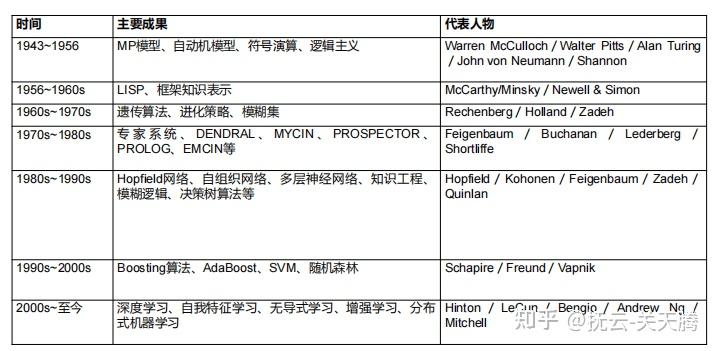
图像识别、文本分析:神经网络和深度学习、多层前馈神经网络常见的深度学习神经网络卷积神经网络循环神经网络
神经网络:传统的神经网络为BP神经网络,基本网络结构为输入层、隐藏层和输出层,节点代表神经元,边代表权重值,对输入值按照权重和偏置计算后将结果传给下一层,通过不断的训练修正权重和偏置。递归神经网络(RNN)、卷积神经网络(CNN)都在神经网络在深度学习上的变种。神经网络的训练主要包括前向传输和反向传播。神经网络的结果准确性与训练集的样本数量和分类质量有关。神经网络是基于历史数据构建的分析模型,新数据产生时需要动态优化网络的结构和参数。深度学习:深度学习是通过构建多个隐藏层和大量数据来学习特征,从而提升分类或预测的准确性。与神经网络相比,层数更多,而且有逐层训练机制避免梯度扩散。深度学习包括了卷积神经网络(CNN)、深度神经网络(DNN)、循环神经网络(RNN)、对抗神经网络(GAN) 深度学习中训练集、开发集、测试集的样本比例一般为6:2:2。 常见的权重更新方式包括SGD和Momentum |
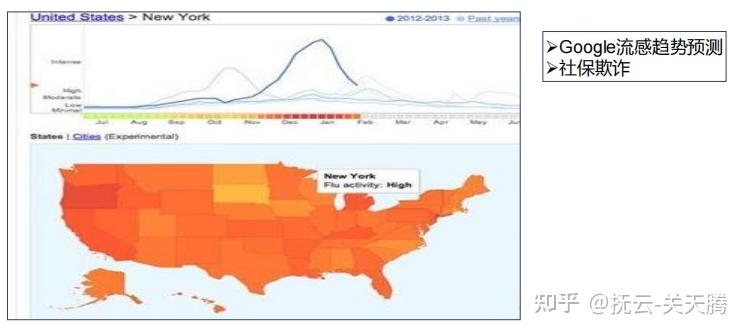
淘宝潜在用户分析、社交网络用户分析:聚类算法
聚类分析是把一个给定的数据对象(样本H集合分成不同的簇(组)。聚类就是把整个数据分成不同的组T并使组与组之间的差距尽可大,组内数据的差异尽可能小。K-means是一种常用的聚类算法,用户指定聚类的类别数K ,随机地选择K个对象作为K个初始聚类中心。对剩余的每个对象,分别计算与初始聚类中心的距离,根据距离划到不同的簇。然后重新计算每个簇的平均值,求出新的聚类中心,再重新聚类。这个过程不断重复,直到收敛(相邻两次计算的聚类中心相同)。聚类是基于无监督学习的分类模型,按照数据内在结构特征进行聚集形成簇群。聚集方法即记录之间的区分规则。聚类与分类的主要区别是其不关心数据的类别。聚类首先选择有效特征向量,然后按照距离函数进行相似度计算。聚类应用广泛:客户群体特征、消费者行为分析、市场细分、交易数据分析、动植物种群分类、医疗领域的疾病诊断、环境质量检测。常见的聚类方法:基于层次聚类(Hierarchical METHod) BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies) CURE(Clustering Using Representatives) 基于划分的聚类K均值(K-Means) 基于密度的聚类DBSCAN(Density-based spatial clustering of applications with noise) OPTICS(Ordering Points To Identify the Clustering Structure) 基于机器学习的聚类·基于约束的聚类·基于网络的聚类 |
商品、新闻、APP、专家、影视、音乐等推荐:推荐算法
为应对网络信息的爆炸,电子推荐系统提供一种特定的信息过滤技术,预测和展示用户可能感兴趣的商品,从而节省了用户的时间。推荐系统采用一种或者组合多种推荐方法,对用户偏好的输入数据进行处理,找出用户可能感兴趣的信息或者商品进行推荐。基于内容的推荐:需要把握用户的偏好特征,通常可以分析用户浏览过的内容,从中抽取重要的关键词,并利用文献检索的方法。然后计算商品的描述特征向量与用户的特征向量的相似程度,对候选的信息或商品集合进行过滤,产生用户可能感兴趣的推荐列表。基于协同过滤的推荐:找出与用户偏好相似的用户邻居集合,把邻居集的偏好商品集作为推荐的候选。此外,也可以寻找用户以前的偏好信息或商品的相似项目集合推荐。 |
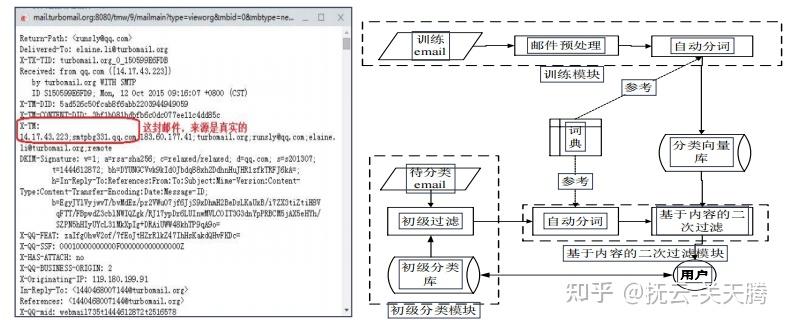
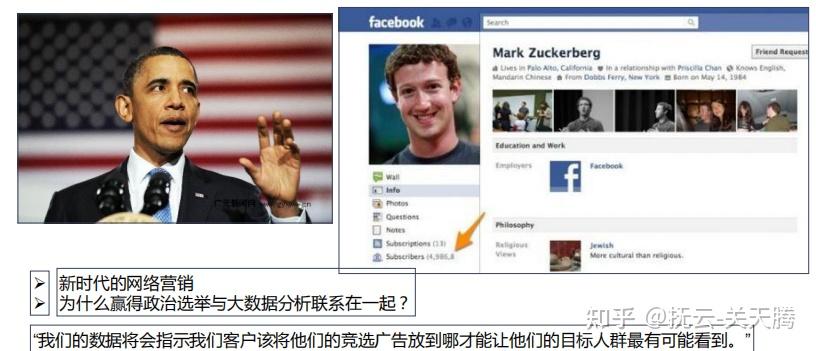
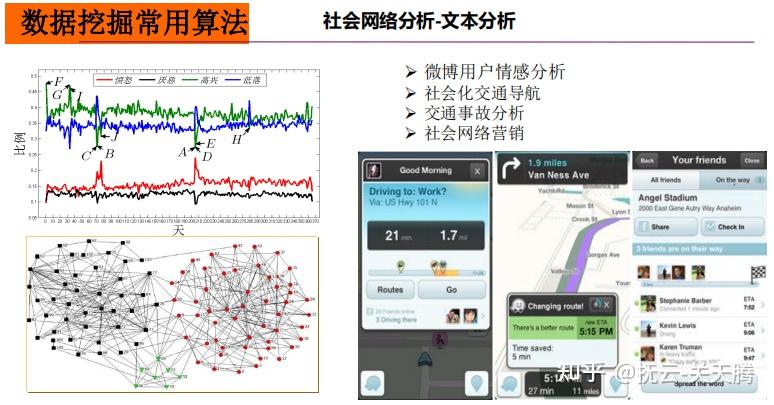
| 社会网络分析:文本分析 ;微博用户情感分析、社会化交通导航、交通事故分析、社会网络营销 |
关联分析
关联分析(Associative Analysis )通过对数据集中某些属性同时出现的规律和模式来发现其中的属性间的关联、相关、因果等关系,典型应用是购物篮分析。关联分析包括Apriori算法和FP-Growth算法。Apriori 算法的基本思想是先找出所有的频繁项集,然后由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。 算法要多次扫描样本集,需要由候选频繁项集生成频繁项集。 FP-Growth算法是基于FP树生成频繁项集的,算法只扫描两次数据集,且不使用候选项集,直接按照支持度构造出一个频繁模式树,用这棵树生成关联规则。关联分析已经在客户购物行为分析、电子推荐、产品质量检测、文档主题分析等得到了广泛应用。 |