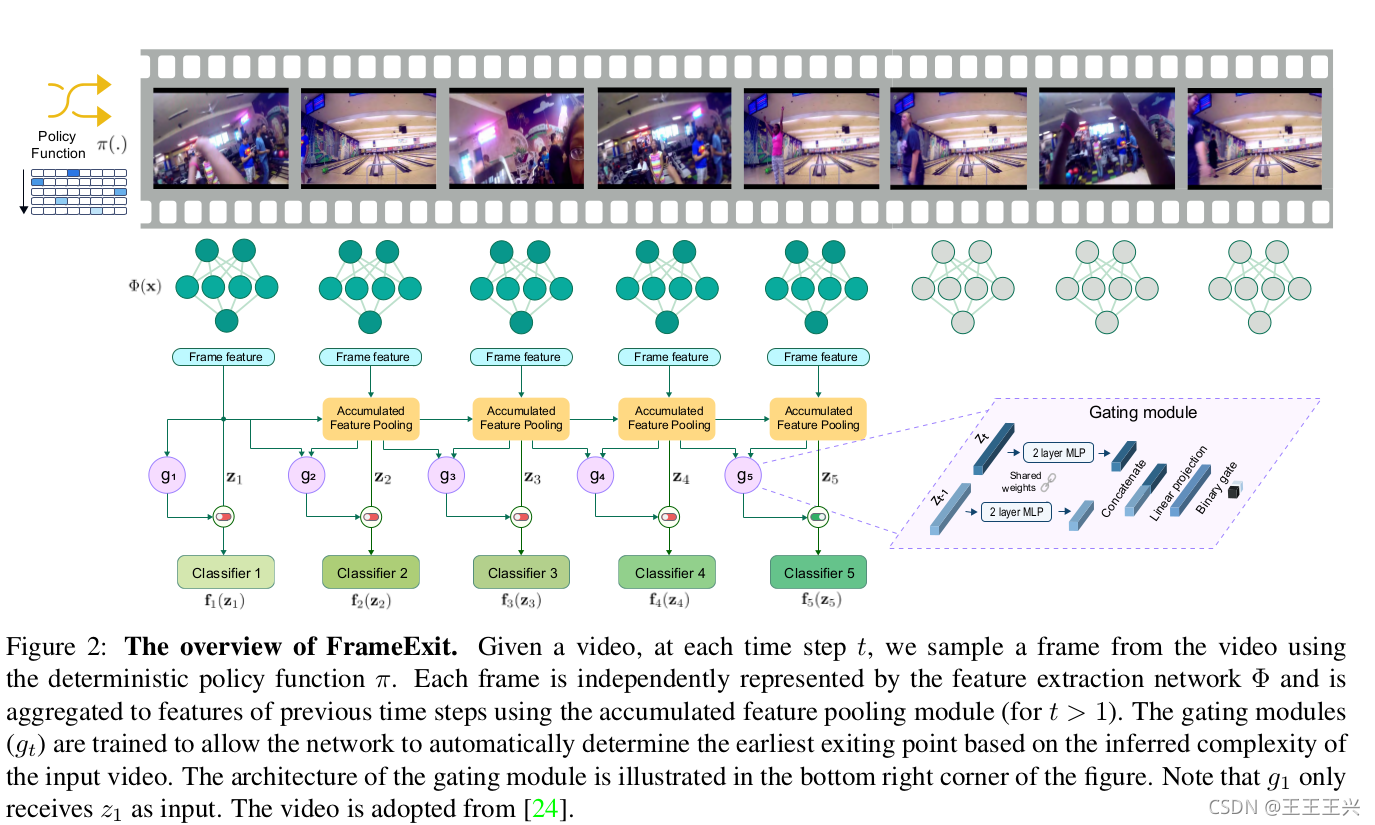
原理如下图示;FrameExit的原理就是用多个级联的门控模块来动态平衡推理任务中的负载(Accu% & Cost%),通过在整个网络中插入一连串的中间分类器/编排器(orchestrator)来动态的、策略性发现图像分类任务的“可以提前退出的最佳节点”,即这组级联的门控策略来确定何时停止对视频输入任务的进一步处理;模型根据输入的复杂度来动态调整计算量。其中的Gating Module是可以学习的,当推理进行的足够可靠或是满足策略条件时,它就会决定停止计算。每个orchestrator都对应一个关联的门策略,这些门在不同的时间步长连接以便允许提前退出任务(门会延迟启动,以便在最后一级分类器上完成分类,以便获得最大的识别准确度)。
Gating Module是以自监督的方式学习,学习目的是动态评估和控制模型输出精度与总计算开销之间的平衡。门的学习过程是分别利用一个损失函数来优化特征提取器网络和orchestrator的参数,以及另一个损失函数来构成门控策略(识别并生成动态伪标签来训练门),见原作论文。
另外,FrameExit 论文也提出了一个“累积特征池模块”来生成视频表示,使模型用于自我迭代以便持续进行更可靠的预测。以上都是2021年的论文解释,如今应该已经适配多模态任务。
FrameExit的级联分类器及其逐一对应的门控策略的运行原理
关于FrameExit的级联分类器及其逐一对应的门控策略的运行原理,参考如下的Paper和代码:
FrameExit: Conditional Early Exiting for Efficient Video Recognitionhttps://github.com/Qualcomm-AI-research/FrameExit除了伴随Hexagon加速器发布的FrameExit框架,作为完整AI软件栈的其它部分,QCom也发布了开发环境和工具链,包括推理开发包QNN SDK、AP硬件驱动程序、虚拟化平台和编译器,以及主流的NN框架(TensorFlow/PyTorch/ONNX/Keras等),以及包括TensorFlow Lite/Micro和ONNX Runtime等在内的Runtime等等。下游主机厂商可以根据机器的外设特性、OS特性、用户富媒体资源的特性以及云服务等方面,基于这些工具链来设计并部署大模型在端云两侧,可以快速交付服务,并可以基于用户数据和新场景持续做迭代。